 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDream: Exchanging dreams instead of models for federated aggregation with heterogeneous models
Feb 27, 2024Federated Learning (FL) enables collaborative optimization of machine learning models across decentralized data by aggregating model parameters. Our approach extends this concept by aggregating "knowledge" derived from models, instead of model parameters. We present a novel framework called CoDream, where clients collaboratively optimize randomly initialized data using federated optimization in the input data space, similar to how randomly initialized model parameters are optimized in FL. Our key insight is that jointly optimizing this data can effectively capture the properties of the global data distribution. Sharing knowledge in data space offers numerous benefits: (1) model-agnostic collaborative learning, i.e., different clients can have different model architectures; (2) communication that is independent of the model size, eliminating scalability concerns with model parameters; (3) compatibility with secure aggregation, thus preserving the privacy benefits of federated learning; (4) allowing of adaptive optimization of knowledge shared for personalized learning. We empirically validate CoDream on standard FL tasks, demonstrating competitive performance despite not sharing model parameters. Our code: https://mitmedialab.github.io/codream.github.io/
Can Self Reported Symptoms Predict Daily COVID-19 Cases?
May 18, 2021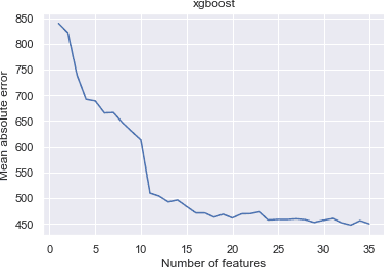
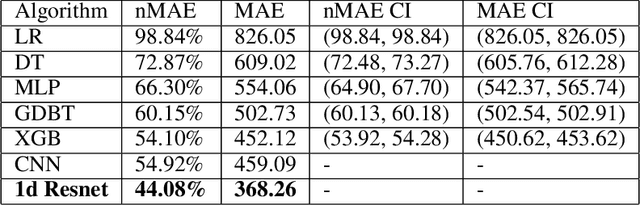
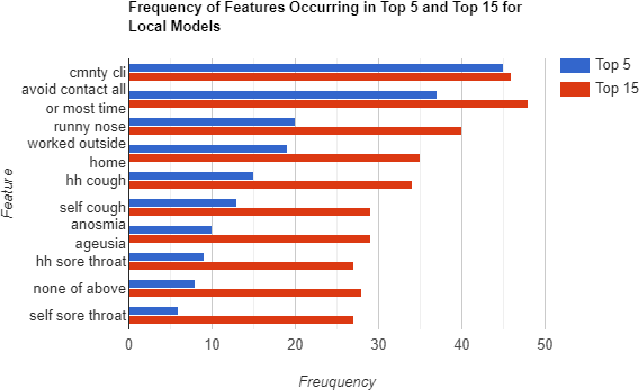

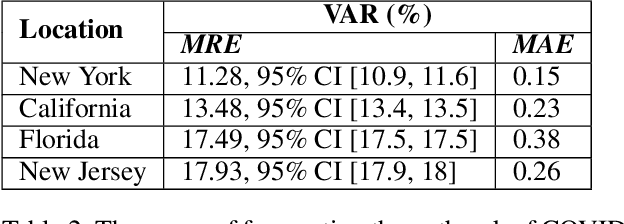
The COVID-19 pandemic has impacted lives and economies across the globe, leading to many deaths. While vaccination is an important intervention, its roll-out is slow and unequal across the globe. Therefore, extensive testing still remains one of the key methods to monitor and contain the virus. Testing on a large scale is expensive and arduous. Hence, we need alternate methods to estimate the number of cases. Online surveys have been shown to be an effective method for data collection amidst the pandemic. In this work, we develop machine learning models to estimate the prevalence of COVID-19 using self-reported symptoms. Our best model predicts the daily cases with a mean absolute error (MAE) of 226.30 (normalized MAE of 27.09%) per state, which demonstrates the possibility of predicting the actual number of confirmed cases by utilizing self-reported symptoms. The models are developed at two levels of data granularity - local models, which are trained at the state level, and a single global model which is trained on the combined data aggregated across all states. Our results indicate a lower error on the local models as opposed to the global model. In addition, we also show that the most important symptoms (features) vary considerably from state to state. This work demonstrates that the models developed on crowd-sourced data, curated via online platforms, can complement the existing epidemiological surveillance infrastructure in a cost-effective manner.
COVID-19 Outbreak Prediction and Analysis using Self Reported Symptoms
Dec 21, 2020
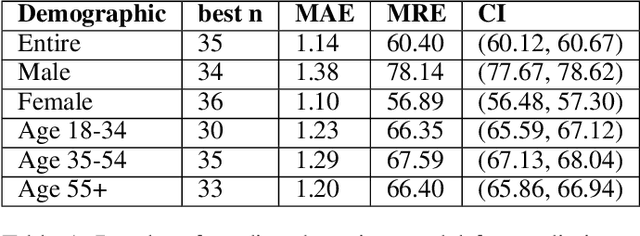
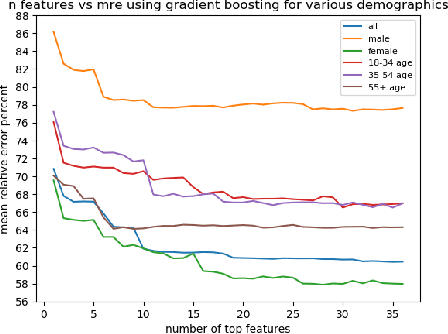
The COVID-19 pandemic has challenged scientists and policy-makers internationally to develop novel approaches to public health policy. Furthermore, it has also been observed that the prevalence and spread of COVID-19 vary across different spatial, temporal, and demographics. Despite ramping up testing, we still are not at the required level in most parts of the globe. Therefore, we utilize self-reported symptoms survey data to understand trends in the spread of COVID-19. The aim of this study is to segment populations that are highly susceptible. In order to understand such populations, we perform exploratory data analysis, outbreak prediction, and time-series forecasting using public health and policy datasets. From our studies, we try to predict the likely % of the population that tested positive for COVID-19 based on self-reported symptoms. Our findings reaffirm the predictive value of symptoms, such as anosmia and ageusia. And we forecast that % of the population having COVID-19-like illness (CLI) and those tested positive as 0.15% and 1.14% absolute error respectively. These findings could help aid faster development of the public health policy, particularly in areas with low levels of testing and having a greater reliance on self-reported symptoms. Our analysis sheds light on identifying clinical attributes of interest across different demographics. We also provide insights into the effects of various policy enactments on COVID-19 prevalence.
Proximity Sensing for Contact Tracing
Sep 04, 2020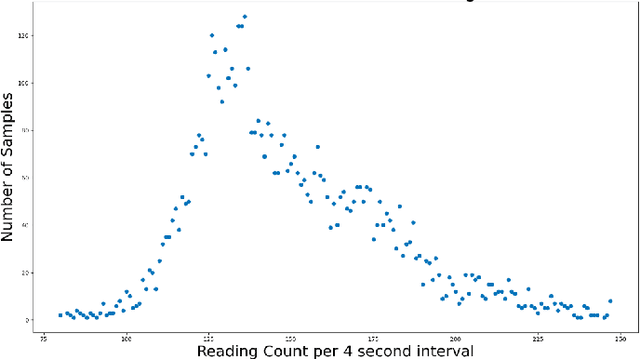
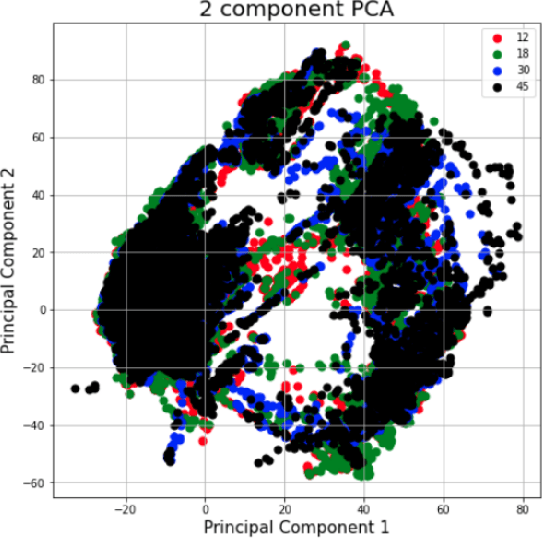

The TC4TL (Too Close For Too Long) challenge is aimed towards designing an effective proximity sensing algorithm that can accurately provide exposure notifications. In this paper, we describe our approach to model sensor and other device-level data to estimate the distance between two phones. We also present our research and data analysis on the TC4TL challenge and discuss various limitations associated with the task, and the dataset used for this purpose.