 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffense Detection in Dravidian Languages using Code-Mixing Index based Focal Loss
Nov 12, 2021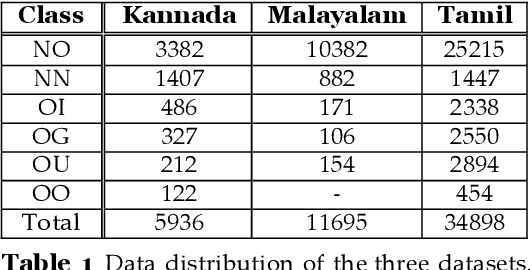
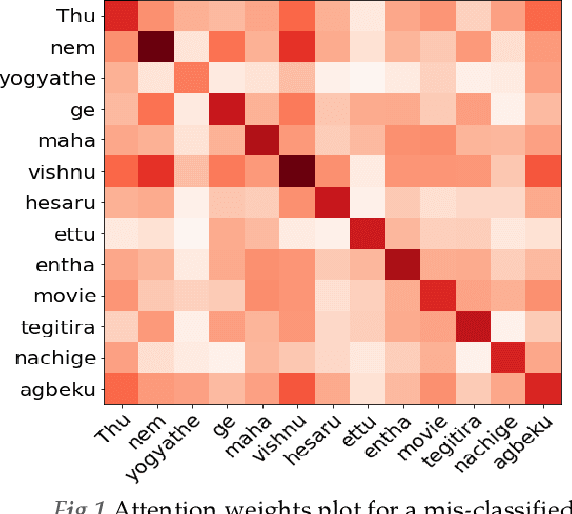
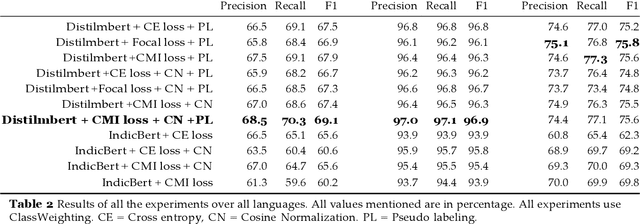
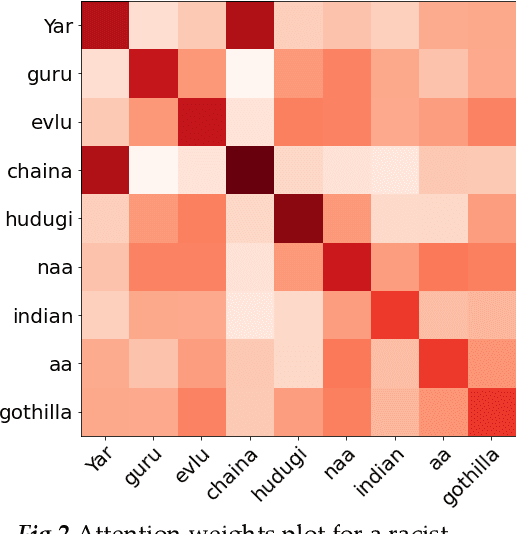
Over the past decade, we have seen exponential growth in online content fueled by social media platforms. Data generation of this scale comes with the caveat of insurmountable offensive content in it. The complexity of identifying offensive content is exacerbated by the usage of multiple modalities (image, language, etc.), code mixed language and more. Moreover, even if we carefully sample and annotate offensive content, there will always exist significant class imbalance in offensive vs non offensive content. In this paper, we introduce a novel Code-Mixing Index (CMI) based focal loss which circumvents two challenges (1) code mixing in languages (2) class imbalance problem for Dravidian language offense detection. We also replace the conventional dot product-based classifier with the cosine-based classifier which results in a boost in performance. Further, we use multilingual models that help transfer characteristics learnt across languages to work effectively with low resourced languages. It is also important to note that our model handles instances of mixed script (say usage of Latin and Dravidian - Tamil script) as well. Our model can handle offensive language detection in a low-resource, class imbalanced, multilingual and code mixed setting.
Can Self Reported Symptoms Predict Daily COVID-19 Cases?
May 18, 2021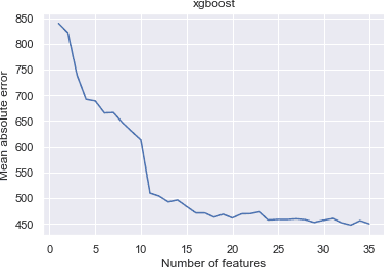
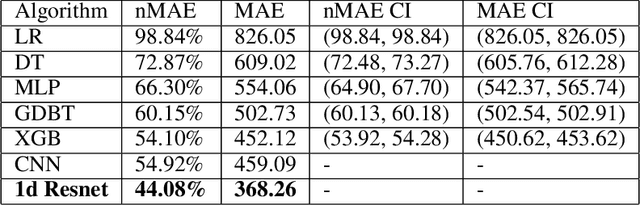
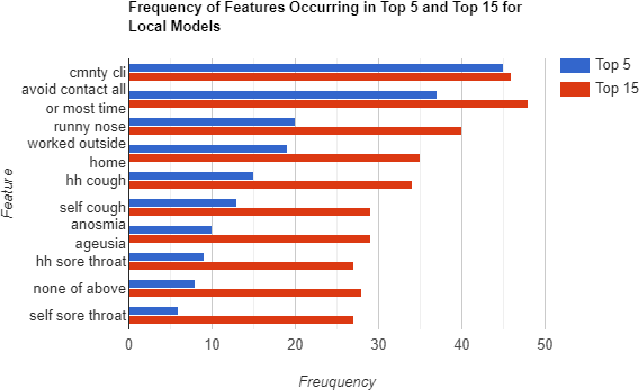

The COVID-19 pandemic has impacted lives and economies across the globe, leading to many deaths. While vaccination is an important intervention, its roll-out is slow and unequal across the globe. Therefore, extensive testing still remains one of the key methods to monitor and contain the virus. Testing on a large scale is expensive and arduous. Hence, we need alternate methods to estimate the number of cases. Online surveys have been shown to be an effective method for data collection amidst the pandemic. In this work, we develop machine learning models to estimate the prevalence of COVID-19 using self-reported symptoms. Our best model predicts the daily cases with a mean absolute error (MAE) of 226.30 (normalized MAE of 27.09%) per state, which demonstrates the possibility of predicting the actual number of confirmed cases by utilizing self-reported symptoms. The models are developed at two levels of data granularity - local models, which are trained at the state level, and a single global model which is trained on the combined data aggregated across all states. Our results indicate a lower error on the local models as opposed to the global model. In addition, we also show that the most important symptoms (features) vary considerably from state to state. This work demonstrates that the models developed on crowd-sourced data, curated via online platforms, can complement the existing epidemiological surveillance infrastructure in a cost-effective manner.