 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs it an i or an l: Test-time Adaptation of Text Line Recognition Models
Aug 29, 2023



Recognizing text lines from images is a challenging problem, especially for handwritten documents due to large variations in writing styles. While text line recognition models are generally trained on large corpora of real and synthetic data, such models can still make frequent mistakes if the handwriting is inscrutable or the image acquisition process adds corruptions, such as noise, blur, compression, etc. Writing style is generally quite consistent for an individual, which can be leveraged to correct mistakes made by such models. Motivated by this, we introduce the problem of adapting text line recognition models during test time. We focus on a challenging and realistic setting where, given only a single test image consisting of multiple text lines, the task is to adapt the model such that it performs better on the image, without any labels. We propose an iterative self-training approach that uses feedback from the language model to update the optical model, with confident self-labels in each iteration. The confidence measure is based on an augmentation mechanism that evaluates the divergence of the prediction of the model in a local region. We perform rigorous evaluation of our method on several benchmark datasets as well as their corrupted versions. Experimental results on multiple datasets spanning multiple scripts show that the proposed adaptation method offers an absolute improvement of up to 8% in character error rate with just a few iterations of self-training at test time.
Target Aware Network Architecture Search and Compression for Efficient Knowledge Transfer
May 12, 2022
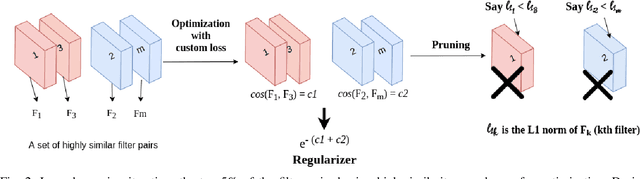

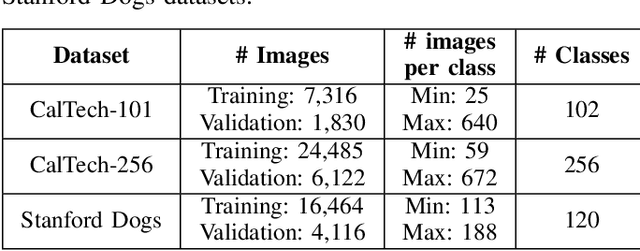
Transfer Learning enables Convolutional Neural Networks (CNN) to acquire knowledge from a source domain and transfer it to a target domain, where collecting large-scale annotated examples is both time-consuming and expensive. Conventionally, while transferring the knowledge learned from one task to another task, the deeper layers of a pre-trained CNN are finetuned over the target dataset. However, these layers that are originally designed for the source task are over-parameterized for the target task. Thus, finetuning these layers over the target dataset reduces the generalization ability of the CNN due to high network complexity. To tackle this problem, we propose a two-stage framework called TASCNet which enables efficient knowledge transfer. In the first stage, the configuration of the deeper layers is learned automatically and finetuned over the target dataset. Later, in the second stage, the redundant filters are pruned from the fine-tuned CNN to decrease the network's complexity for the target task while preserving the performance. This two-stage mechanism finds a compact version of the pre-trained CNN with optimal structure (number of filters in a convolutional layer, number of neurons in a dense layer, and so on) from the hypothesis space. The efficacy of the proposed method is evaluated using VGG-16, ResNet-50, and DenseNet-121 on CalTech-101, CalTech-256, and Stanford Dogs datasets. The proposed TASCNet reduces the computational complexity of pre-trained CNNs over the target task by reducing both trainable parameters and FLOPs which enables resource-efficient knowledge transfer.
Offense Detection in Dravidian Languages using Code-Mixing Index based Focal Loss
Nov 12, 2021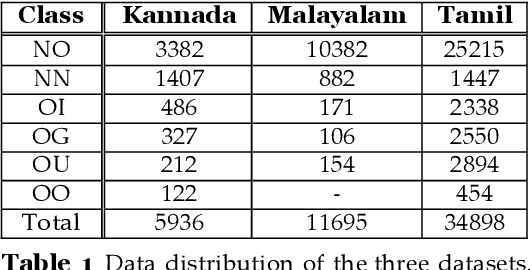
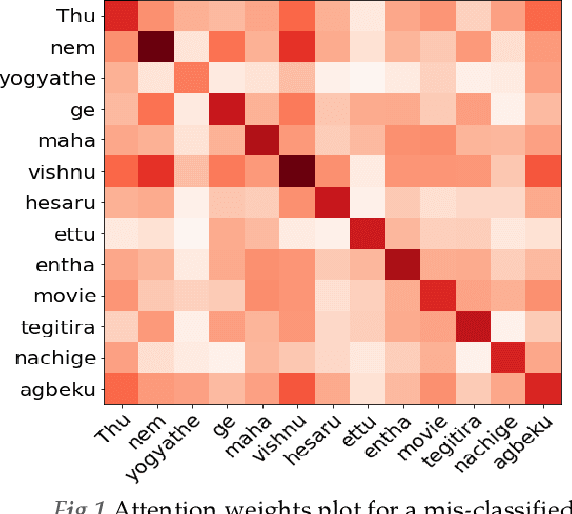
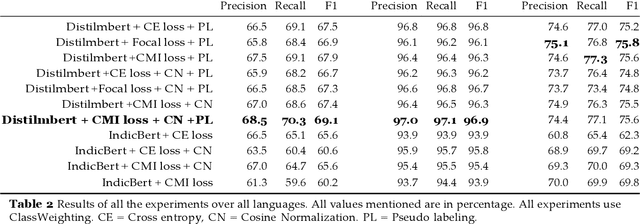
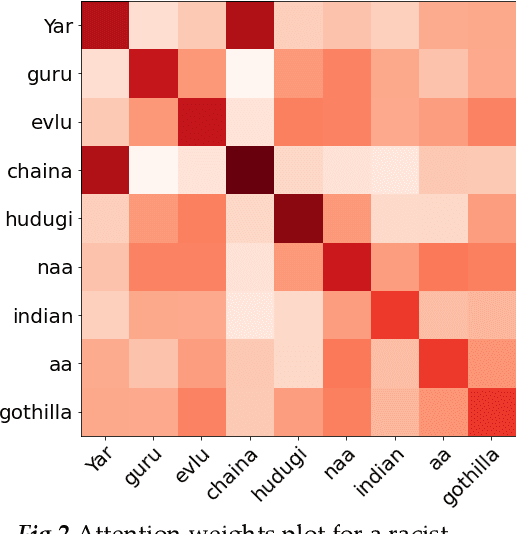
Over the past decade, we have seen exponential growth in online content fueled by social media platforms. Data generation of this scale comes with the caveat of insurmountable offensive content in it. The complexity of identifying offensive content is exacerbated by the usage of multiple modalities (image, language, etc.), code mixed language and more. Moreover, even if we carefully sample and annotate offensive content, there will always exist significant class imbalance in offensive vs non offensive content. In this paper, we introduce a novel Code-Mixing Index (CMI) based focal loss which circumvents two challenges (1) code mixing in languages (2) class imbalance problem for Dravidian language offense detection. We also replace the conventional dot product-based classifier with the cosine-based classifier which results in a boost in performance. Further, we use multilingual models that help transfer characteristics learnt across languages to work effectively with low resourced languages. It is also important to note that our model handles instances of mixed script (say usage of Latin and Dravidian - Tamil script) as well. Our model can handle offensive language detection in a low-resource, class imbalanced, multilingual and code mixed setting.