 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaliGemma 2: A Family of Versatile VLMs for Transfer
Dec 04, 2024



PaliGemma 2 is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. We combine the SigLIP-So400m vision encoder that was also used by PaliGemma with the whole range of Gemma 2 models, from the 2B one all the way up to the 27B model. We train these models at three resolutions (224px, 448px, and 896px) in multiple stages to equip them with broad knowledge for transfer via fine-tuning. The resulting family of base models covering different model sizes and resolutions allows us to investigate factors impacting transfer performance (such as learning rate) and to analyze the interplay between the type of task, model size, and resolution. We further increase the number and breadth of transfer tasks beyond the scope of PaliGemma including different OCR-related tasks such as table structure recognition, molecular structure recognition, music score recognition, as well as long fine-grained captioning and radiography report generation, on which PaliGemma 2 obtains state-of-the-art results.
Is it an i or an l: Test-time Adaptation of Text Line Recognition Models
Aug 29, 2023



Recognizing text lines from images is a challenging problem, especially for handwritten documents due to large variations in writing styles. While text line recognition models are generally trained on large corpora of real and synthetic data, such models can still make frequent mistakes if the handwriting is inscrutable or the image acquisition process adds corruptions, such as noise, blur, compression, etc. Writing style is generally quite consistent for an individual, which can be leveraged to correct mistakes made by such models. Motivated by this, we introduce the problem of adapting text line recognition models during test time. We focus on a challenging and realistic setting where, given only a single test image consisting of multiple text lines, the task is to adapt the model such that it performs better on the image, without any labels. We propose an iterative self-training approach that uses feedback from the language model to update the optical model, with confident self-labels in each iteration. The confidence measure is based on an augmentation mechanism that evaluates the divergence of the prediction of the model in a local region. We perform rigorous evaluation of our method on several benchmark datasets as well as their corrupted versions. Experimental results on multiple datasets spanning multiple scripts show that the proposed adaptation method offers an absolute improvement of up to 8% in character error rate with just a few iterations of self-training at test time.
OCR Language Models with Custom Vocabularies
Aug 18, 2023Language models are useful adjuncts to optical models for producing accurate optical character recognition (OCR) results. One factor which limits the power of language models in this context is the existence of many specialized domains with language statistics very different from those implied by a general language model - think of checks, medical prescriptions, and many other specialized document classes. This paper introduces an algorithm for efficiently generating and attaching a domain specific word based language model at run time to a general language model in an OCR system. In order to best use this model the paper also introduces a modified CTC beam search decoder which effectively allows hypotheses to remain in contention based on possible future completion of vocabulary words. The result is a substantial reduction in word error rate in recognizing material from specialized domains.
XTREME-UP: A User-Centric Scarce-Data Benchmark for Under-Represented Languages
May 24, 2023



Data scarcity is a crucial issue for the development of highly multilingual NLP systems. Yet for many under-represented languages (ULs) -- languages for which NLP re-search is particularly far behind in meeting user needs -- it is feasible to annotate small amounts of data. Motivated by this, we propose XTREME-UP, a benchmark defined by: its focus on the scarce-data scenario rather than zero-shot; its focus on user-centric tasks -- tasks with broad adoption by speakers of high-resource languages; and its focus on under-represented languages where this scarce-data scenario tends to be most realistic. XTREME-UP evaluates the capabilities of language models across 88 under-represented languages over 9 key user-centric technologies including ASR, OCR, MT, and information access tasks that are of general utility. We create new datasets for OCR, autocomplete, semantic parsing, and transliteration, and build on and refine existing datasets for other tasks. XTREME-UP provides methodology for evaluating many modeling scenarios including text-only, multi-modal (vision, audio, and text),supervised parameter tuning, and in-context learning. We evaluate commonly used models on the benchmark. We release all code and scripts to train and evaluate models
Rethinking Text Line Recognition Models
Apr 21, 2021
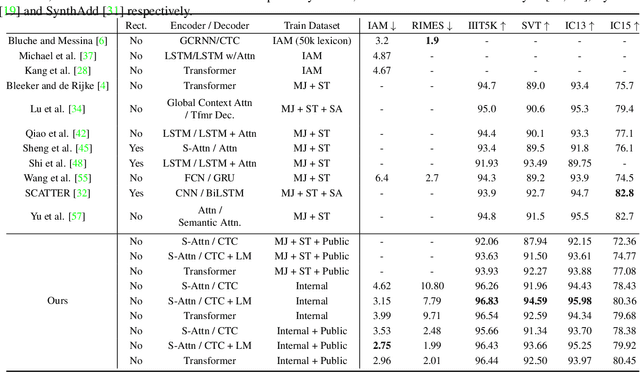

In this paper, we study the problem of text line recognition. Unlike most approaches targeting specific domains such as scene-text or handwritten documents, we investigate the general problem of developing a universal architecture that can extract text from any image, regardless of source or input modality. We consider two decoder families (Connectionist Temporal Classification and Transformer) and three encoder modules (Bidirectional LSTMs, Self-Attention, and GRCLs), and conduct extensive experiments to compare their accuracy and performance on widely used public datasets of scene and handwritten text. We find that a combination that so far has received little attention in the literature, namely a Self-Attention encoder coupled with the CTC decoder, when compounded with an external language model and trained on both public and internal data, outperforms all the others in accuracy and computational complexity. Unlike the more common Transformer-based models, this architecture can handle inputs of arbitrary length, a requirement for universal line recognition. Using an internal dataset collected from multiple sources, we also expose the limitations of current public datasets in evaluating the accuracy of line recognizers, as the relatively narrow image width and sequence length distributions do not allow to observe the quality degradation of the Transformer approach when applied to the transcription of long lines.