 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Text Spotter for Joint Text Spotting and Layout Analysis
Oct 25, 2023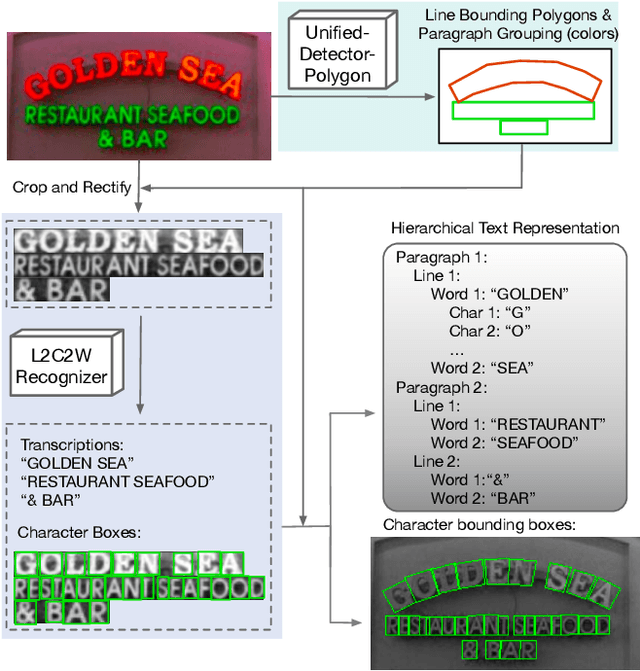
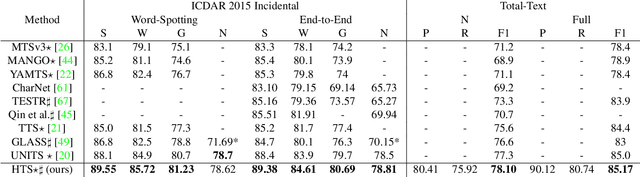
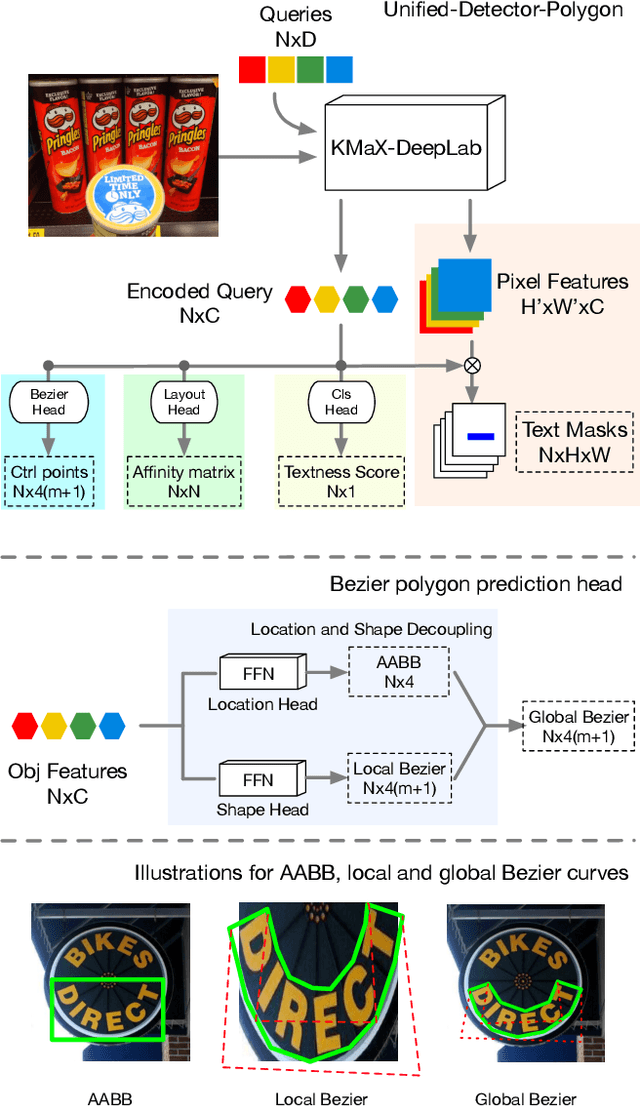
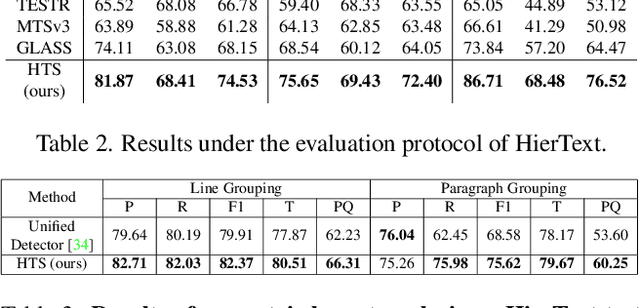
We propose Hierarchical Text Spotter (HTS), a novel method for the joint task of word-level text spotting and geometric layout analysis. HTS can recognize text in an image and identify its 4-level hierarchical structure: characters, words, lines, and paragraphs. The proposed HTS is characterized by two novel components: (1) a Unified-Detector-Polygon (UDP) that produces Bezier Curve polygons of text lines and an affinity matrix for paragraph grouping between detected lines; (2) a Line-to-Character-to-Word (L2C2W) recognizer that splits lines into characters and further merges them back into words. HTS achieves state-of-the-art results on multiple word-level text spotting benchmark datasets as well as geometric layout analysis tasks.
ICDAR 2023 Competition on Hierarchical Text Detection and Recognition
May 16, 2023



We organize a competition on hierarchical text detection and recognition. The competition is aimed to promote research into deep learning models and systems that can jointly perform text detection and recognition and geometric layout analysis. We present details of the proposed competition organization, including tasks, datasets, evaluations, and schedule. During the competition period (from January 2nd 2023 to April 1st 2023), at least 50 submissions from more than 20 teams were made in the 2 proposed tasks. Considering the number of teams and submissions, we conclude that the HierText competition has been successfully held. In this report, we will also present the competition results and insights from them.
Text Reading Order in Uncontrolled Conditions by Sparse Graph Segmentation
May 04, 2023



Text reading order is a crucial aspect in the output of an OCR engine, with a large impact on downstream tasks. Its difficulty lies in the large variation of domain specific layout structures, and is further exacerbated by real-world image degradations such as perspective distortions. We propose a lightweight, scalable and generalizable approach to identify text reading order with a multi-modal, multi-task graph convolutional network (GCN) running on a sparse layout based graph. Predictions from the model provide hints of bidimensional relations among text lines and layout region structures, upon which a post-processing cluster-and-sort algorithm generates an ordered sequence of all the text lines. The model is language-agnostic and runs effectively across multi-language datasets that contain various types of images taken in uncontrolled conditions, and it is small enough to be deployed on virtually any platform including mobile devices.
Towards End-to-End Unified Scene Text Detection and Layout Analysis
Mar 28, 2022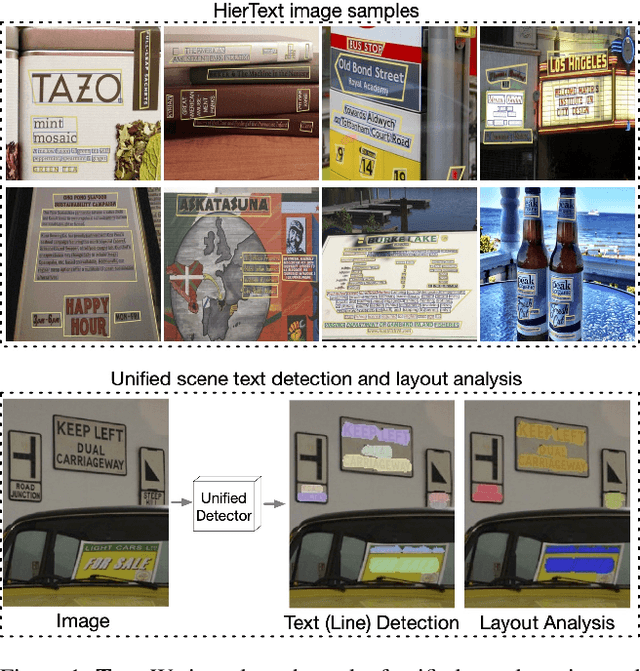
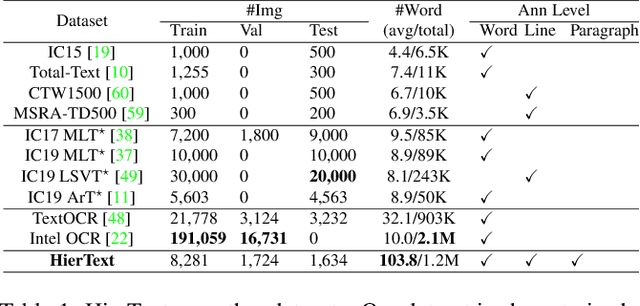
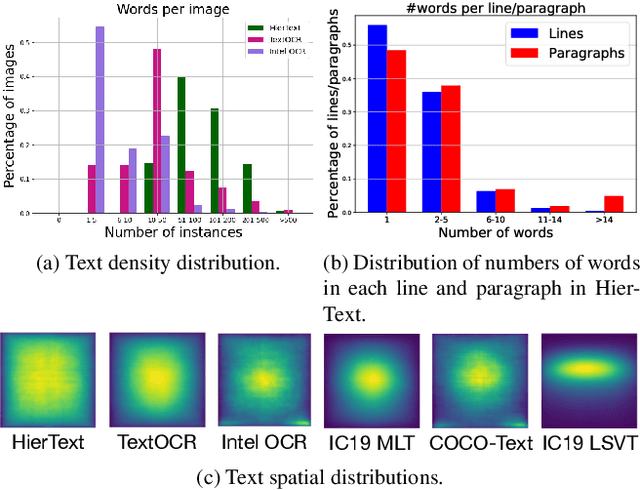

Scene text detection and document layout analysis have long been treated as two separate tasks in different image domains. In this paper, we bring them together and introduce the task of unified scene text detection and layout analysis. The first hierarchical scene text dataset is introduced to enable this novel research task. We also propose a novel method that is able to simultaneously detect scene text and form text clusters in a unified way. Comprehensive experiments show that our unified model achieves better performance than multiple well-designed baseline methods. Additionally, this model achieves state-of-the-art results on multiple scene text detection datasets without the need of complex post-processing. Dataset and code: https://github.com/google-research-datasets/hiertext.
Rethinking Text Line Recognition Models
Apr 21, 2021
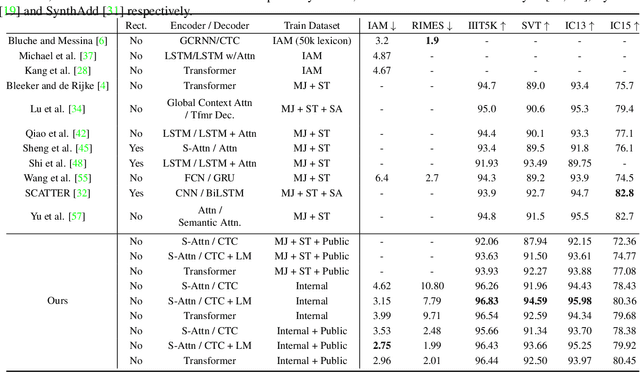

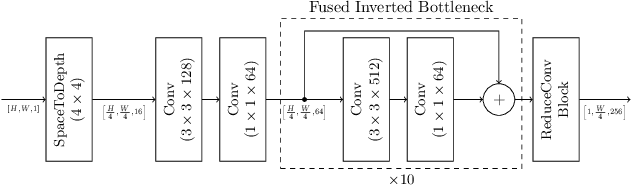
In this paper, we study the problem of text line recognition. Unlike most approaches targeting specific domains such as scene-text or handwritten documents, we investigate the general problem of developing a universal architecture that can extract text from any image, regardless of source or input modality. We consider two decoder families (Connectionist Temporal Classification and Transformer) and three encoder modules (Bidirectional LSTMs, Self-Attention, and GRCLs), and conduct extensive experiments to compare their accuracy and performance on widely used public datasets of scene and handwritten text. We find that a combination that so far has received little attention in the literature, namely a Self-Attention encoder coupled with the CTC decoder, when compounded with an external language model and trained on both public and internal data, outperforms all the others in accuracy and computational complexity. Unlike the more common Transformer-based models, this architecture can handle inputs of arbitrary length, a requirement for universal line recognition. Using an internal dataset collected from multiple sources, we also expose the limitations of current public datasets in evaluating the accuracy of line recognizers, as the relatively narrow image width and sequence length distributions do not allow to observe the quality degradation of the Transformer approach when applied to the transcription of long lines.
Towards Unconstrained End-to-End Text Spotting
Aug 24, 2019
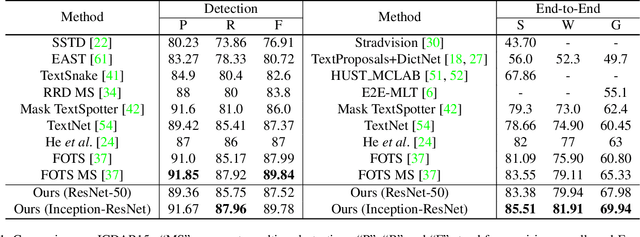

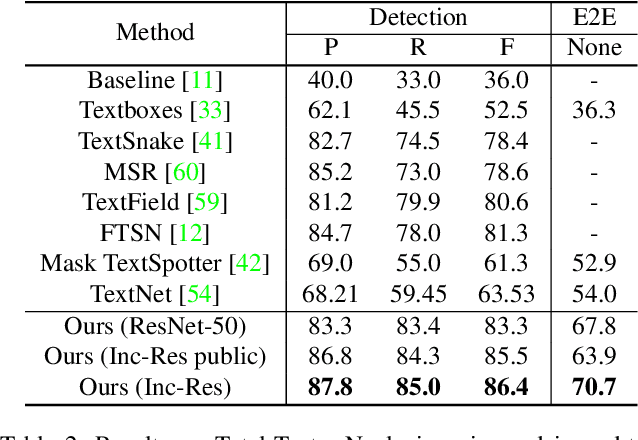
We propose an end-to-end trainable network that can simultaneously detect and recognize text of arbitrary shape, making substantial progress on the open problem of reading scene text of irregular shape. We formulate arbitrary shape text detection as an instance segmentation problem; an attention model is then used to decode the textual content of each irregularly shaped text region without rectification. To extract useful irregularly shaped text instance features from image scale features, we propose a simple yet effective RoI masking step. Additionally, we show that predictions from an existing multi-step OCR engine can be leveraged as partially labeled training data, which leads to significant improvements in both the detection and recognition accuracy of our model. Our method surpasses the state-of-the-art for end-to-end recognition tasks on the ICDAR15 (straight) benchmark by 4.6%, and on the Total-Text (curved) benchmark by more than 16%.