 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableRAG: Million-Token Table Understanding with Language Models
Oct 07, 2024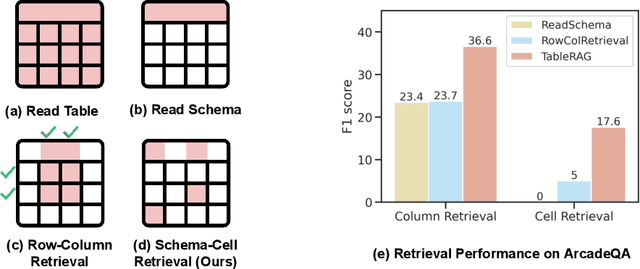
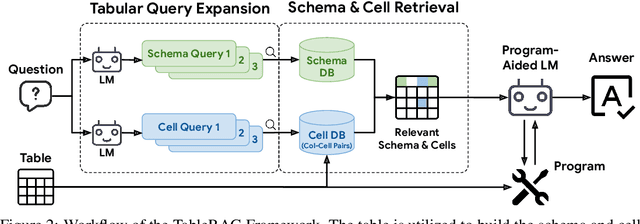
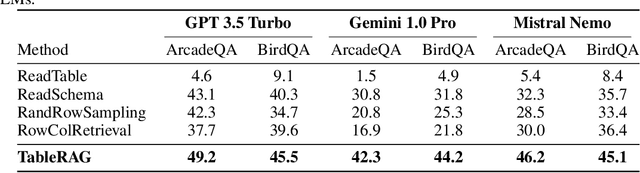
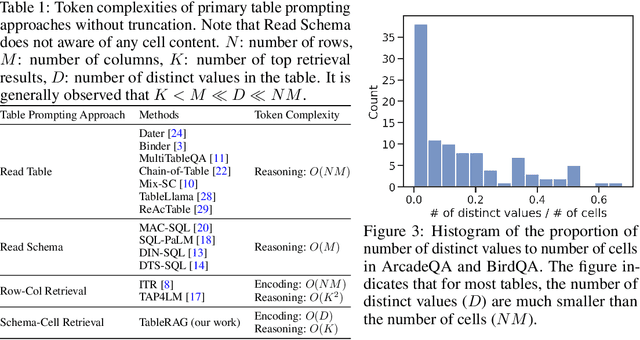
Recent advancements in language models (LMs) have notably enhanced their ability to reason with tabular data, primarily through program-aided mechanisms that manipulate and analyze tables. However, these methods often require the entire table as input, leading to scalability challenges due to the positional bias or context length constraints. In response to these challenges, we introduce TableRAG, a Retrieval-Augmented Generation (RAG) framework specifically designed for LM-based table understanding. TableRAG leverages query expansion combined with schema and cell retrieval to pinpoint crucial information before providing it to the LMs. This enables more efficient data encoding and precise retrieval, significantly reducing prompt lengths and mitigating information loss. We have developed two new million-token benchmarks from the Arcade and BIRD-SQL datasets to thoroughly evaluate TableRAG's effectiveness at scale. Our results demonstrate that TableRAG's retrieval design achieves the highest retrieval quality, leading to the new state-of-the-art performance on large-scale table understanding.
Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding
Jan 19, 2024Table-based reasoning with large language models (LLMs) is a promising direction to tackle many table understanding tasks, such as table-based question answering and fact verification. Compared with generic reasoning, table-based reasoning requires the extraction of underlying semantics from both free-form questions and semi-structured tabular data. Chain-of-Thought and its similar approaches incorporate the reasoning chain in the form of textual context, but it is still an open question how to effectively leverage tabular data in the reasoning chain. We propose the Chain-of-Table framework, where tabular data is explicitly used in the reasoning chain as a proxy for intermediate thoughts. Specifically, we guide LLMs using in-context learning to iteratively generate operations and update the table to represent a tabular reasoning chain. LLMs can therefore dynamically plan the next operation based on the results of the previous ones. This continuous evolution of the table forms a chain, showing the reasoning process for a given tabular problem. The chain carries structured information of the intermediate results, enabling more accurate and reliable predictions. Chain-of-Table achieves new state-of-the-art performance on WikiTQ, FeTaQA, and TabFact benchmarks across multiple LLM choices.
Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis
Oct 25, 2023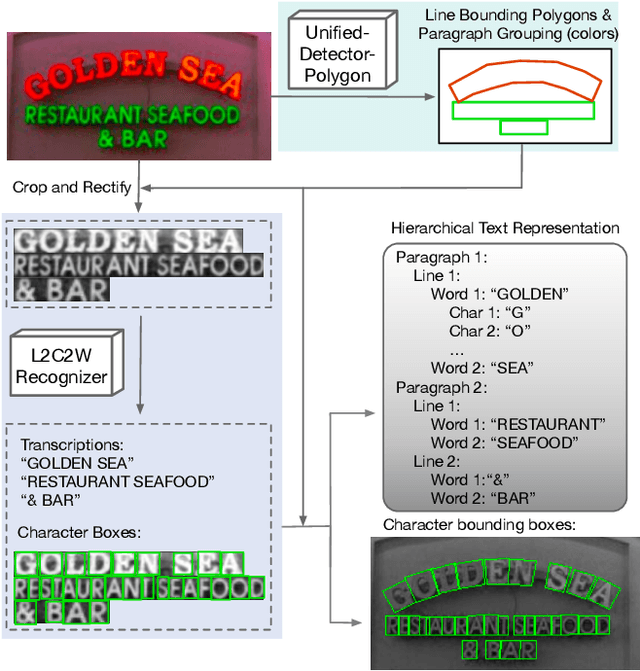
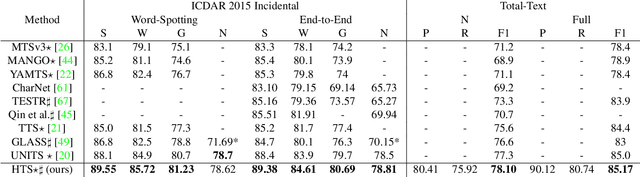
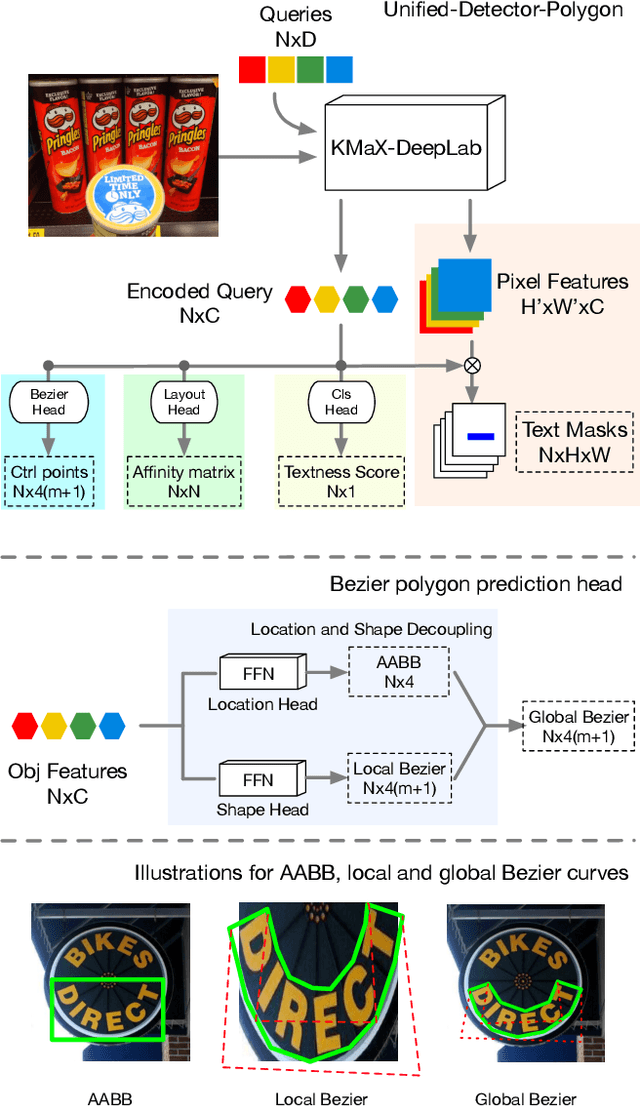
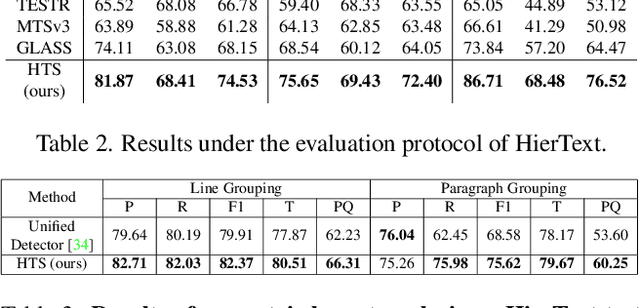
We propose Hierarchical Text Spotter (HTS), a novel method for the joint task of word-level text spotting and geometric layout analysis. HTS can recognize text in an image and identify its 4-level hierarchical structure: characters, words, lines, and paragraphs. The proposed HTS is characterized by two novel components: (1) a Unified-Detector-Polygon (UDP) that produces Bezier Curve polygons of text lines and an affinity matrix for paragraph grouping between detected lines; (2) a Line-to-Character-to-Word (L2C2W) recognizer that splits lines into characters and further merges them back into words. HTS achieves state-of-the-art results on multiple word-level text spotting benchmark datasets as well as geometric layout analysis tasks.
OCR Language Models with Custom Vocabularies
Aug 18, 2023Language models are useful adjuncts to optical models for producing accurate optical character recognition (OCR) results. One factor which limits the power of language models in this context is the existence of many specialized domains with language statistics very different from those implied by a general language model - think of checks, medical prescriptions, and many other specialized document classes. This paper introduces an algorithm for efficiently generating and attaching a domain specific word based language model at run time to a general language model in an OCR system. In order to best use this model the paper also introduces a modified CTC beam search decoder which effectively allows hypotheses to remain in contention based on possible future completion of vocabulary words. The result is a substantial reduction in word error rate in recognizing material from specialized domains.
Tool Documentation Enables Zero-Shot Tool-Usage with Large Language Models
Aug 01, 2023Today, large language models (LLMs) are taught to use new tools by providing a few demonstrations of the tool's usage. Unfortunately, demonstrations are hard to acquire, and can result in undesirable biased usage if the wrong demonstration is chosen. Even in the rare scenario that demonstrations are readily available, there is no principled selection protocol to determine how many and which ones to provide. As tasks grow more complex, the selection search grows combinatorially and invariably becomes intractable. Our work provides an alternative to demonstrations: tool documentation. We advocate the use of tool documentation, descriptions for the individual tool usage, over demonstrations. We substantiate our claim through three main empirical findings on 6 tasks across both vision and language modalities. First, on existing benchmarks, zero-shot prompts with only tool documentation are sufficient for eliciting proper tool usage, achieving performance on par with few-shot prompts. Second, on a newly collected realistic tool-use dataset with hundreds of available tool APIs, we show that tool documentation is significantly more valuable than demonstrations, with zero-shot documentation significantly outperforming few-shot without documentation. Third, we highlight the benefits of tool documentations by tackling image generation and video tracking using just-released unseen state-of-the-art models as tools. Finally, we highlight the possibility of using tool documentation to automatically enable new applications: by using nothing more than the documentation of GroundingDino, Stable Diffusion, XMem, and SAM, LLMs can re-invent the functionalities of the just-released Grounded-SAM and Track Anything models.
ICDAR 2023 Competition on Hierarchical Text Detection and Recognition
May 16, 2023



We organize a competition on hierarchical text detection and recognition. The competition is aimed to promote research into deep learning models and systems that can jointly perform text detection and recognition and geometric layout analysis. We present details of the proposed competition organization, including tasks, datasets, evaluations, and schedule. During the competition period (from January 2nd 2023 to April 1st 2023), at least 50 submissions from more than 20 teams were made in the 2 proposed tasks. Considering the number of teams and submissions, we conclude that the HierText competition has been successfully held. In this report, we will also present the competition results and insights from them.
Text Reading Order in Uncontrolled Conditions by Sparse Graph Segmentation
May 04, 2023



Text reading order is a crucial aspect in the output of an OCR engine, with a large impact on downstream tasks. Its difficulty lies in the large variation of domain specific layout structures, and is further exacerbated by real-world image degradations such as perspective distortions. We propose a lightweight, scalable and generalizable approach to identify text reading order with a multi-modal, multi-task graph convolutional network (GCN) running on a sparse layout based graph. Predictions from the model provide hints of bidimensional relations among text lines and layout region structures, upon which a post-processing cluster-and-sort algorithm generates an ordered sequence of all the text lines. The model is language-agnostic and runs effectively across multi-language datasets that contain various types of images taken in uncontrolled conditions, and it is small enough to be deployed on virtually any platform including mobile devices.
FormNetV2: Multimodal Graph Contrastive Learning for Form Document Information Extraction
May 04, 2023
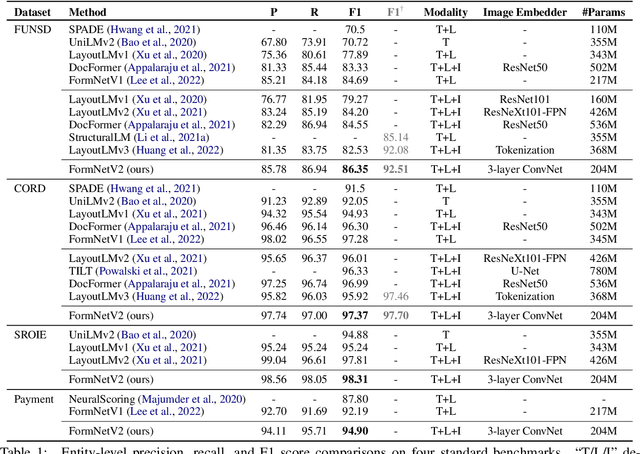
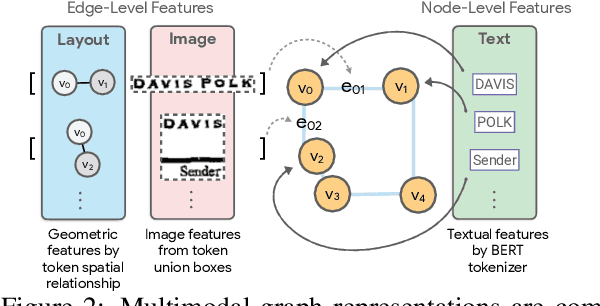
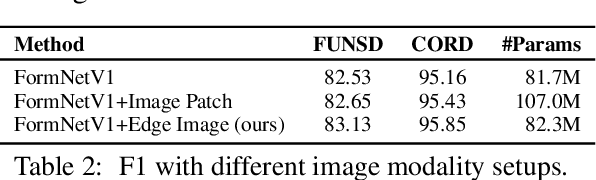
The recent advent of self-supervised pre-training techniques has led to a surge in the use of multimodal learning in form document understanding. However, existing approaches that extend the mask language modeling to other modalities require careful multi-task tuning, complex reconstruction target designs, or additional pre-training data. In FormNetV2, we introduce a centralized multimodal graph contrastive learning strategy to unify self-supervised pre-training for all modalities in one loss. The graph contrastive objective maximizes the agreement of multimodal representations, providing a natural interplay for all modalities without special customization. In addition, we extract image features within the bounding box that joins a pair of tokens connected by a graph edge, capturing more targeted visual cues without loading a sophisticated and separately pre-trained image embedder. FormNetV2 establishes new state-of-the-art performance on FUNSD, CORD, SROIE and Payment benchmarks with a more compact model size.
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
May 03, 2023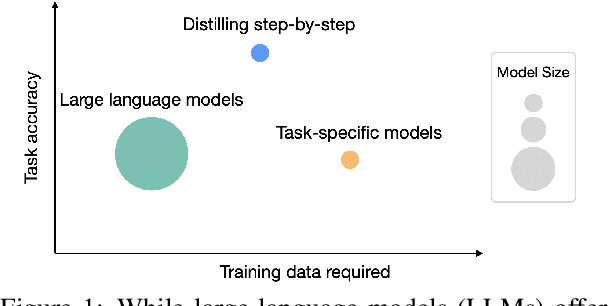
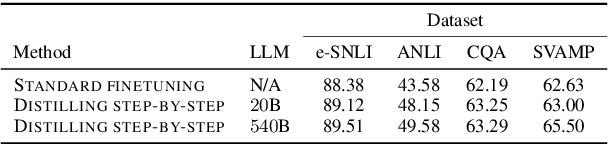
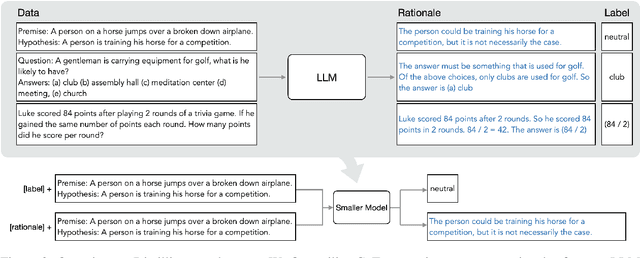

Deploying large language models (LLMs) is challenging because they are memory inefficient and compute-intensive for practical applications. In reaction, researchers train smaller task-specific models by either finetuning with human labels or distilling using LLM-generated labels. However, finetuning and distillation require large amounts of training data to achieve comparable performance to LLMs. We introduce Distilling step-by-step, a new mechanism that (a) trains smaller models that outperform LLMs, and (b) achieves so by leveraging less training data needed by finetuning or distillation. Our method extracts LLM rationales as additional supervision for small models within a multi-task training framework. We present three findings across 4 NLP benchmarks: First, compared to both finetuning and distillation, our mechanism achieves better performance with much fewer labeled/unlabeled training examples. Second, compared to LLMs, we achieve better performance using substantially smaller model sizes. Third, we reduce both the model size and the amount of data required to outperform LLMs; our 770M T5 model outperforms the 540B PaLM model using only 80% of available data on a benchmark task.
Towards End-to-End Unified Scene Text Detection and Layout Analysis
Mar 28, 2022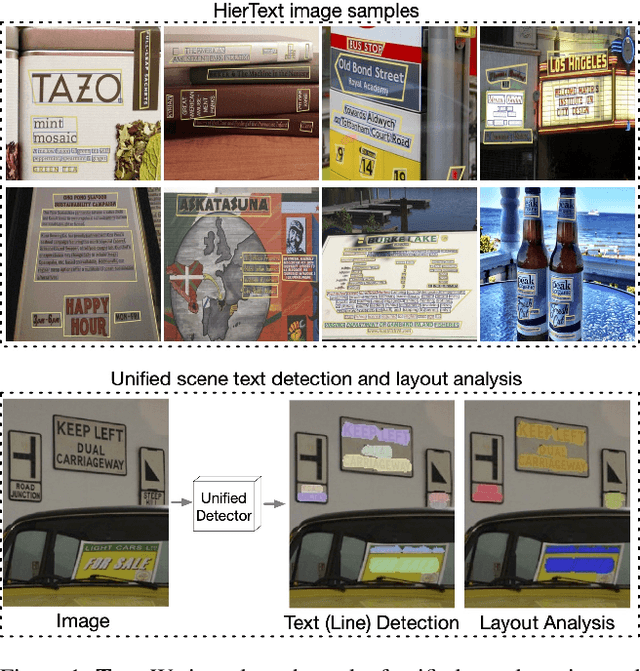
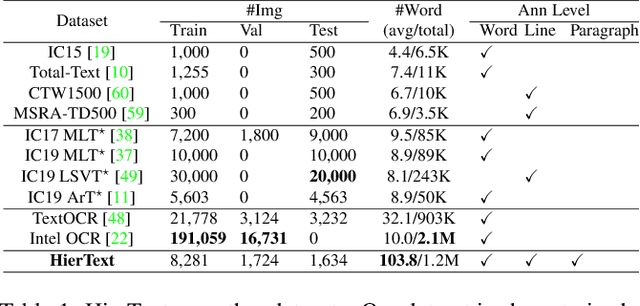
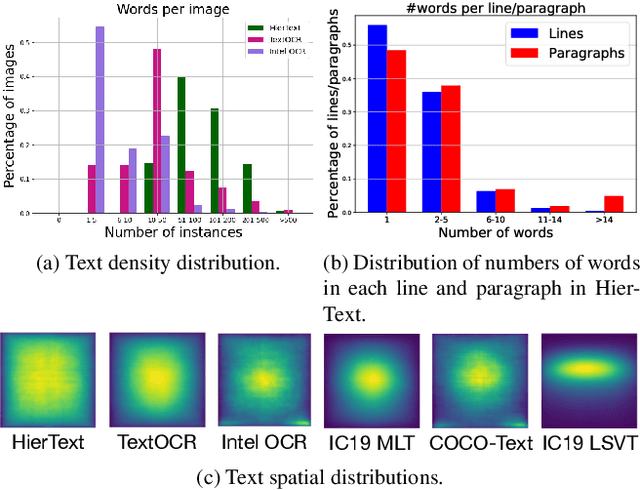

Scene text detection and document layout analysis have long been treated as two separate tasks in different image domains. In this paper, we bring them together and introduce the task of unified scene text detection and layout analysis. The first hierarchical scene text dataset is introduced to enable this novel research task. We also propose a novel method that is able to simultaneously detect scene text and form text clusters in a unified way. Comprehensive experiments show that our unified model achieves better performance than multiple well-designed baseline methods. Additionally, this model achieves state-of-the-art results on multiple scene text detection datasets without the need of complex post-processing. Dataset and code: https://github.com/google-research-datasets/hiertext.