 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiSA: Lifelong Safety Adaptation via Conservative Policy Induction
May 14, 2026As AI agents move from chat interfaces to systems that read private data, call tools, and execute multi-step workflows, guardrails become a last line of defense against concrete deployment harms. In these settings, guardrail failures are no longer merely answer-quality errors: they can leak secrets, authorize unsafe actions, or block legitimate work. The hardest failures are often contextual: whether an action is acceptable depends on local privacy norms, organizational policies, and user expectations that resist pre-deployment specification. This creates a practical gap: guardrails must adapt to their own operating environments, yet deployment feedback is typically limited to sparse, noisy user-reported failures, and repeated fine-tuning is often impractical. To address this gap, we propose LiSA (Lifelong Safety Adaptation), a conservative policy induction framework that improves a fixed base guardrail through structured memory. LiSA converts occasional failures into reusable policy abstractions so that sparse reports can generalize beyond individual cases, adds conflict-aware local rules to prevent overgeneralization in mixed-label contexts, and applies evidence-aware confidence gating via a posterior lower bound, so that memory reuse scales with accumulated evidence rather than empirical accuracy alone. Across PrivacyLens+, ConFaide+, and AgentHarm, LiSA consistently outperforms strong memory-based baselines under sparse feedback, remains robust under noisy user feedback even at 20% label-flip rates, and pushes the latency--performance frontier beyond backbone model scaling. Ultimately, LiSA offers a practical path to secure AI agents against the unpredictable long tail of real-world edge risks.
CausalArmor: Efficient Indirect Prompt Injection Guardrails via Causal Attribution
Feb 08, 2026AI agents equipped with tool-calling capabilities are susceptible to Indirect Prompt Injection (IPI) attacks. In this attack scenario, malicious commands hidden within untrusted content trick the agent into performing unauthorized actions. Existing defenses can reduce attack success but often suffer from the over-defense dilemma: they deploy expensive, always-on sanitization regardless of actual threat, thereby degrading utility and latency even in benign scenarios. We revisit IPI through a causal ablation perspective: a successful injection manifests as a dominance shift where the user request no longer provides decisive support for the agent's privileged action, while a particular untrusted segment, such as a retrieved document or tool output, provides disproportionate attributable influence. Based on this signature, we propose CausalArmor, a selective defense framework that (i) computes lightweight, leave-one-out ablation-based attributions at privileged decision points, and (ii) triggers targeted sanitization only when an untrusted segment dominates the user intent. Additionally, CausalArmor employs retroactive Chain-of-Thought masking to prevent the agent from acting on ``poisoned'' reasoning traces. We present a theoretical analysis showing that sanitization based on attribution margins conditionally yields an exponentially small upper bound on the probability of selecting malicious actions. Experiments on AgentDojo and DoomArena demonstrate that CausalArmor matches the security of aggressive defenses while improving explainability and preserving utility and latency of AI agents.
Co-RedTeam: Orchestrated Security Discovery and Exploitation with LLM Agents
Feb 02, 2026Large language models (LLMs) have shown promise in assisting cybersecurity tasks, yet existing approaches struggle with automatic vulnerability discovery and exploitation due to limited interaction, weak execution grounding, and a lack of experience reuse. We propose Co-RedTeam, a security-aware multi-agent framework designed to mirror real-world red-teaming workflows by integrating security-domain knowledge, code-aware analysis, execution-grounded iterative reasoning, and long-term memory. Co-RedTeam decomposes vulnerability analysis into coordinated discovery and exploitation stages, enabling agents to plan, execute, validate, and refine actions based on real execution feedback while learning from prior trajectories. Extensive evaluations on challenging security benchmarks demonstrate that Co-RedTeam consistently outperforms strong baselines across diverse backbone models, achieving over 60% success rate in vulnerability exploitation and over 10% absolute improvement in vulnerability detection. Ablation and iteration studies further confirm the critical role of execution feedback, structured interaction, and memory for building robust and generalizable cybersecurity agents.
Synapse: Adaptive Arbitration of Complementary Expertise in Time Series Foundational Models
Nov 07, 2025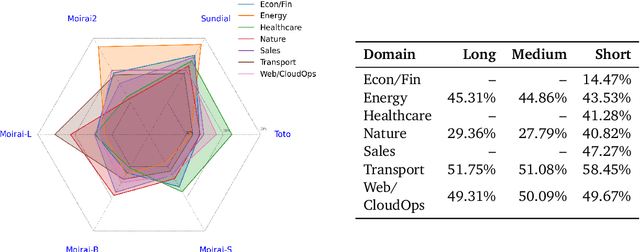
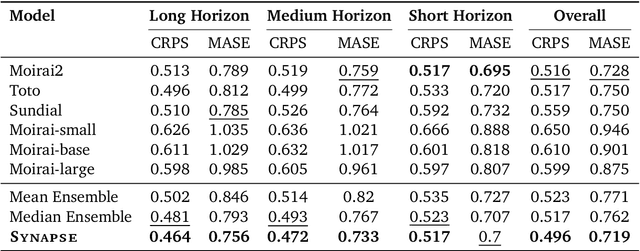
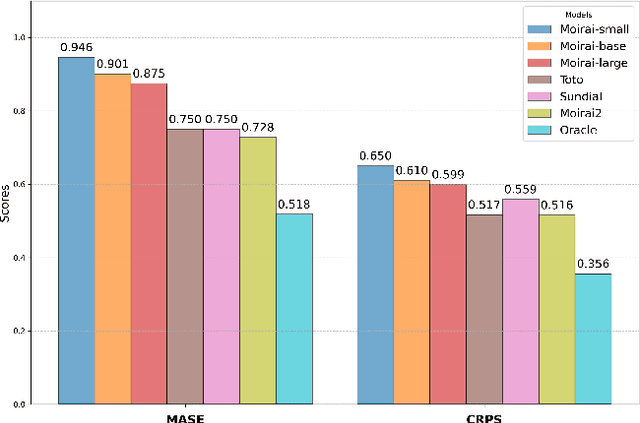

Pre-trained Time Series Foundational Models (TSFMs) represent a significant advance, capable of forecasting diverse time series with complex characteristics, including varied seasonalities, trends, and long-range dependencies. Despite their primary goal of universal time series forecasting, their efficacy is far from uniform; divergent training protocols and data sources cause individual TSFMs to exhibit highly variable performance across different forecasting tasks, domains, and horizons. Leveraging this complementary expertise by arbitrating existing TSFM outputs presents a compelling strategy, yet this remains a largely unexplored area of research. In this paper, we conduct a thorough examination of how different TSFMs exhibit specialized performance profiles across various forecasting settings, and how we can effectively leverage this behavior in arbitration between different time series models. We specifically analyze how factors such as model selection and forecast horizon distribution can influence the efficacy of arbitration strategies. Based on this analysis, we propose Synapse, a novel arbitration framework for TSFMs. Synapse is designed to dynamically leverage a pool of TSFMs, assign and adjust predictive weights based on their relative, context-dependent performance, and construct a robust forecast distribution by adaptively sampling from the output quantiles of constituent models. Experimental results demonstrate that Synapse consistently outperforms other popular ensembling techniques as well as individual TSFMs, demonstrating Synapse's efficacy in time series forecasting.
Model Swarms: Collaborative Search to Adapt LLM Experts via Swarm Intelligence
Oct 15, 2024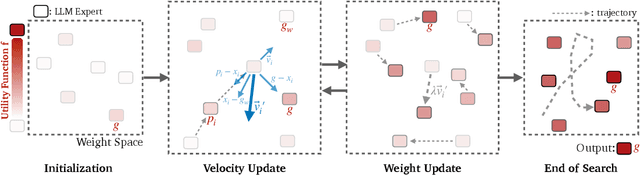
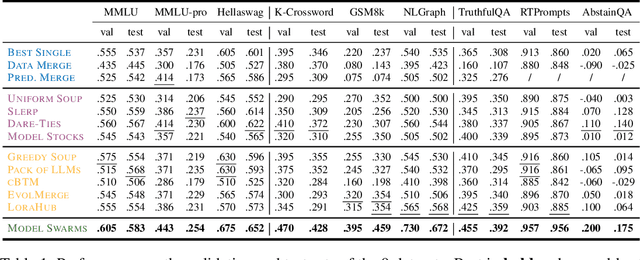
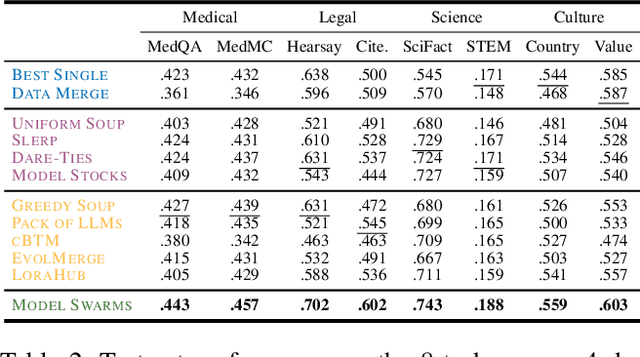
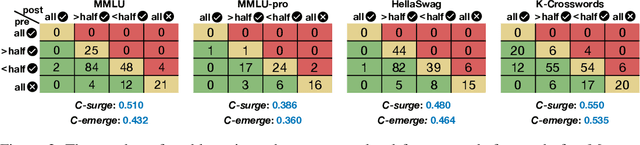
We propose Model Swarms, a collaborative search algorithm to adapt LLMs via swarm intelligence, the collective behavior guiding individual systems. Specifically, Model Swarms starts with a pool of LLM experts and a utility function. Guided by the best-found checkpoints across models, diverse LLM experts collaboratively move in the weight space and optimize a utility function representing model adaptation objectives. Compared to existing model composition approaches, Model Swarms offers tuning-free model adaptation, works in low-data regimes with as few as 200 examples, and does not require assumptions about specific experts in the swarm or how they should be composed. Extensive experiments demonstrate that Model Swarms could flexibly adapt LLM experts to a single task, multi-task domains, reward models, as well as diverse human interests, improving over 12 model composition baselines by up to 21.0% across tasks and contexts. Further analysis reveals that LLM experts discover previously unseen capabilities in initial checkpoints and that Model Swarms enable the weak-to-strong transition of experts through the collaborative search process.
TableRAG: Million-Token Table Understanding with Language Models
Oct 07, 2024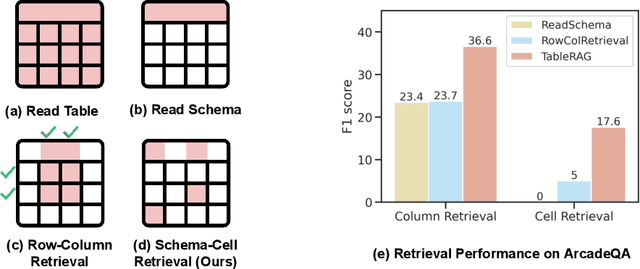
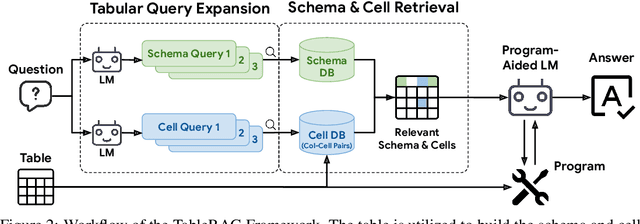
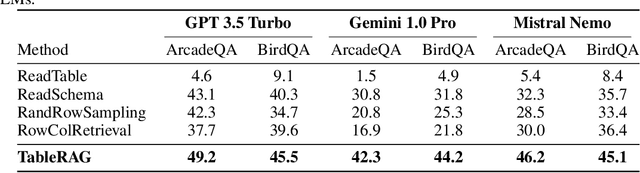
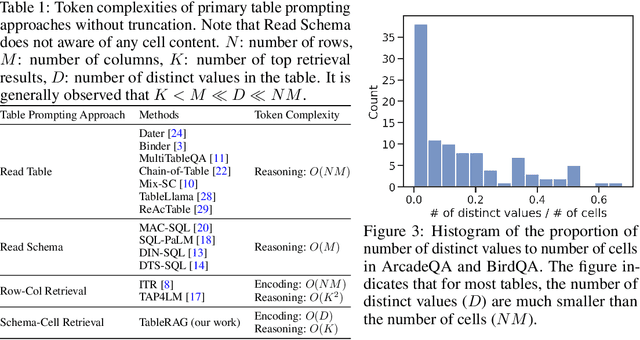
Recent advancements in language models (LMs) have notably enhanced their ability to reason with tabular data, primarily through program-aided mechanisms that manipulate and analyze tables. However, these methods often require the entire table as input, leading to scalability challenges due to the positional bias or context length constraints. In response to these challenges, we introduce TableRAG, a Retrieval-Augmented Generation (RAG) framework specifically designed for LM-based table understanding. TableRAG leverages query expansion combined with schema and cell retrieval to pinpoint crucial information before providing it to the LMs. This enables more efficient data encoding and precise retrieval, significantly reducing prompt lengths and mitigating information loss. We have developed two new million-token benchmarks from the Arcade and BIRD-SQL datasets to thoroughly evaluate TableRAG's effectiveness at scale. Our results demonstrate that TableRAG's retrieval design achieves the highest retrieval quality, leading to the new state-of-the-art performance on large-scale table understanding.
SQL-GEN: Bridging the Dialect Gap for Text-to-SQL Via Synthetic Data And Model Merging
Aug 22, 2024



Text-to-SQL systems, which convert natural language queries into SQL commands, have seen significant progress primarily for the SQLite dialect. However, adapting these systems to other SQL dialects like BigQuery and PostgreSQL remains a challenge due to the diversity in SQL syntax and functions. We introduce SQL-GEN, a framework for generating high-quality dialect-specific synthetic data guided by dialect-specific tutorials, and demonstrate its effectiveness in creating training datasets for multiple dialects. Our approach significantly improves performance, by up to 20\%, over previous methods and reduces the gap with large-scale human-annotated datasets. Moreover, combining our synthetic data with human-annotated data provides additional performance boosts of 3.3\% to 5.6\%. We also introduce a novel Mixture of Experts (MoE) initialization method that integrates dialect-specific models into a unified system by merging self-attention layers and initializing the gates with dialect-specific keywords, further enhancing performance across different SQL dialects.
CaLM: Contrasting Large and Small Language Models to Verify Grounded Generation
Jun 08, 2024Grounded generation aims to equip language models (LMs) with the ability to produce more credible and accountable responses by accurately citing verifiable sources. However, existing methods, by either feeding LMs with raw or preprocessed materials, remain prone to errors. To address this, we introduce CaLM, a novel verification framework. CaLM leverages the insight that a robust grounded response should be consistent with information derived solely from its cited sources. Our framework empowers smaller LMs, which rely less on parametric memory and excel at processing relevant information given a query, to validate the output of larger LMs. Larger LM responses that closely align with the smaller LMs' output, which relies exclusively on cited documents, are verified. Responses showing discrepancies are iteratively refined through a feedback loop. Experiments on three open-domain question-answering datasets demonstrate significant performance gains of 1.5% to 7% absolute average without any required model fine-tuning.
Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding
Jan 19, 2024Table-based reasoning with large language models (LLMs) is a promising direction to tackle many table understanding tasks, such as table-based question answering and fact verification. Compared with generic reasoning, table-based reasoning requires the extraction of underlying semantics from both free-form questions and semi-structured tabular data. Chain-of-Thought and its similar approaches incorporate the reasoning chain in the form of textual context, but it is still an open question how to effectively leverage tabular data in the reasoning chain. We propose the Chain-of-Table framework, where tabular data is explicitly used in the reasoning chain as a proxy for intermediate thoughts. Specifically, we guide LLMs using in-context learning to iteratively generate operations and update the table to represent a tabular reasoning chain. LLMs can therefore dynamically plan the next operation based on the results of the previous ones. This continuous evolution of the table forms a chain, showing the reasoning process for a given tabular problem. The chain carries structured information of the intermediate results, enabling more accurate and reliable predictions. Chain-of-Table achieves new state-of-the-art performance on WikiTQ, FeTaQA, and TabFact benchmarks across multiple LLM choices.
Transformers as Graph-to-Graph Models
Oct 27, 2023We argue that Transformers are essentially graph-to-graph models, with sequences just being a special case. Attention weights are functionally equivalent to graph edges. Our Graph-to-Graph Transformer architecture makes this ability explicit, by inputting graph edges into the attention weight computations and predicting graph edges with attention-like functions, thereby integrating explicit graphs into the latent graphs learned by pretrained Transformers. Adding iterative graph refinement provides a joint embedding of input, output, and latent graphs, allowing non-autoregressive graph prediction to optimise the complete graph without any bespoke pipeline or decoding strategy. Empirical results show that this architecture achieves state-of-the-art accuracies for modelling a variety of linguistic structures, integrating very effectively with the latent linguistic representations learned by pretraining.