 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Online and Offline RL: Contextual Bandit Learning for Multi-Turn Code Generation
Feb 03, 2026Recently, there have been significant research interests in training large language models (LLMs) with reinforcement learning (RL) on real-world tasks, such as multi-turn code generation. While online RL tends to perform better than offline RL, its higher training cost and instability hinders wide adoption. In this paper, we build on the observation that multi-turn code generation can be formulated as a one-step recoverable Markov decision process and propose contextual bandit learning with offline trajectories (Cobalt), a new method that combines the benefits of online and offline RL. Cobalt first collects code generation trajectories using a reference LLM and divides them into partial trajectories as contextual prompts. Then, during online bandit learning, the LLM is trained to complete each partial trajectory prompt through single-step code generation. Cobalt outperforms two multi-turn online RL baselines based on GRPO and VeRPO, and substantially improves R1-Distill 8B and Qwen3 8B by up to 9.0 and 6.2 absolute Pass@1 scores on LiveCodeBench. Also, we analyze LLMs' in-context reward hacking behaviors and augment Cobalt training with perturbed trajectories to mitigate this issue. Overall, our results demonstrate Cobalt as a promising solution for iterative decision-making tasks like multi-turn code generation. Our code and data are available at https://github.com/OSU-NLP-Group/cobalt.
Segmenting Text and Learning Their Rewards for Improved RLHF in Language Model
Jan 06, 2025Reinforcement learning from human feedback (RLHF) has been widely adopted to align language models (LMs) with human preference. Prior RLHF works typically take a bandit formulation, which, though intuitive, ignores the sequential nature of LM generation and can suffer from the sparse reward issue. While recent works propose dense token-level RLHF, treating each token as an action may be oversubtle to proper reward assignment. In this paper, we seek to get the best of both by training and utilizing a segment-level reward model, which assigns a reward to each semantically complete text segment that spans over a short sequence of tokens. For reward learning, our method allows dynamic text segmentation and compatibility with standard sequence-preference datasets. For effective RL-based LM training against segment reward, we generalize the classical scalar bandit reward normalizers into location-aware normalizer functions and interpolate the segment reward for further densification. With these designs, our method performs competitively on three popular RLHF benchmarks for LM policy: AlpacaEval 2.0, Arena-Hard, and MT-Bench. Ablation studies are conducted to further demonstrate our method.
Developing a Reliable, General-Purpose Hallucination Detection and Mitigation Service: Insights and Lessons Learned
Jul 22, 2024
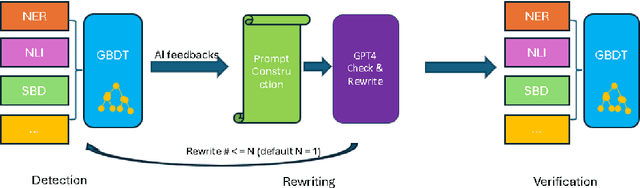
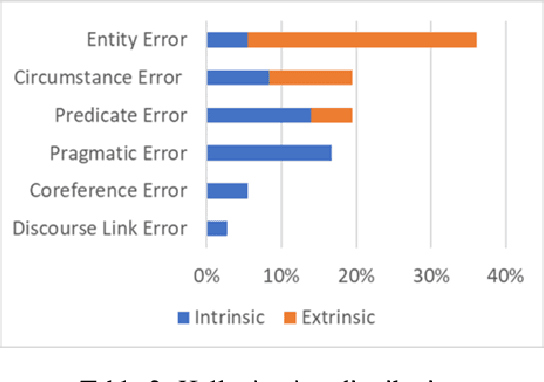
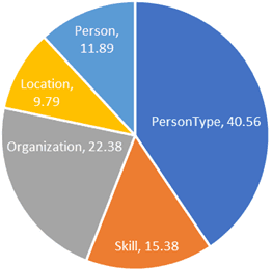
Hallucination, a phenomenon where large language models (LLMs) produce output that is factually incorrect or unrelated to the input, is a major challenge for LLM applications that require accuracy and dependability. In this paper, we introduce a reliable and high-speed production system aimed at detecting and rectifying the hallucination issue within LLMs. Our system encompasses named entity recognition (NER), natural language inference (NLI), span-based detection (SBD), and an intricate decision tree-based process to reliably detect a wide range of hallucinations in LLM responses. Furthermore, our team has crafted a rewriting mechanism that maintains an optimal mix of precision, response time, and cost-effectiveness. We detail the core elements of our framework and underscore the paramount challenges tied to response time, availability, and performance metrics, which are crucial for real-world deployment of these technologies. Our extensive evaluation, utilizing offline data and live production traffic, confirms the efficacy of our proposed framework and service.
Diffusion-RPO: Aligning Diffusion Models through Relative Preference Optimization
Jun 10, 2024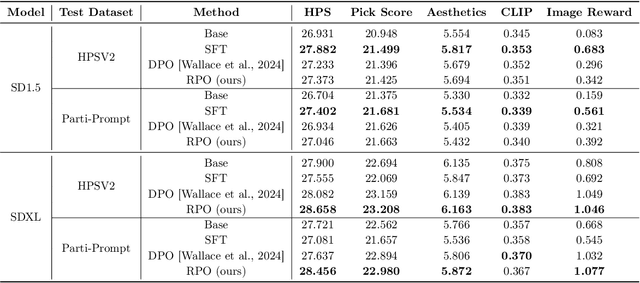

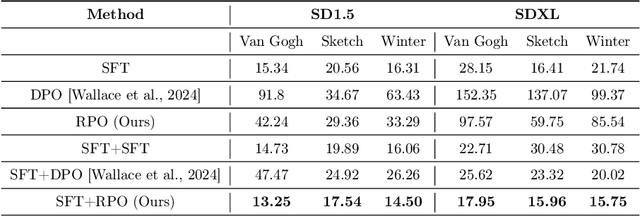

Aligning large language models with human preferences has emerged as a critical focus in language modeling research. Yet, integrating preference learning into Text-to-Image (T2I) generative models is still relatively uncharted territory. The Diffusion-DPO technique made initial strides by employing pairwise preference learning in diffusion models tailored for specific text prompts. We introduce Diffusion-RPO, a new method designed to align diffusion-based T2I models with human preferences more effectively. This approach leverages both prompt-image pairs with identical prompts and those with semantically related content across various modalities. Furthermore, we have developed a new evaluation metric, style alignment, aimed at overcoming the challenges of high costs, low reproducibility, and limited interpretability prevalent in current evaluations of human preference alignment. Our findings demonstrate that Diffusion-RPO outperforms established methods such as Supervised Fine-Tuning and Diffusion-DPO in tuning Stable Diffusion versions 1.5 and XL-1.0, achieving superior results in both automated evaluations of human preferences and style alignment. Our code is available at https://github.com/yigu1008/Diffusion-RPO
Self-Augmented Preference Optimization: Off-Policy Paradigms for Language Model Alignment
May 31, 2024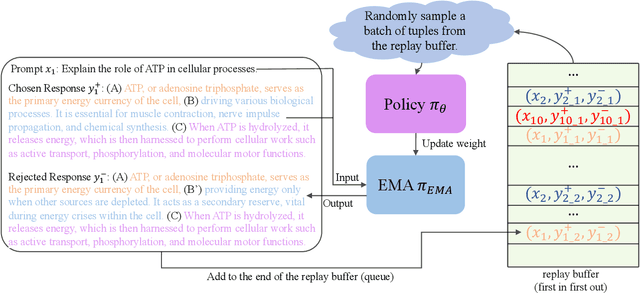

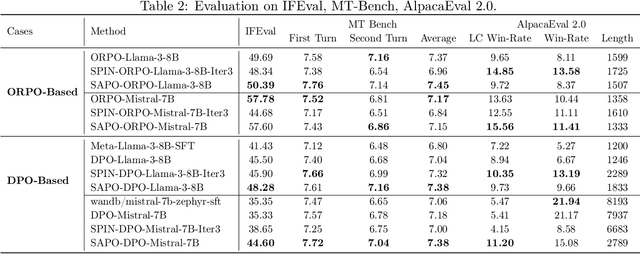

Traditional language model alignment methods, such as Direct Preference Optimization (DPO), are limited by their dependence on static, pre-collected paired preference data, which hampers their adaptability and practical applicability. To overcome this limitation, we introduce Self-Augmented Preference Optimization (SAPO), an effective and scalable training paradigm that does not require existing paired data. Building on the self-play concept, which autonomously generates negative responses, we further incorporate an off-policy learning pipeline to enhance data exploration and exploitation. Specifically, we employ an Exponential Moving Average (EMA) model in conjunction with a replay buffer to enable dynamic updates of response segments, effectively integrating real-time feedback with insights from historical data. Our comprehensive evaluations of the LLaMA3-8B and Mistral-7B models across benchmarks, including the Open LLM Leaderboard, IFEval, AlpacaEval 2.0, and MT-Bench, demonstrate that SAPO matches or surpasses established offline contrastive baselines, such as DPO and Odds Ratio Preference Optimization, and outperforms offline self-play methods like SPIN. Our code is available at https://github.com/yinyueqin/SAPO
Training Small Multimodal Models to Bridge Biomedical Competency Gap: A Case Study in Radiology Imaging
Mar 20, 2024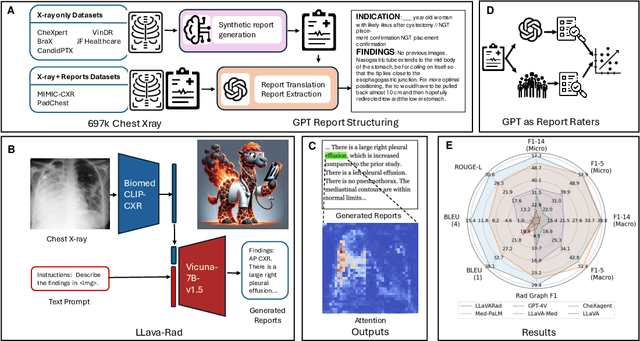
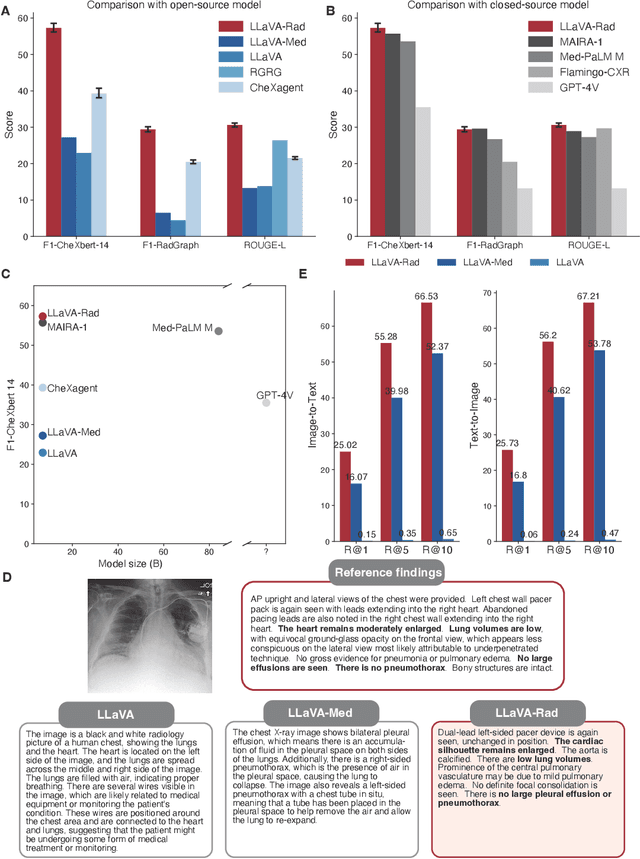
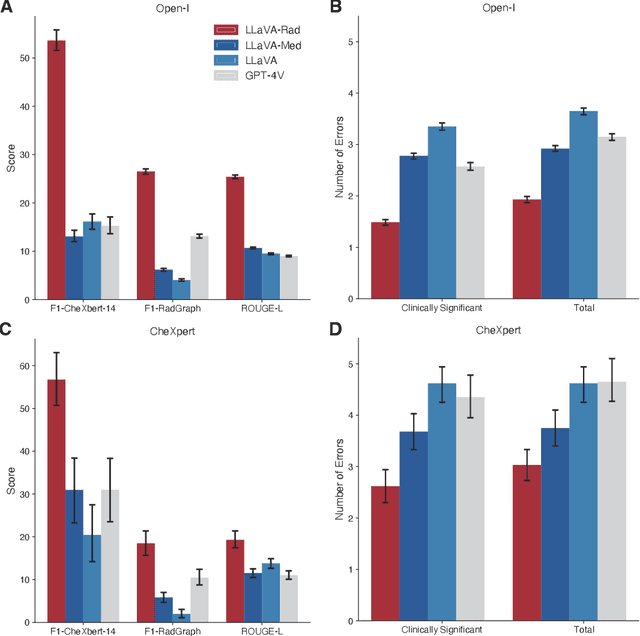
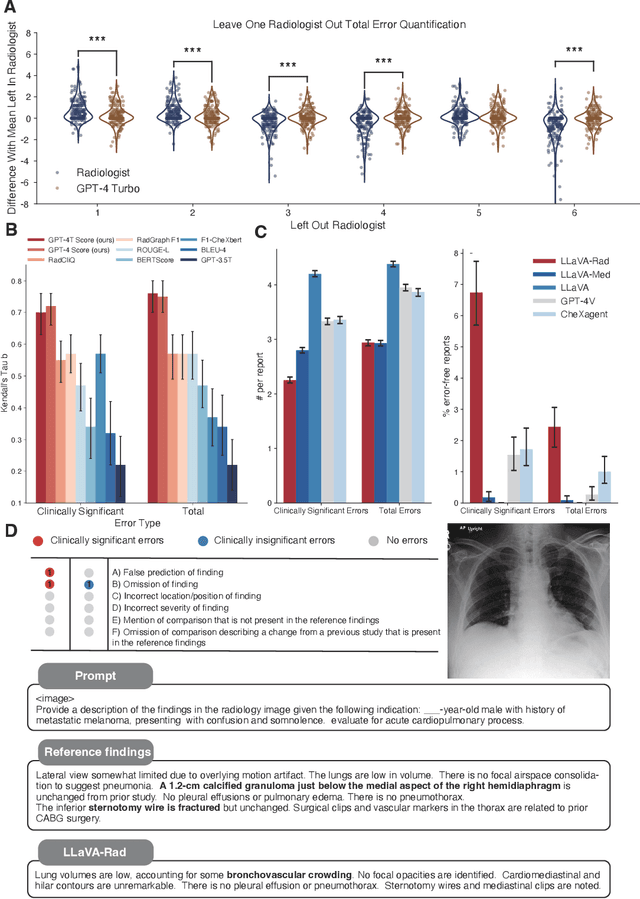
The scaling laws and extraordinary performance of large foundation models motivate the development and utilization of such large models in biomedicine. However, despite early promising results on some biomedical benchmarks, there are still major challenges that need to be addressed before these models can be used in real-world applications. Frontier models such as GPT-4V still have major competency gaps in multimodal capabilities for biomedical applications. Moreover, pragmatic issues such as access, cost, latency, and compliance make it hard for clinicians to use privately-hosted state-of-the-art large models directly on private patient data. In this paper, we explore training open-source small multimodal models (SMMs) to bridge biomedical competency gaps for unmet clinical needs. To maximize data efficiency, we adopt a modular approach by incorporating state-of-the-art pre-trained models for image and text modalities, and focusing on training a lightweight adapter to ground each modality to the text embedding space. We conduct a comprehensive study of this approach on radiology imaging. For training, we assemble a large dataset with over 1 million image-text pairs. For evaluation, we propose a clinically driven novel approach using GPT-4 and demonstrate its parity with expert evaluation. We also study grounding qualitatively using attention. For best practice, we conduct a systematic ablation study on various choices in data engineering and multimodal training. The resulting LLaVA-Rad (7B) model attains state-of-the-art results on radiology tasks such as report generation and cross-modal retrieval, even outperforming much larger models such as GPT-4V and Med-PaLM M (84B). LLaVA-Rad is fast and can be run on a single V100 GPU in private settings, offering a promising state-of-the-art tool for real-world clinical applications.
Video-Bench: A Comprehensive Benchmark and Toolkit for Evaluating Video-based Large Language Models
Nov 28, 2023



Video-based large language models (Video-LLMs) have been recently introduced, targeting both fundamental improvements in perception and comprehension, and a diverse range of user inquiries. In pursuit of the ultimate goal of achieving artificial general intelligence, a truly intelligent Video-LLM model should not only see and understand the surroundings, but also possess human-level commonsense, and make well-informed decisions for the users. To guide the development of such a model, the establishment of a robust and comprehensive evaluation system becomes crucial. To this end, this paper proposes \textit{Video-Bench}, a new comprehensive benchmark along with a toolkit specifically designed for evaluating Video-LLMs. The benchmark comprises 10 meticulously crafted tasks, evaluating the capabilities of Video-LLMs across three distinct levels: Video-exclusive Understanding, Prior Knowledge-based Question-Answering, and Comprehension and Decision-making. In addition, we introduce an automatic toolkit tailored to process model outputs for various tasks, facilitating the calculation of metrics and generating convenient final scores. We evaluate 8 representative Video-LLMs using \textit{Video-Bench}. The findings reveal that current Video-LLMs still fall considerably short of achieving human-like comprehension and analysis of real-world videos, offering valuable insights for future research directions. The benchmark and toolkit are available at: \url{https://github.com/PKU-YuanGroup/Video-Bench}.
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
Sep 07, 2023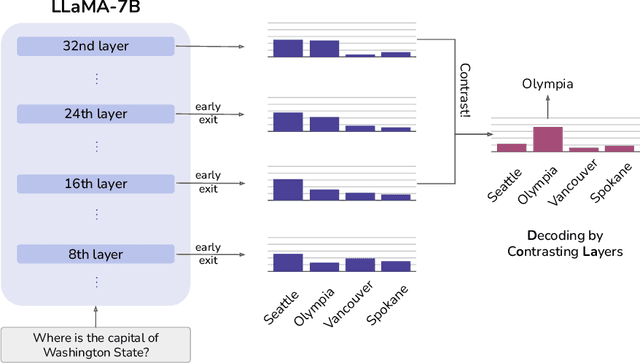
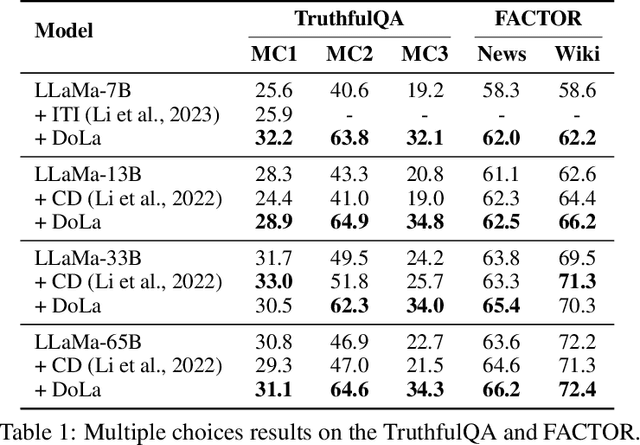
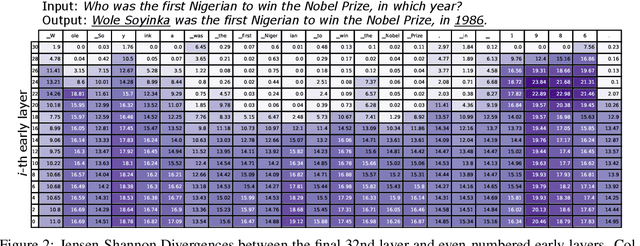
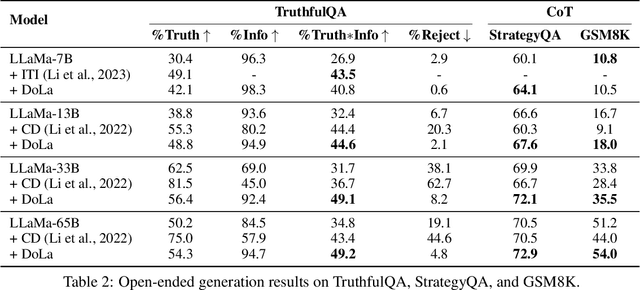
Despite their impressive capabilities, large language models (LLMs) are prone to hallucinations, i.e., generating content that deviates from facts seen during pretraining. We propose a simple decoding strategy for reducing hallucinations with pretrained LLMs that does not require conditioning on retrieved external knowledge nor additional fine-tuning. Our approach obtains the next-token distribution by contrasting the differences in logits obtained from projecting the later layers versus earlier layers to the vocabulary space, exploiting the fact that factual knowledge in an LLMs has generally been shown to be localized to particular transformer layers. We find that this Decoding by Contrasting Layers (DoLa) approach is able to better surface factual knowledge and reduce the generation of incorrect facts. DoLa consistently improves the truthfulness across multiple choices tasks and open-ended generation tasks, for example improving the performance of LLaMA family models on TruthfulQA by 12-17% absolute points, demonstrating its potential in making LLMs reliably generate truthful facts.
Predictive Sparse Manifold Transform
Aug 27, 2023We present Predictive Sparse Manifold Transform (PSMT), a minimalistic, interpretable and biologically plausible framework for learning and predicting natural dynamics. PSMT incorporates two layers where the first sparse coding layer represents the input sequence as sparse coefficients over an overcomplete dictionary and the second manifold learning layer learns a geometric embedding space that captures topological similarity and dynamic temporal linearity in sparse coefficients. We apply PSMT on a natural video dataset and evaluate the reconstruction performance with respect to contextual variability, the number of sparse coding basis functions and training samples. We then interpret the dynamic topological organization in the embedding space. We next utilize PSMT to predict future frames compared with two baseline methods with a static embedding space. We demonstrate that PSMT with a dynamic embedding space can achieve better prediction performance compared to static baselines. Our work establishes that PSMT is an efficient unsupervised generative framework for prediction of future visual stimuli.
Interactive Editing for Text Summarization
Jun 05, 2023



Summarizing lengthy documents is a common and essential task in our daily lives. Although recent advancements in neural summarization models can assist in crafting general-purpose summaries, human writers often have specific requirements that call for a more customized approach. To address this need, we introduce REVISE (Refinement and Editing via Iterative Summarization Enhancement), an innovative framework designed to facilitate iterative editing and refinement of draft summaries by human writers. Within our framework, writers can effortlessly modify unsatisfactory segments at any location or length and provide optional starting phrases -- our system will generate coherent alternatives that seamlessly integrate with the existing summary. At its core, REVISE incorporates a modified fill-in-the-middle model with the encoder-decoder architecture while developing novel evaluation metrics tailored for the summarization task. In essence, our framework empowers users to create high-quality, personalized summaries by effectively harnessing both human expertise and AI capabilities, ultimately transforming the summarization process into a truly collaborative and adaptive experience.