 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevBench: A Realistic, Developer-Informed Benchmark for Code Generation Models
Jan 17, 2026DevBench is a telemetry-driven benchmark designed to evaluate Large Language Models (LLMs) on realistic code completion tasks. It includes 1,800 evaluation instances across six programming languages and six task categories derived from real developer telemetry, such as API usage and code purpose understanding. Unlike prior benchmarks, it emphasizes ecological validity, avoids training data contamination, and enables detailed diagnostics. The evaluation combines functional correctness, similarity-based metrics, and LLM-judge assessments focused on usefulness and contextual relevance. 9 state-of-the-art models were assessed, revealing differences in syntactic precision, semantic reasoning, and practical utility. Our benchmark provides actionable insights to guide model selection and improvement-detail that is often missing from other benchmarks but is essential for both practical deployment and targeted model development.
Segmenting Text and Learning Their Rewards for Improved RLHF in Language Model
Jan 06, 2025Reinforcement learning from human feedback (RLHF) has been widely adopted to align language models (LMs) with human preference. Prior RLHF works typically take a bandit formulation, which, though intuitive, ignores the sequential nature of LM generation and can suffer from the sparse reward issue. While recent works propose dense token-level RLHF, treating each token as an action may be oversubtle to proper reward assignment. In this paper, we seek to get the best of both by training and utilizing a segment-level reward model, which assigns a reward to each semantically complete text segment that spans over a short sequence of tokens. For reward learning, our method allows dynamic text segmentation and compatibility with standard sequence-preference datasets. For effective RL-based LM training against segment reward, we generalize the classical scalar bandit reward normalizers into location-aware normalizer functions and interpolate the segment reward for further densification. With these designs, our method performs competitively on three popular RLHF benchmarks for LM policy: AlpacaEval 2.0, Arena-Hard, and MT-Bench. Ablation studies are conducted to further demonstrate our method.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Unraveling the "Anomaly" in Time Series Anomaly Detection: A Self-supervised Tri-domain Solution
Nov 27, 2023The ongoing challenges in time series anomaly detection (TSAD), notably the scarcity of anomaly labels and the variability in anomaly lengths and shapes, have led to the need for a more efficient solution. As limited anomaly labels hinder traditional supervised models in TSAD, various SOTA deep learning techniques, such as self-supervised learning, have been introduced to tackle this issue. However, they encounter difficulties handling variations in anomaly lengths and shapes, limiting their adaptability to diverse anomalies. Additionally, many benchmark datasets suffer from the problem of having explicit anomalies that even random functions can detect. This problem is exacerbated by ill-posed evaluation metrics, known as point adjustment (PA), which can result in inflated model performance. In this context, we propose a novel self-supervised learning based Tri-domain Anomaly Detector (TriAD), which addresses these challenges by modeling features across three data domains - temporal, frequency, and residual domains - without relying on anomaly labels. Unlike traditional contrastive learning methods, TriAD employs both inter-domain and intra-domain contrastive loss to learn common attributes among normal data and differentiate them from anomalies. Additionally, our approach can detect anomalies of varying lengths by integrating with a discord discovery algorithm. It is worth noting that this study is the first to reevaluate the deep learning potential in TSAD, utilizing both rigorously designed datasets (i.e., UCR Archive) and evaluation metrics (i.e., PA%K and affiliation). Through experimental results on the UCR dataset, TriAD achieves an impressive three-fold increase in PA%K based F1 scores over SOTA deep learning models, and 50% increase of accuracy as compared to SOTA discord discovery algorithms.
TinyAD: Memory-efficient anomaly detection for time series data in Industrial IoT
Mar 07, 2023



Monitoring and detecting abnormal events in cyber-physical systems is crucial to industrial production. With the prevalent deployment of the Industrial Internet of Things (IIoT), an enormous amount of time series data is collected to facilitate machine learning models for anomaly detection, and it is of the utmost importance to directly deploy the trained models on the IIoT devices. However, it is most challenging to deploy complex deep learning models such as Convolutional Neural Networks (CNNs) on these memory-constrained IIoT devices embedded with microcontrollers (MCUs). To alleviate the memory constraints of MCUs, we propose a novel framework named Tiny Anomaly Detection (TinyAD) to efficiently facilitate onboard inference of CNNs for real-time anomaly detection. First, we conduct a comprehensive analysis of depthwise separable CNNs and regular CNNs for anomaly detection and find that the depthwise separable convolution operation can reduce the model size by 50-90% compared with the traditional CNNs. Then, to reduce the peak memory consumption of CNNs, we explore two complementary strategies, in-place, and patch-by-patch memory rescheduling, and integrate them into a unified framework. The in-place method decreases the peak memory of the depthwise convolution by sparing a temporary buffer to transfer the activation results, while the patch-by-patch method further reduces the peak memory of layer-wise execution by slicing the input data into corresponding receptive fields and executing in order. Furthermore, by adjusting the dimension of convolution filters, these strategies apply to both univariate time series and multidomain time series features. Extensive experiments on real-world industrial datasets show that our framework can reduce peak memory consumption by 2-5x with negligible computation overhead.
Spatial-Temporal Meta-path Guided Explainable Crime Prediction
May 04, 2022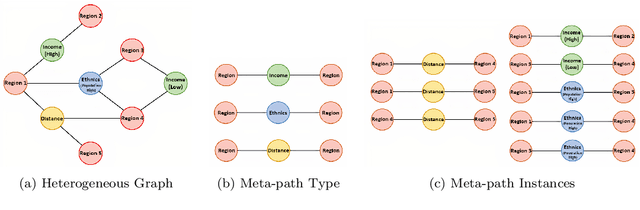

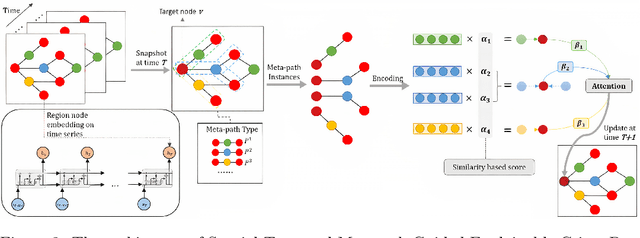
Exposure to crime and violence can harm individuals' quality of life and the economic growth of communities. In light of the rapid development in machine learning, there is a rise in the need to explore automated solutions to prevent crimes. With the increasing availability of both fine-grained urban and public service data, there is a recent surge in fusing such cross-domain information to facilitate crime prediction. By capturing the information about social structure, environment, and crime trends, existing machine learning predictive models have explored the dynamic crime patterns from different views. However, these approaches mostly convert such multi-source knowledge into implicit and latent representations (e.g., learned embeddings of districts), making it still a challenge to investigate the impacts of explicit factors for the occurrences of crimes behind the scenes. In this paper, we present a Spatial-Temporal Metapath guided Explainable Crime prediction (STMEC) framework to capture dynamic patterns of crime behaviours and explicitly characterize how the environmental and social factors mutually interact to produce the forecasts. Extensive experiments show the superiority of STMEC compared with other advanced spatiotemporal models, especially in predicting felonies (e.g., robberies and assaults with dangerous weapons).
Example-Based Named Entity Recognition
Aug 24, 2020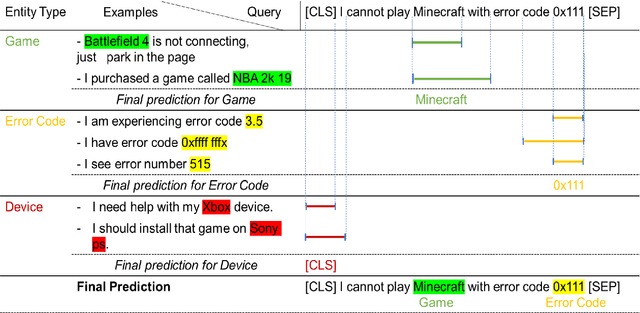
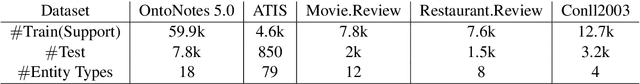
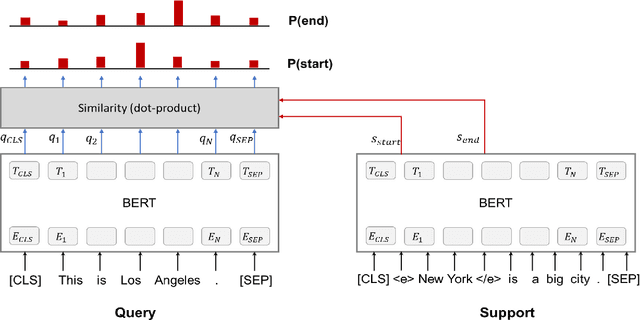
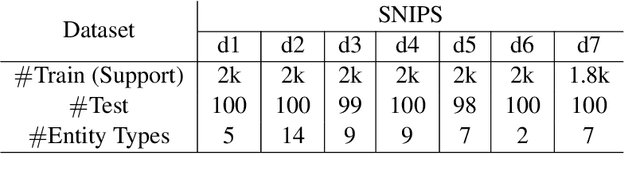
We present a novel approach to named entity recognition (NER) in the presence of scarce data that we call example-based NER. Our train-free few-shot learning approach takes inspiration from question-answering to identify entity spans in a new and unseen domain. In comparison with the current state-of-the-art, the proposed method performs significantly better, especially when using a low number of support examples.