 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws of Synthetic Data for Language Models
Mar 26, 2025



Large language models (LLMs) achieve strong performance across diverse tasks, largely driven by high-quality web data used in pre-training. However, recent studies indicate this data source is rapidly depleting. Synthetic data emerges as a promising alternative, but it remains unclear whether synthetic datasets exhibit predictable scalability comparable to raw pre-training data. In this work, we systematically investigate the scaling laws of synthetic data by introducing SynthLLM, a scalable framework that transforms pre-training corpora into diverse, high-quality synthetic datasets. Our approach achieves this by automatically extracting and recombining high-level concepts across multiple documents using a graph algorithm. Key findings from our extensive mathematical experiments on SynthLLM include: (1) SynthLLM generates synthetic data that reliably adheres to the rectified scaling law across various model sizes; (2) Performance improvements plateau near 300B tokens; and (3) Larger models approach optimal performance with fewer training tokens. For instance, an 8B model peaks at 1T tokens, while a 3B model requires 4T. Moreover, comparisons with existing synthetic data generation and augmentation methods demonstrate that SynthLLM achieves superior performance and scalability. Our findings highlight synthetic data as a scalable and reliable alternative to organic pre-training corpora, offering a viable path toward continued improvement in model performance.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Chain-of-Reasoning: Towards Unified Mathematical Reasoning in Large Language Models via a Multi-Paradigm Perspective
Jan 19, 2025Large Language Models (LLMs) have made notable progress in mathematical reasoning, yet they often rely on single-paradigm reasoning that limits their effectiveness across diverse tasks. In this paper, we introduce Chain-of-Reasoning (CoR), a novel unified framework that integrates multiple reasoning paradigms--Natural Language Reasoning (NLR), Algorithmic Reasoning (AR), and Symbolic Reasoning (SR)--to enable synergistic collaboration. CoR generates multiple potential answers using different reasoning paradigms and synthesizes them into a coherent final solution. We propose a Progressive Paradigm Training (PPT) strategy that allows models to progressively master these paradigms, culminating in the development of CoR-Math-7B. Experimental results demonstrate that CoR-Math-7B significantly outperforms current SOTA models, achieving up to a 41.0% absolute improvement over GPT-4 in theorem proving tasks and a 7.9% improvement over RL-based methods in arithmetic tasks. These results showcase the enhanced mathematical comprehensive ability of our model, achieving significant performance gains on specific tasks and enabling zero-shot generalization across tasks.
Training Small Multimodal Models to Bridge Biomedical Competency Gap: A Case Study in Radiology Imaging
Mar 20, 2024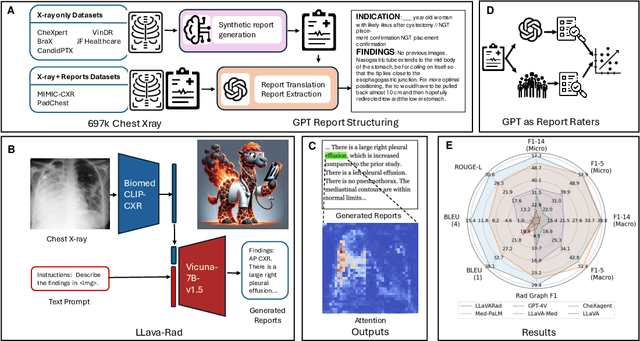
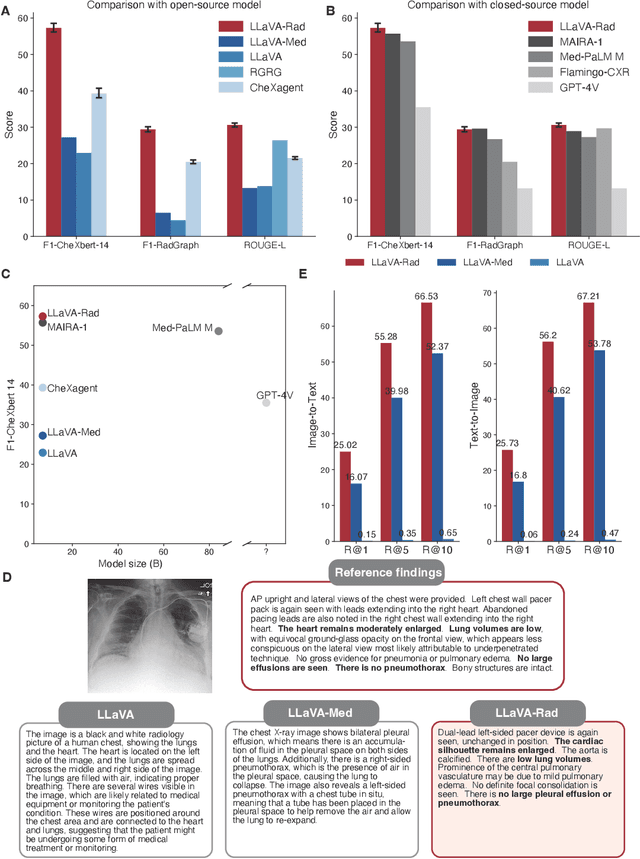
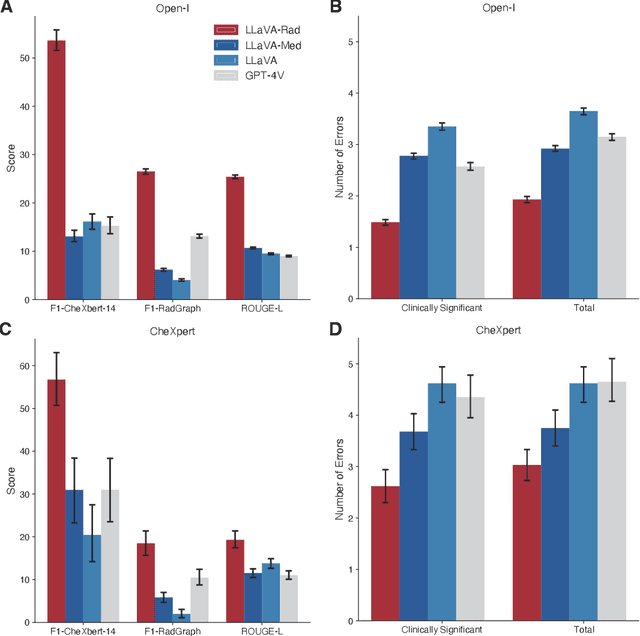
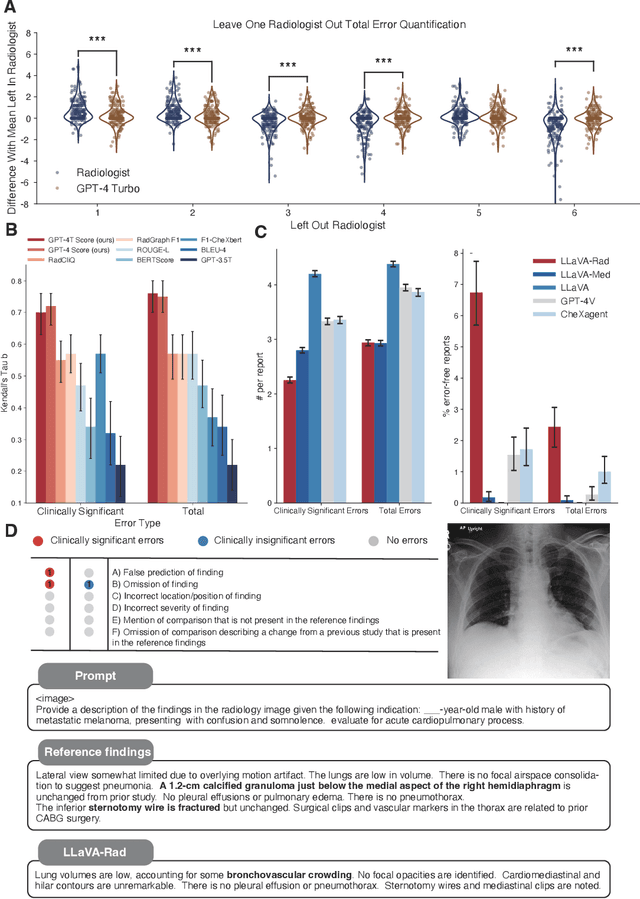
The scaling laws and extraordinary performance of large foundation models motivate the development and utilization of such large models in biomedicine. However, despite early promising results on some biomedical benchmarks, there are still major challenges that need to be addressed before these models can be used in real-world applications. Frontier models such as GPT-4V still have major competency gaps in multimodal capabilities for biomedical applications. Moreover, pragmatic issues such as access, cost, latency, and compliance make it hard for clinicians to use privately-hosted state-of-the-art large models directly on private patient data. In this paper, we explore training open-source small multimodal models (SMMs) to bridge biomedical competency gaps for unmet clinical needs. To maximize data efficiency, we adopt a modular approach by incorporating state-of-the-art pre-trained models for image and text modalities, and focusing on training a lightweight adapter to ground each modality to the text embedding space. We conduct a comprehensive study of this approach on radiology imaging. For training, we assemble a large dataset with over 1 million image-text pairs. For evaluation, we propose a clinically driven novel approach using GPT-4 and demonstrate its parity with expert evaluation. We also study grounding qualitatively using attention. For best practice, we conduct a systematic ablation study on various choices in data engineering and multimodal training. The resulting LLaVA-Rad (7B) model attains state-of-the-art results on radiology tasks such as report generation and cross-modal retrieval, even outperforming much larger models such as GPT-4V and Med-PaLM M (84B). LLaVA-Rad is fast and can be run on a single V100 GPU in private settings, offering a promising state-of-the-art tool for real-world clinical applications.
CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation
Nov 30, 2023



We present CoDi-2, a versatile and interactive Multimodal Large Language Model (MLLM) that can follow complex multimodal interleaved instructions, conduct in-context learning (ICL), reason, chat, edit, etc., in an any-to-any input-output modality paradigm. By aligning modalities with language for both encoding and generation, CoDi-2 empowers Large Language Models (LLMs) to not only understand complex modality-interleaved instructions and in-context examples, but also autoregressively generate grounded and coherent multimodal outputs in the continuous feature space. To train CoDi-2, we build a large-scale generation dataset encompassing in-context multimodal instructions across text, vision, and audio. CoDi-2 demonstrates a wide range of zero-shot capabilities for multimodal generation, such as in-context learning, reasoning, and compositionality of any-to-any modality generation through multi-round interactive conversation. CoDi-2 surpasses previous domain-specific models on tasks such as subject-driven image generation, vision transformation, and audio editing. CoDi-2 signifies a substantial breakthrough in developing a comprehensive multimodal foundation model adept at interpreting in-context language-vision-audio interleaved instructions and producing multimodal outputs.
i-Code Studio: A Configurable and Composable Framework for Integrative AI
May 23, 2023



Artificial General Intelligence (AGI) requires comprehensive understanding and generation capabilities for a variety of tasks spanning different modalities and functionalities. Integrative AI is one important direction to approach AGI, through combining multiple models to tackle complex multimodal tasks. However, there is a lack of a flexible and composable platform to facilitate efficient and effective model composition and coordination. In this paper, we propose the i-Code Studio, a configurable and composable framework for Integrative AI. The i-Code Studio orchestrates multiple pre-trained models in a finetuning-free fashion to conduct complex multimodal tasks. Instead of simple model composition, the i-Code Studio provides an integrative, flexible, and composable setting for developers to quickly and easily compose cutting-edge services and technologies tailored to their specific requirements. The i-Code Studio achieves impressive results on a variety of zero-shot multimodal tasks, such as video-to-text retrieval, speech-to-speech translation, and visual question answering. We also demonstrate how to quickly build a multimodal agent based on the i-Code Studio that can communicate and personalize for users.
i-Code V2: An Autoregressive Generation Framework over Vision, Language, and Speech Data
May 21, 2023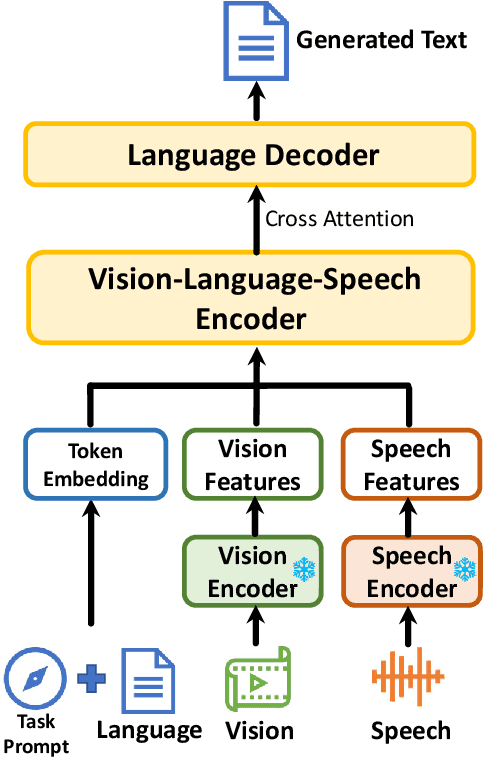
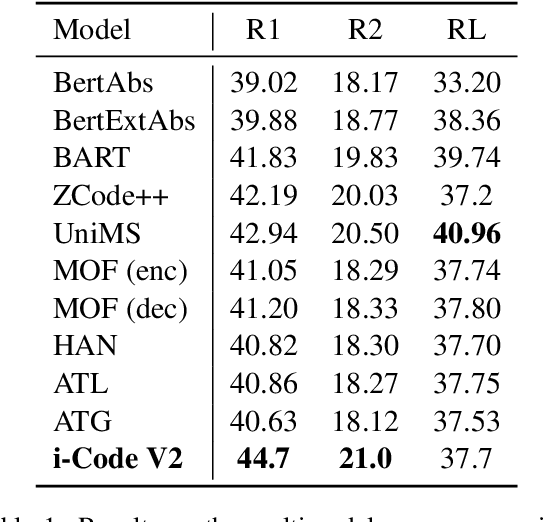
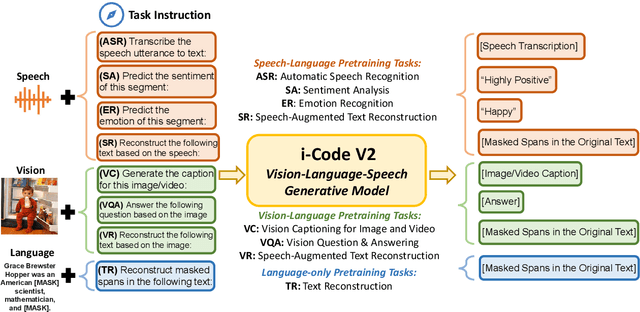

The convergence of text, visual, and audio data is a key step towards human-like artificial intelligence, however the current Vision-Language-Speech landscape is dominated by encoder-only models which lack generative abilities. We propose closing this gap with i-Code V2, the first model capable of generating natural language from any combination of Vision, Language, and Speech data. i-Code V2 is an integrative system that leverages state-of-the-art single-modality encoders, combining their outputs with a new modality-fusing encoder in order to flexibly project combinations of modalities into a shared representational space. Next, language tokens are generated from these representations via an autoregressive decoder. The whole framework is pretrained end-to-end on a large collection of dual- and single-modality datasets using a novel text completion objective that can be generalized across arbitrary combinations of modalities. i-Code V2 matches or outperforms state-of-the-art single- and dual-modality baselines on 7 multimodal tasks, demonstrating the power of generative multimodal pretraining across a diversity of tasks and signals.
Learning to Represent Programs with Graphs
May 04, 2018
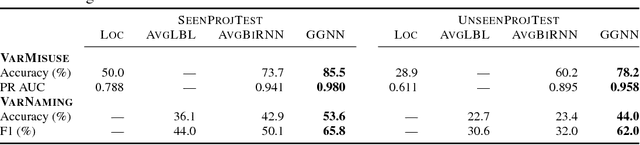
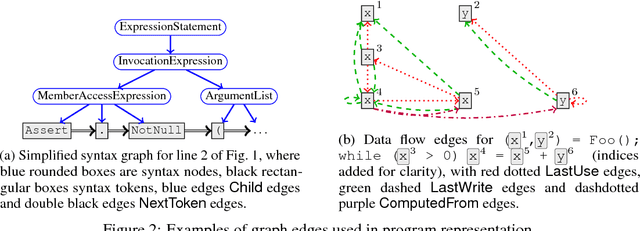

Learning tasks on source code (i.e., formal languages) have been considered recently, but most work has tried to transfer natural language methods and does not capitalize on the unique opportunities offered by code's known syntax. For example, long-range dependencies induced by using the same variable or function in distant locations are often not considered. We propose to use graphs to represent both the syntactic and semantic structure of code and use graph-based deep learning methods to learn to reason over program structures. In this work, we present how to construct graphs from source code and how to scale Gated Graph Neural Networks training to such large graphs. We evaluate our method on two tasks: VarNaming, in which a network attempts to predict the name of a variable given its usage, and VarMisuse, in which the network learns to reason about selecting the correct variable that should be used at a given program location. Our comparison to methods that use less structured program representations shows the advantages of modeling known structure, and suggests that our models learn to infer meaningful names and to solve the VarMisuse task in many cases. Additionally, our testing showed that VarMisuse identifies a number of bugs in mature open-source projects.
Relative Facial Action Unit Detection
May 01, 2014

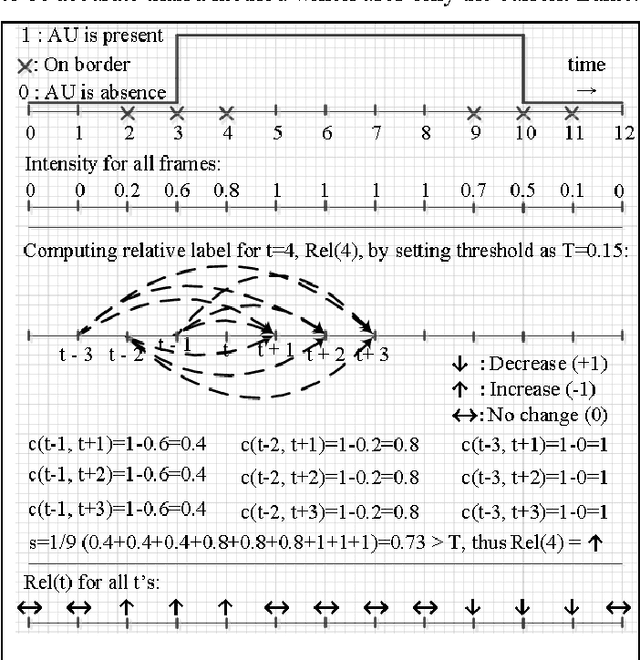
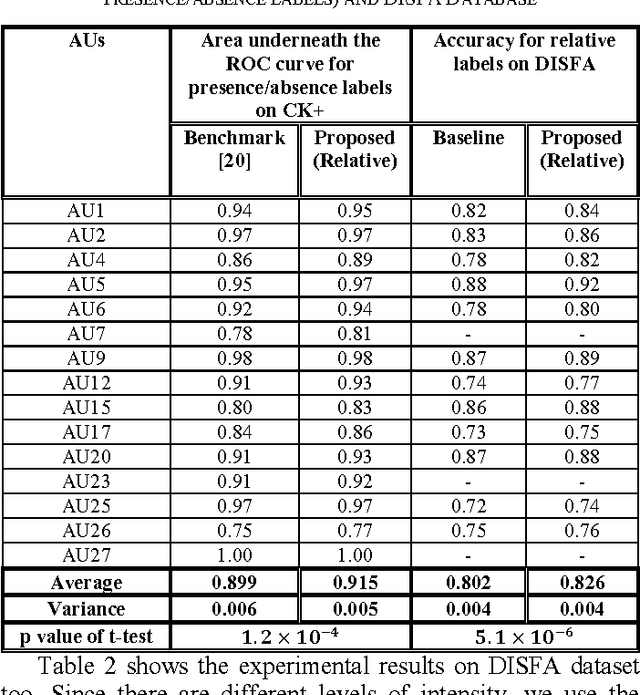
This paper presents a subject-independent facial action unit (AU) detection method by introducing the concept of relative AU detection, for scenarios where the neutral face is not provided. We propose a new classification objective function which analyzes the temporal neighborhood of the current frame to decide if the expression recently increased, decreased or showed no change. This approach is a significant change from the conventional absolute method which decides about AU classification using the current frame, without an explicit comparison with its neighboring frames. Our proposed method improves robustness to individual differences such as face scale and shape, age-related wrinkles, and transitions among expressions (e.g., lower intensity of expressions). Our experiments on three publicly available datasets (Extended Cohn-Kanade (CK+), Bosphorus, and DISFA databases) show significant improvement of our approach over conventional absolute techniques. Keywords: facial action coding system (FACS); relative facial action unit detection; temporal information;
Facial Expression Representation and Recognition Using 2DHLDA, Gabor Wavelets, and Ensemble Learning
Jul 20, 2012In this paper, a novel method for representation and recognition of the facial expressions in two-dimensional image sequences is presented. We apply a variation of two-dimensional heteroscedastic linear discriminant analysis (2DHLDA) algorithm, as an efficient dimensionality reduction technique, to Gabor representation of the input sequence. 2DHLDA is an extension of the two-dimensional linear discriminant analysis (2DLDA) approach and it removes the equal within-class covariance. By applying 2DHLDA in two directions, we eliminate the correlations between both image columns and image rows. Then, we perform a one-dimensional LDA on the new features. This combined method can alleviate the small sample size problem and instability encountered by HLDA. Also, employing both geometric and appearance features and using an ensemble learning scheme based on data fusion, we create a classifier which can efficiently classify the facial expressions. The proposed method is robust to illumination changes and it can properly represent temporal information as well as subtle changes in facial muscles. We provide experiments on Cohn-Kanade database that show the superiority of the proposed method. KEYWORDS: two-dimensional heteroscedastic linear discriminant analysis (2DHLDA), subspace learning, facial expression analysis, Gabor wavelets, ensemble learning.