 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEMPURA: Temporal Event Masked Prediction and Understanding for Reasoning in Action
May 02, 2025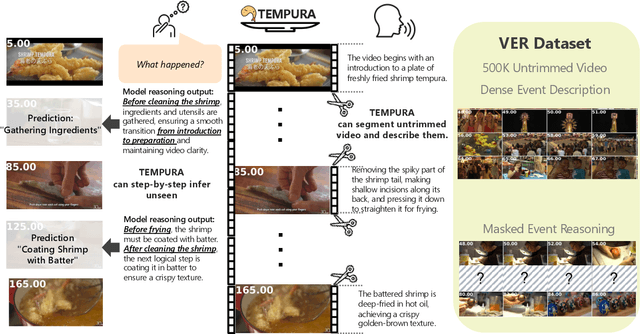

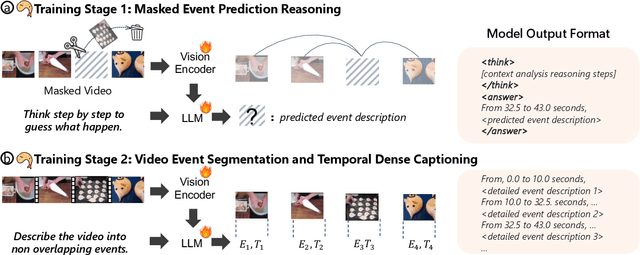
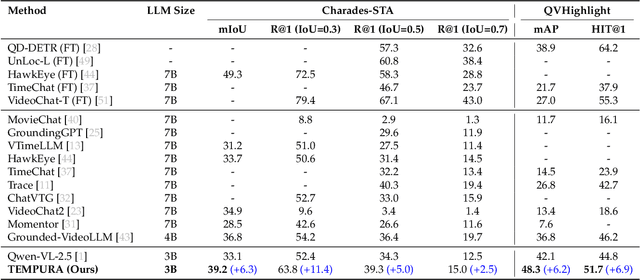
Understanding causal event relationships and achieving fine-grained temporal grounding in videos remain challenging for vision-language models. Existing methods either compress video tokens to reduce temporal resolution, or treat videos as unsegmented streams, which obscures fine-grained event boundaries and limits the modeling of causal dependencies. We propose TEMPURA (Temporal Event Masked Prediction and Understanding for Reasoning in Action), a two-stage training framework that enhances video temporal understanding. TEMPURA first applies masked event prediction reasoning to reconstruct missing events and generate step-by-step causal explanations from dense event annotations, drawing inspiration from effective infilling techniques. TEMPURA then learns to perform video segmentation and dense captioning to decompose videos into non-overlapping events with detailed, timestamp-aligned descriptions. We train TEMPURA on VER, a large-scale dataset curated by us that comprises 1M training instances and 500K videos with temporally aligned event descriptions and structured reasoning steps. Experiments on temporal grounding and highlight detection benchmarks demonstrate that TEMPURA outperforms strong baseline models, confirming that integrating causal reasoning with fine-grained temporal segmentation leads to improved video understanding.
Learning from Rich Semantics and Coarse Locations for Long-tailed Object Detection
Oct 18, 2023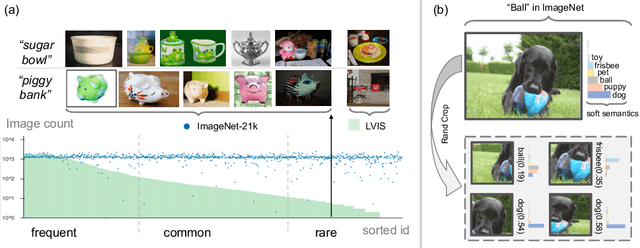
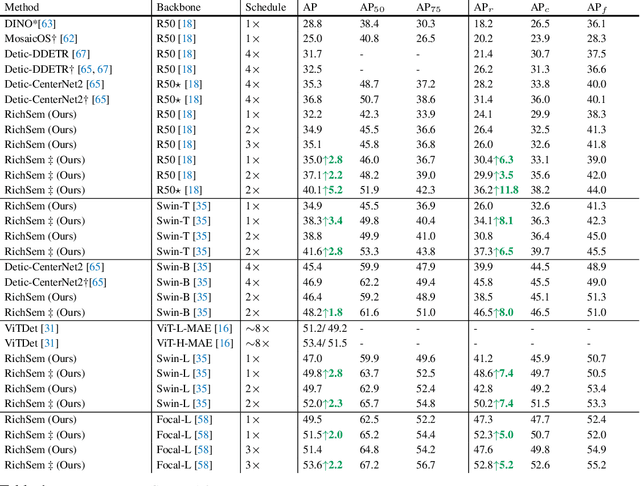
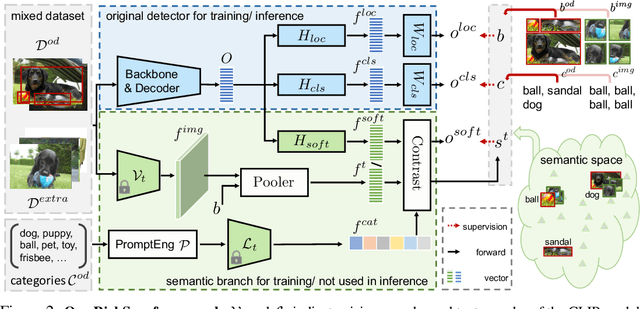
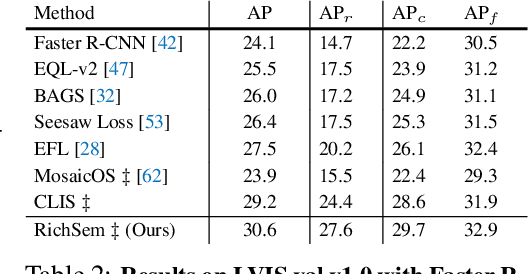
Long-tailed object detection (LTOD) aims to handle the extreme data imbalance in real-world datasets, where many tail classes have scarce instances. One popular strategy is to explore extra data with image-level labels, yet it produces limited results due to (1) semantic ambiguity -- an image-level label only captures a salient part of the image, ignoring the remaining rich semantics within the image; and (2) location sensitivity -- the label highly depends on the locations and crops of the original image, which may change after data transformations like random cropping. To remedy this, we propose RichSem, a simple but effective method, which is robust to learn rich semantics from coarse locations without the need of accurate bounding boxes. RichSem leverages rich semantics from images, which are then served as additional soft supervision for training detectors. Specifically, we add a semantic branch to our detector to learn these soft semantics and enhance feature representations for long-tailed object detection. The semantic branch is only used for training and is removed during inference. RichSem achieves consistent improvements on both overall and rare-category of LVIS under different backbones and detectors. Our method achieves state-of-the-art performance without requiring complex training and testing procedures. Moreover, we show the effectiveness of our method on other long-tailed datasets with additional experiments. Code is available at \url{https://github.com/MengLcool/RichSem}.
i-Code V2: An Autoregressive Generation Framework over Vision, Language, and Speech Data
May 21, 2023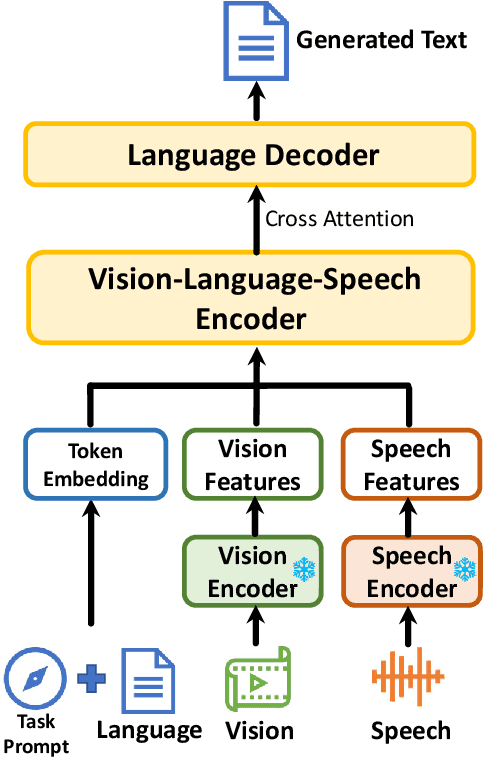
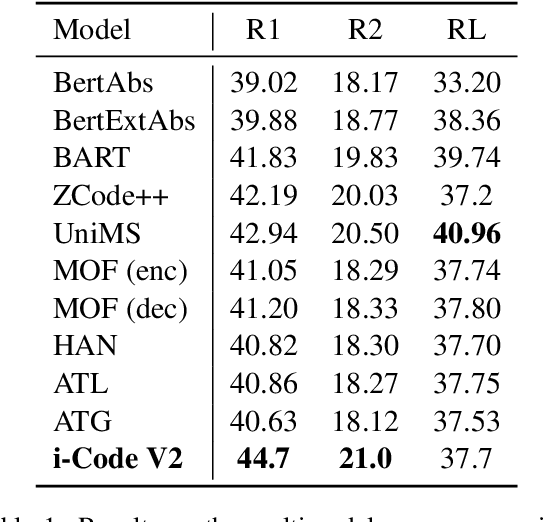
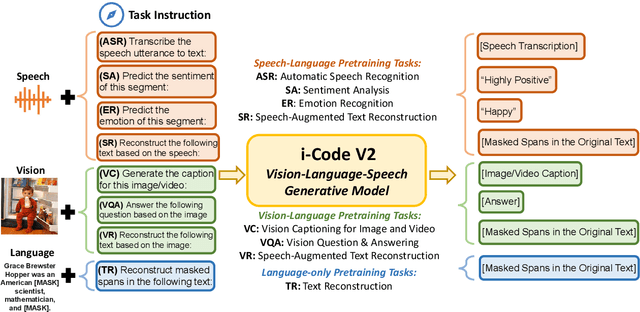

The convergence of text, visual, and audio data is a key step towards human-like artificial intelligence, however the current Vision-Language-Speech landscape is dominated by encoder-only models which lack generative abilities. We propose closing this gap with i-Code V2, the first model capable of generating natural language from any combination of Vision, Language, and Speech data. i-Code V2 is an integrative system that leverages state-of-the-art single-modality encoders, combining their outputs with a new modality-fusing encoder in order to flexibly project combinations of modalities into a shared representational space. Next, language tokens are generated from these representations via an autoregressive decoder. The whole framework is pretrained end-to-end on a large collection of dual- and single-modality datasets using a novel text completion objective that can be generalized across arbitrary combinations of modalities. i-Code V2 matches or outperforms state-of-the-art single- and dual-modality baselines on 7 multimodal tasks, demonstrating the power of generative multimodal pretraining across a diversity of tasks and signals.
Energy Efficiency Maximization in IRS-Aided Cell-Free Massive MIMO System
Dec 24, 2022



In this paper, we consider an intelligent reflecting surface (IRS)-aided cell-free massive multiple-input multiple-output system, where the beamforming at access points and the phase shifts at IRSs are jointly optimized to maximize energy efficiency (EE). To solve EE maximization problem, we propose an iterative optimization algorithm by using quadratic transform and Lagrangian dual transform to find the optimum beamforming and phase shifts. However, the proposed algorithm suffers from high computational complexity, which hinders its application in some practical scenarios. Responding to this, we further propose a deep learning based approach for joint beamforming and phase shifts design. Specifically, a two-stage deep neural network is trained offline using the unsupervised learning manner, which is then deployed online for the predictions of beamforming and phase shifts. Simulation results show that compared with the iterative optimization algorithm and the genetic algorithm, the unsupervised learning based approach has higher EE performance and lower running time.
i-Code: An Integrative and Composable Multimodal Learning Framework
May 05, 2022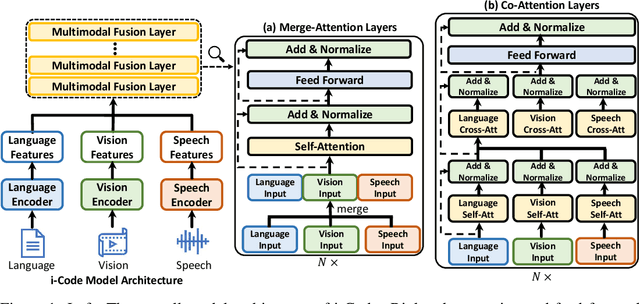
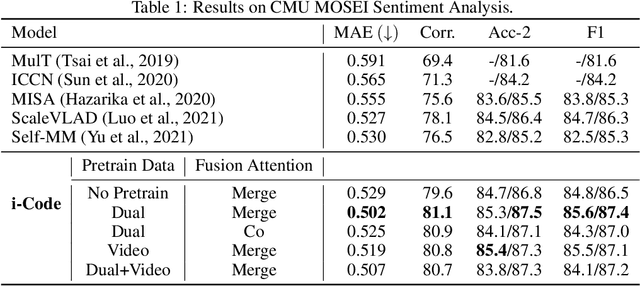
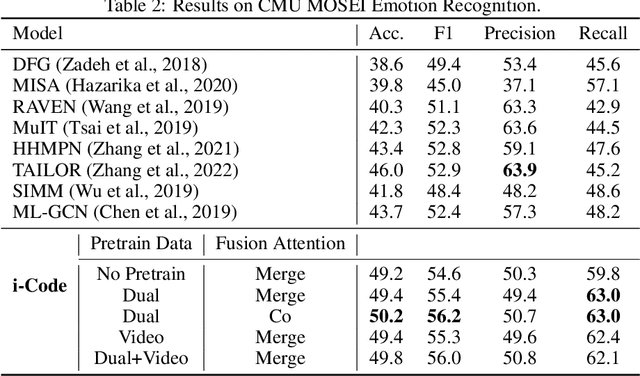

Human intelligence is multimodal; we integrate visual, linguistic, and acoustic signals to maintain a holistic worldview. Most current pretraining methods, however, are limited to one or two modalities. We present i-Code, a self-supervised pretraining framework where users may flexibly combine the modalities of vision, speech, and language into unified and general-purpose vector representations. In this framework, data from each modality are first given to pretrained single-modality encoders. The encoder outputs are then integrated with a multimodal fusion network, which uses novel attention mechanisms and other architectural innovations to effectively combine information from the different modalities. The entire system is pretrained end-to-end with new objectives including masked modality unit modeling and cross-modality contrastive learning. Unlike previous research using only video for pretraining, the i-Code framework can dynamically process single, dual, and triple-modality data during training and inference, flexibly projecting different combinations of modalities into a single representation space. Experimental results demonstrate how i-Code can outperform state-of-the-art techniques on five video understanding tasks and the GLUE NLP benchmark, improving by as much as 11% and demonstrating the power of integrative multimodal pretraining.
Florence: A New Foundation Model for Computer Vision
Nov 22, 2021
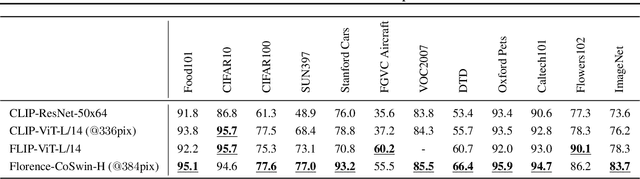
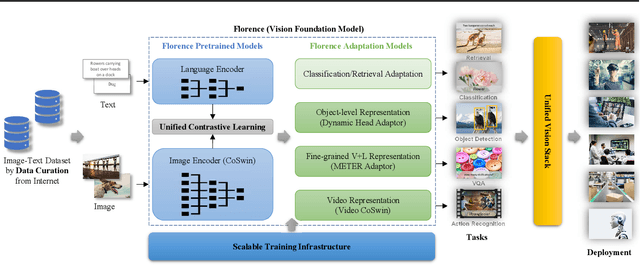
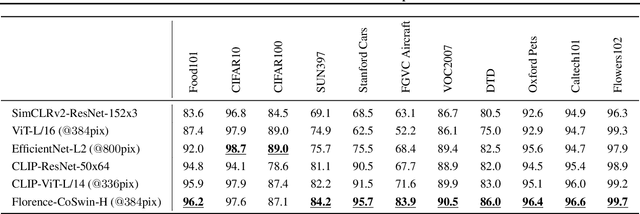
Automated visual understanding of our diverse and open world demands computer vision models to generalize well with minimal customization for specific tasks, similar to human vision. Computer vision foundation models, which are trained on diverse, large-scale dataset and can be adapted to a wide range of downstream tasks, are critical for this mission to solve real-world computer vision applications. While existing vision foundation models such as CLIP, ALIGN, and Wu Dao 2.0 focus mainly on mapping images and textual representations to a cross-modal shared representation, we introduce a new computer vision foundation model, Florence, to expand the representations from coarse (scene) to fine (object), from static (images) to dynamic (videos), and from RGB to multiple modalities (caption, depth). By incorporating universal visual-language representations from Web-scale image-text data, our Florence model can be easily adapted for various computer vision tasks, such as classification, retrieval, object detection, VQA, image caption, video retrieval and action recognition. Moreover, Florence demonstrates outstanding performance in many types of transfer learning: fully sampled fine-tuning, linear probing, few-shot transfer and zero-shot transfer for novel images and objects. All of these properties are critical for our vision foundation model to serve general purpose vision tasks. Florence achieves new state-of-the-art results in majority of 44 representative benchmarks, e.g., ImageNet-1K zero-shot classification with top-1 accuracy of 83.74 and the top-5 accuracy of 97.18, 62.4 mAP on COCO fine tuning, 80.36 on VQA, and 87.8 on Kinetics-600.
Learning to Compose with Professional Photographs on the Web
Jul 18, 2017
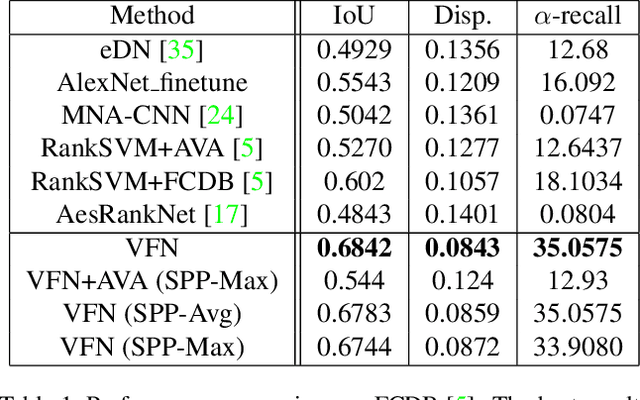

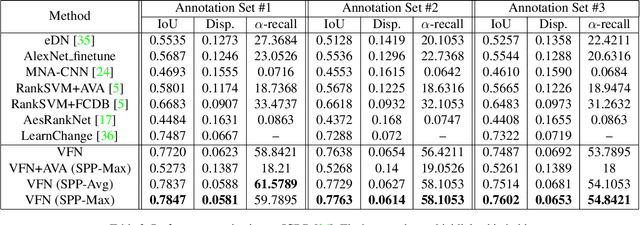
Photo composition is an important factor affecting the aesthetics in photography. However, it is a highly challenging task to model the aesthetic properties of good compositions due to the lack of globally applicable rules to the wide variety of photographic styles. Inspired by the thinking process of photo taking, we formulate the photo composition problem as a view finding process which successively examines pairs of views and determines their aesthetic preferences. We further exploit the rich professional photographs on the web to mine unlimited high-quality ranking samples and demonstrate that an aesthetics-aware deep ranking network can be trained without explicitly modeling any photographic rules. The resulting model is simple and effective in terms of its architectural design and data sampling method. It is also generic since it naturally learns any photographic rules implicitly encoded in professional photographs. The experiments show that the proposed view finding network achieves state-of-the-art performance with sliding window search strategy on two image cropping datasets.
Quantitative Analysis of Automatic Image Cropping Algorithms: A Dataset and Comparative Study
Jan 05, 2017
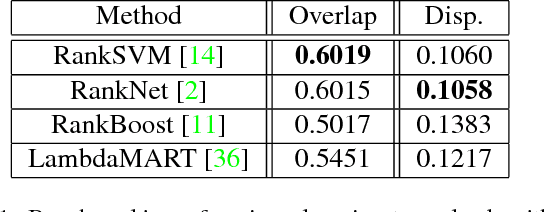

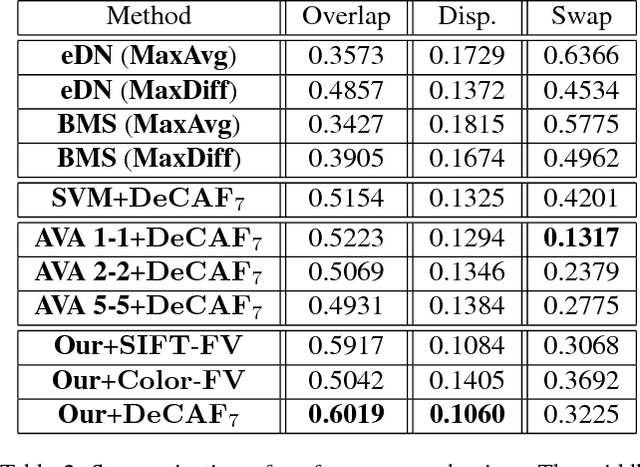
Automatic photo cropping is an important tool for improving visual quality of digital photos without resorting to tedious manual selection. Traditionally, photo cropping is accomplished by determining the best proposal window through visual quality assessment or saliency detection. In essence, the performance of an image cropper highly depends on the ability to correctly rank a number of visually similar proposal windows. Despite the ranking nature of automatic photo cropping, little attention has been paid to learning-to-rank algorithms in tackling such a problem. In this work, we conduct an extensive study on traditional approaches as well as ranking-based croppers trained on various image features. In addition, a new dataset consisting of high quality cropping and pairwise ranking annotations is presented to evaluate the performance of various baselines. The experimental results on the new dataset provide useful insights into the design of better photo cropping algorithms.