 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-Mark: An Audio Watermark Robust to Neural Resynthesis
Mar 05, 2026While existing audio watermarking techniques have achieved strong robustness against traditional digital signal processing (DSP) attacks, they remain vulnerable to neural resynthesis. This occurs because modern neural audio codecs act as semantic filters and discard the imperceptible waveform variations used in prior watermarking methods. To address this limitation, we propose Latent-Mark, the first zero-bit audio watermarking framework designed to survive semantic compression. Our key insight is that robustness to the encode-decode process requires embedding the watermark within the codec's invariant latent space. We achieve this by optimizing the audio waveform to induce a detectable directional shift in its encoded latent representation, while constraining perturbations to align with the natural audio manifold to ensure imperceptibility. To prevent overfitting to a single codec's quantization rules, we introduce Cross-Codec Optimization, jointly optimizing the waveform across multiple surrogate codecs to target shared latent invariants. Extensive evaluations demonstrate robust zero-shot transferability to unseen neural codecs, achieving state-of-the-art resilience against traditional DSP attacks while preserving perceptual imperceptibility. Our work inspires future research into universal watermarking frameworks capable of maintaining integrity across increasingly complex and diverse generative distortions.
GenTune: Toward Traceable Prompts to Improve Controllability of Image Refinement in Environment Design
Aug 21, 2025Environment designers in the entertainment industry create imaginative 2D and 3D scenes for games, films, and television, requiring both fine-grained control of specific details and consistent global coherence. Designers have increasingly integrated generative AI into their workflows, often relying on large language models (LLMs) to expand user prompts for text-to-image generation, then iteratively refining those prompts and applying inpainting. However, our formative study with 10 designers surfaced two key challenges: (1) the lengthy LLM-generated prompts make it difficult to understand and isolate the keywords that must be revised for specific visual elements; and (2) while inpainting supports localized edits, it can struggle with global consistency and correctness. Based on these insights, we present GenTune, an approach that enhances human--AI collaboration by clarifying how AI-generated prompts map to image content. Our GenTune system lets designers select any element in a generated image, trace it back to the corresponding prompt labels, and revise those labels to guide precise yet globally consistent image refinement. In a summative study with 20 designers, GenTune significantly improved prompt--image comprehension, refinement quality, and efficiency, and overall satisfaction (all $p < .01$) compared to current practice. A follow-up field study with two studios further demonstrated its effectiveness in real-world settings.
AutoSketch: VLM-assisted Style-Aware Vector Sketch Completion
Feb 07, 2025



The ability to automatically complete a partial sketch that depicts a complex scene, e.g., "a woman chatting with a man in the park", is very useful. However, existing sketch generation methods create sketches from scratch; they do not complete a partial sketch in the style of the original. To address this challenge, we introduce AutoSketch, a styleaware vector sketch completion method that accommodates diverse sketch styles. Our key observation is that the style descriptions of a sketch in natural language preserve the style during automatic sketch completion. Thus, we use a pretrained vision-language model (VLM) to describe the styles of the partial sketches in natural language and replicate these styles using newly generated strokes. We initially optimize the strokes to match an input prompt augmented by style descriptions extracted from the VLM. Such descriptions allow the method to establish a diffusion prior in close alignment with that of the partial sketch. Next, we utilize the VLM to generate an executable style adjustment code that adjusts the strokes to conform to the desired style. We compare our method with existing methods across various sketch styles and prompts, performed extensive ablation studies and qualitative and quantitative evaluations, and demonstrate that AutoSketch can support various sketch scenarios.
Sound Unblending: Exploring Sound Manipulations for Accessible Mixed-Reality Awareness
Jan 20, 2024



Mixed-reality (MR) soundscapes blend real-world sound with virtual audio from hearing devices, presenting intricate auditory information that is hard to discern and differentiate. This is particularly challenging for blind or visually impaired individuals, who rely on sounds and descriptions in their everyday lives. To understand how complex audio information is consumed, we analyzed online forum posts within the blind community, identifying prevailing challenges, needs, and desired solutions. We synthesized the results and proposed Sound Unblending for increasing MR sound awareness, which includes six sound manipulations: Ambience Builder, Feature Shifter, Earcon Generator, Prioritizer, Spatializer, and Stylizer. To evaluate the effectiveness of sound unblending, we conducted a user study with 18 blind participants across three simulated MR scenarios, where participants identified specific sounds within intricate soundscapes. We found that sound unblending increased MR sound awareness and minimized cognitive load. Finally, we developed three real-world example applications to demonstrate the practicality of sound unblending.
NeRF-In: Free-Form NeRF Inpainting with RGB-D Priors
Jun 10, 2022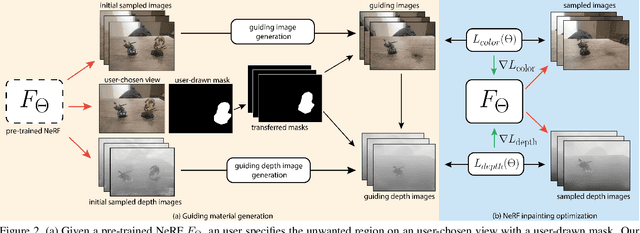


Though Neural Radiance Field (NeRF) demonstrates compelling novel view synthesis results, it is still unintuitive to edit a pre-trained NeRF because the neural network's parameters and the scene geometry/appearance are often not explicitly associated. In this paper, we introduce the first framework that enables users to remove unwanted objects or retouch undesired regions in a 3D scene represented by a pre-trained NeRF without any category-specific data and training. The user first draws a free-form mask to specify a region containing unwanted objects over a rendered view from the pre-trained NeRF. Our framework first transfers the user-provided mask to other rendered views and estimates guiding color and depth images within these transferred masked regions. Next, we formulate an optimization problem that jointly inpaints the image content in all masked regions across multiple views by updating the NeRF model's parameters. We demonstrate our framework on diverse scenes and show it obtained visual plausible and structurally consistent results across multiple views using shorter time and less user manual efforts.
StylePart: Image-based Shape Part Manipulation
Nov 23, 2021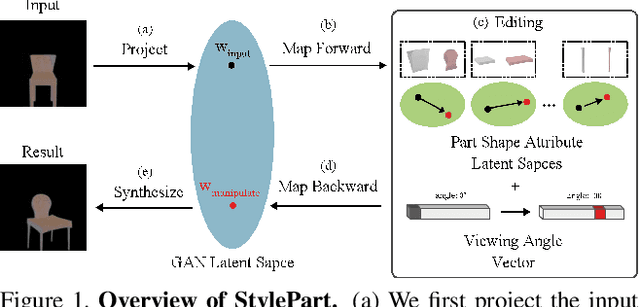
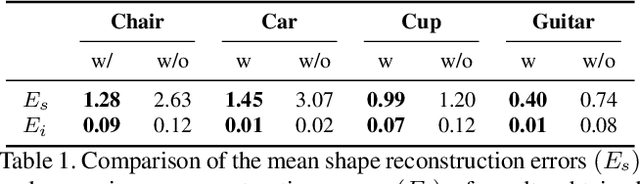
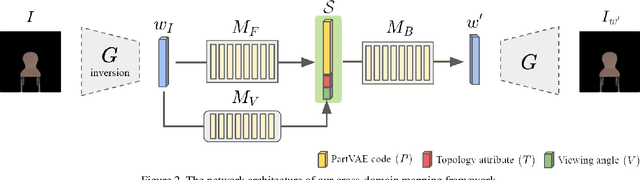

Due to a lack of image-based "part controllers", shape manipulation of man-made shape images, such as resizing the backrest of a chair or replacing a cup handle is not intuitive. To tackle this problem, we present StylePart, a framework that enables direct shape manipulation of an image by leveraging generative models of both images and 3D shapes. Our key contribution is a shape-consistent latent mapping function that connects the image generative latent space and the 3D man-made shape attribute latent space. Our method "forwardly maps" the image content to its corresponding 3D shape attributes, where the shape part can be easily manipulated. The attribute codes of the manipulated 3D shape are then "backwardly mapped" to the image latent code to obtain the final manipulated image. We demonstrate our approach through various manipulation tasks, including part replacement, part resizing, and viewpoint manipulation, and evaluate its effectiveness through extensive ablation studies.
FishNet: A Camera Localizer using Deep Recurrent Networks
Apr 22, 2019
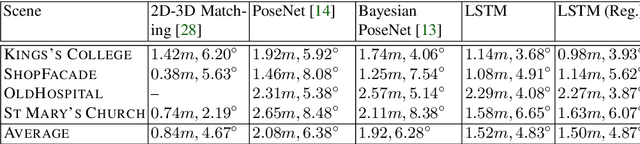
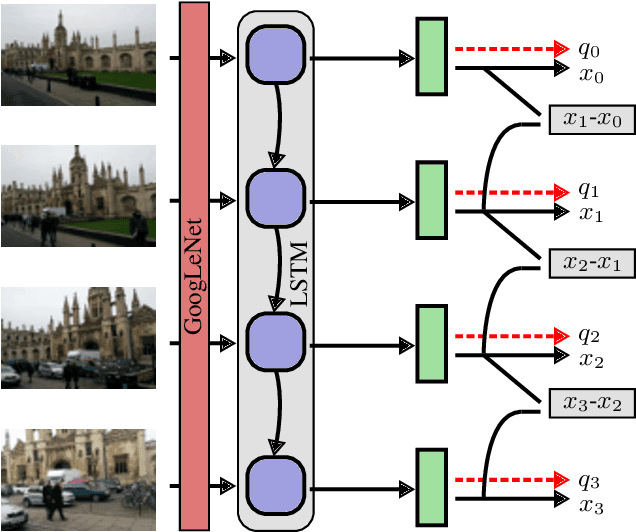
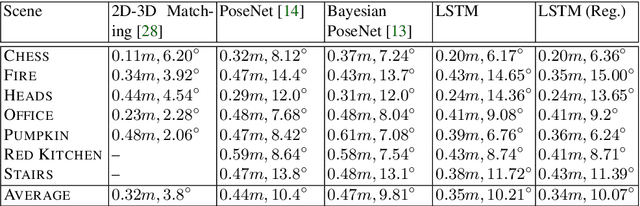
This paper proposes a robust localization system that employs deep learning for better scene representation, and enhances the accuracy of 6-DOF camera pose estimation. Inspired by the fact that global scene structure can be revealed by wide field-of-view, we leverage the large overlap of a fisheye camera between adjacent frames, and the powerful high-level feature representations of deep learning. Our main contribution is the novel network architecture that extracts both temporal and spatial information using a Recurrent Neural Network. Specifically, we propose a novel pose regularization term combined with LSTM. This leads to smoother pose estimation, especially for large outdoor scenery. Promising experimental results on three benchmark datasets manifest the effectiveness of the proposed approach.
Transferring Deep Reinforcement Learning with Adversarial Objective and Augmentation
Sep 04, 2018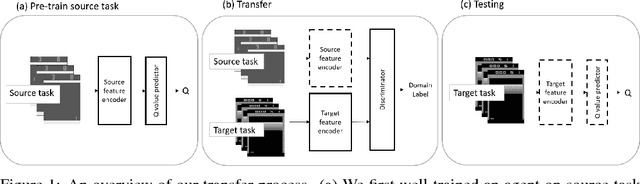

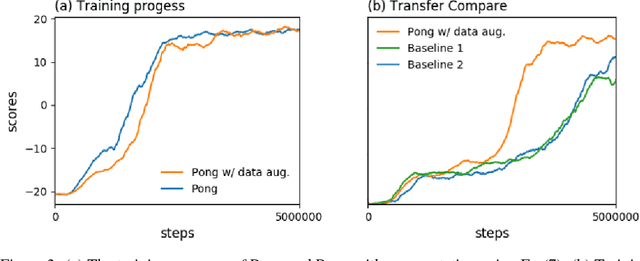
In the past few years, deep reinforcement learning has been proven to solve problems which have complex states like video games or board games. The next step of intelligent agents would be able to generalize between tasks, and using prior experience to pick up new skills more quickly. However, most reinforcement learning algorithms for now are often suffering from catastrophic forgetting even when facing a very similar target task. Our approach enables the agents to generalize knowledge from a single source task, and boost the learning progress with a semisupervised learning method when facing a new task. We evaluate this approach on Atari games, which is a popular reinforcement learning benchmark, and show that it outperforms common baselines based on pre-training and fine-tuning.
Quantitative Analysis of Automatic Image Cropping Algorithms: A Dataset and Comparative Study
Jan 05, 2017
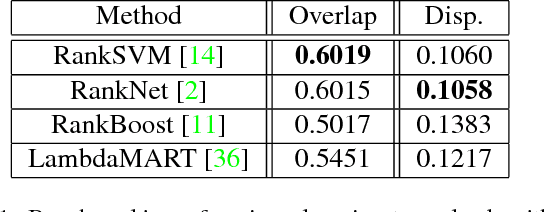

Automatic photo cropping is an important tool for improving visual quality of digital photos without resorting to tedious manual selection. Traditionally, photo cropping is accomplished by determining the best proposal window through visual quality assessment or saliency detection. In essence, the performance of an image cropper highly depends on the ability to correctly rank a number of visually similar proposal windows. Despite the ranking nature of automatic photo cropping, little attention has been paid to learning-to-rank algorithms in tackling such a problem. In this work, we conduct an extensive study on traditional approaches as well as ranking-based croppers trained on various image features. In addition, a new dataset consisting of high quality cropping and pairwise ranking annotations is presented to evaluate the performance of various baselines. The experimental results on the new dataset provide useful insights into the design of better photo cropping algorithms.
Descriptor Ensemble: An Unsupervised Approach to Descriptor Fusion in the Homography Space
Dec 13, 2014
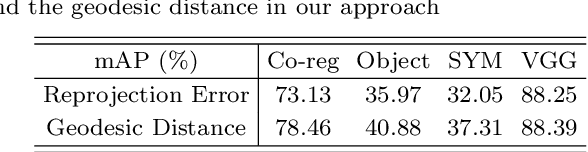

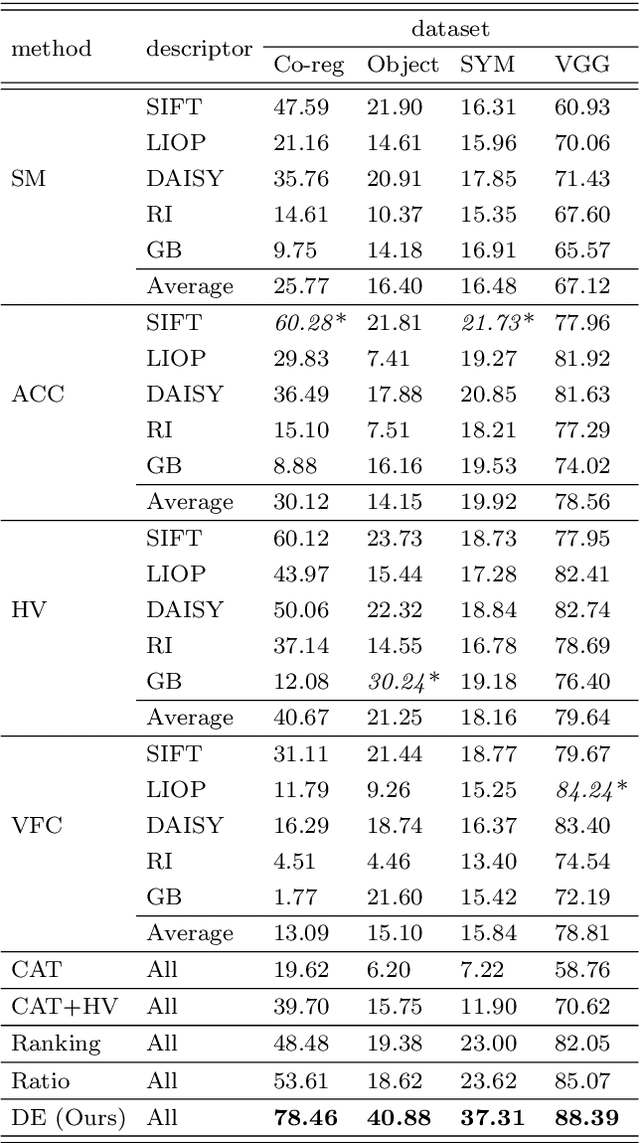
With the aim to improve the performance of feature matching, we present an unsupervised approach to fuse various local descriptors in the space of homographies. Inspired by the observation that the homographies of correct feature correspondences vary smoothly along the spatial domain, our approach stands on the unsupervised nature of feature matching, and can select a good descriptor for matching each feature point. Specifically, the homography space serves as the common domain, in which a correspondence obtained by any descriptor is considered as a point, for integrating various heterogeneous descriptors. Both geometric coherence and spatial continuity among correspondences are considered via computing their geodesic distances in the space. In this way, mutual verification across different descriptors is allowed, and correct correspondences will be highlighted with a high degree of consistency (i.e., short geodesic distances here). It follows that one-class SVM can be applied to identifying these correct correspondences, and boosts the performance of feature matching. The proposed approach is comprehensively compared with the state-of-the-art approaches, and evaluated on four benchmarks of image matching. The promising results manifest its effectiveness.