 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-Kernel Convolutional LSTM Networks and an Attention-Based Mechanism for Videos
Jul 30, 2019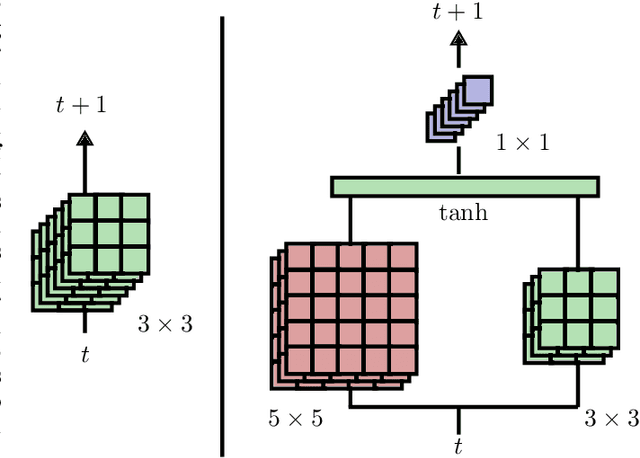
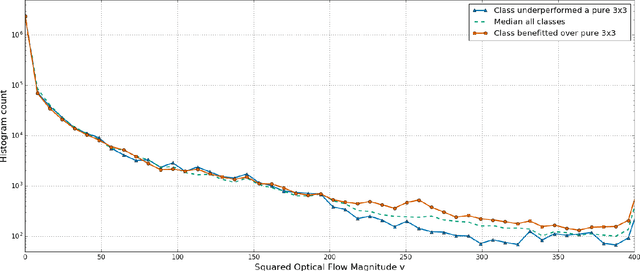
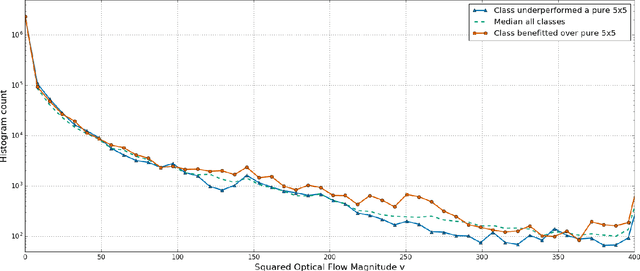
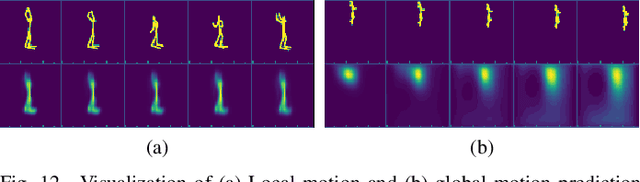
Action recognition greatly benefits motion understanding in video analysis. Recurrent networks such as long short-term memory (LSTM) networks are a popular choice for motion-aware sequence learning tasks. Recently, a convolutional extension of LSTM was proposed, in which input-to-hidden and hidden-to-hidden transitions are modeled through convolution with a single kernel. This implies an unavoidable trade-off between effectiveness and efficiency. Herein, we propose a new enhancement to convolutional LSTM networks that supports accommodation of multiple convolutional kernels and layers. This resembles a Network-in-LSTM approach, which improves upon the aforementioned concern. In addition, we propose an attention-based mechanism that is specifically designed for our multi-kernel extension. We evaluated our proposed extensions in a supervised classification setting on the UCF-101 and Sports-1M datasets, with the findings showing that our enhancements improve accuracy. We also undertook qualitative analysis to reveal the characteristics of our system and the convolutional LSTM baseline.
FishNet: A Camera Localizer using Deep Recurrent Networks
Apr 22, 2019
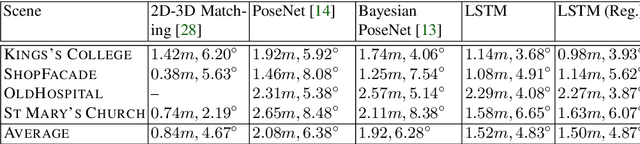
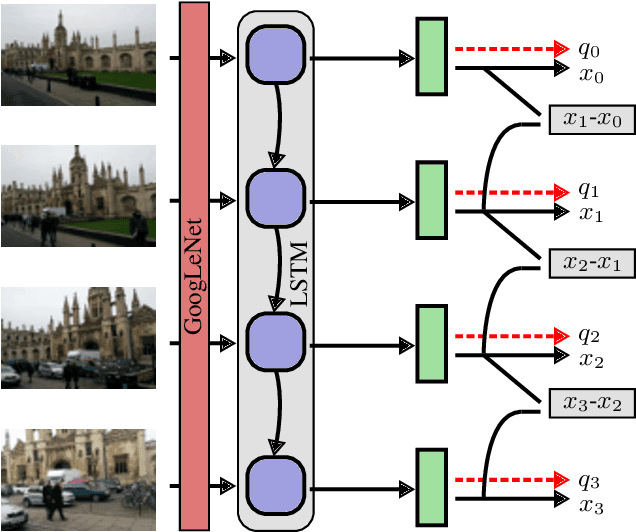
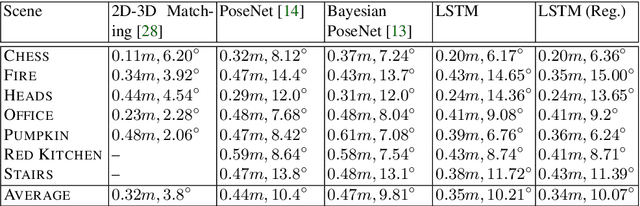
This paper proposes a robust localization system that employs deep learning for better scene representation, and enhances the accuracy of 6-DOF camera pose estimation. Inspired by the fact that global scene structure can be revealed by wide field-of-view, we leverage the large overlap of a fisheye camera between adjacent frames, and the powerful high-level feature representations of deep learning. Our main contribution is the novel network architecture that extracts both temporal and spatial information using a Recurrent Neural Network. Specifically, we propose a novel pose regularization term combined with LSTM. This leads to smoother pose estimation, especially for large outdoor scenery. Promising experimental results on three benchmark datasets manifest the effectiveness of the proposed approach.
Semi-supervised Learning for Convolutional Neural Networks via Online Graph Construction
Jan 19, 2016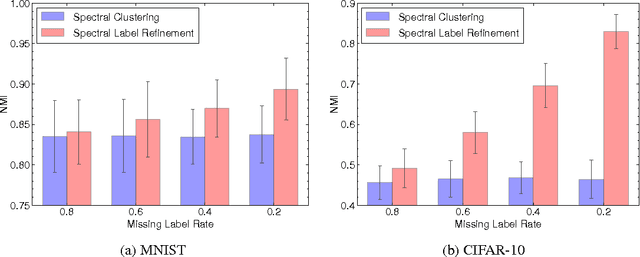
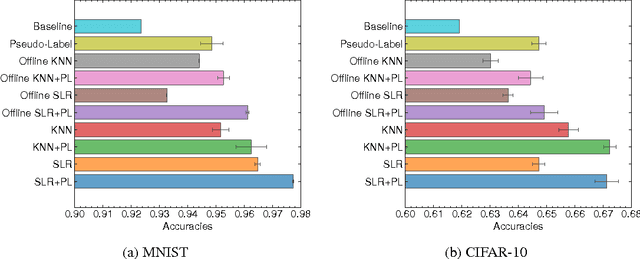
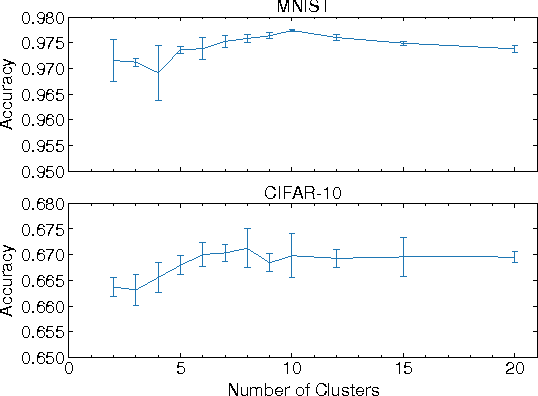
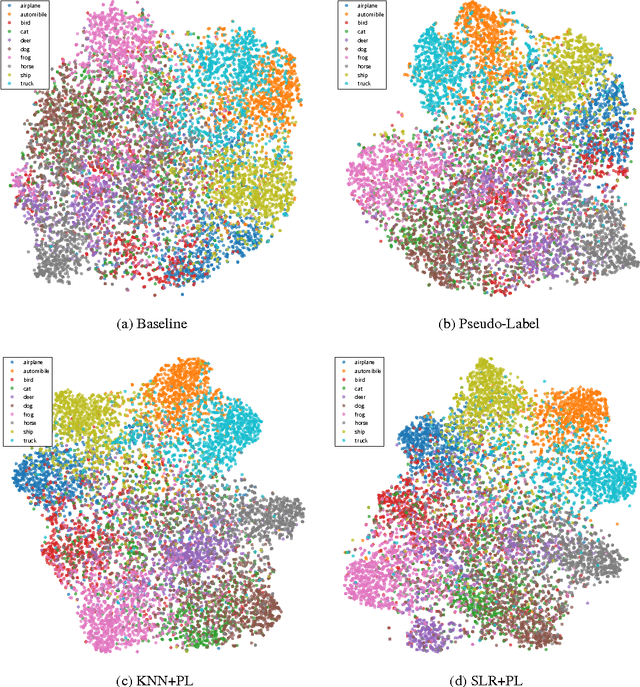
The recent promising achievements of deep learning rely on the large amount of labeled data. Considering the abundance of data on the web, most of them do not have labels at all. Therefore, it is important to improve generalization performance using unlabeled data on supervised tasks with few labeled instances. In this work, we revisit graph-based semi-supervised learning algorithms and propose an online graph construction technique which suits deep convolutional neural network better. We consider an EM-like algorithm for semi-supervised learning on deep neural networks: In forward pass, the graph is constructed based on the network output, and the graph is then used for loss calculation to help update the network by back propagation in the backward pass. We demonstrate the strength of our online approach compared to the conventional ones whose graph is constructed on static but not robust enough feature representations beforehand.
Mediated Experts for Deep Convolutional Networks
Nov 19, 2015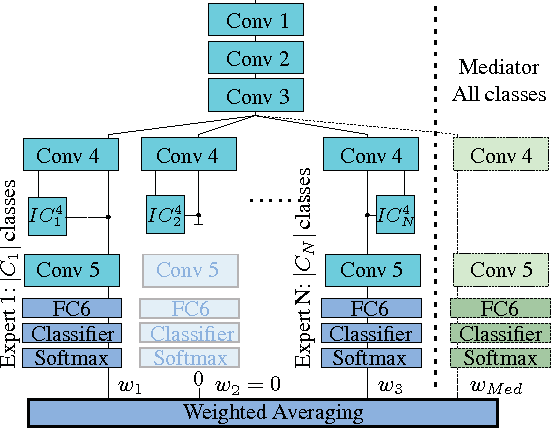
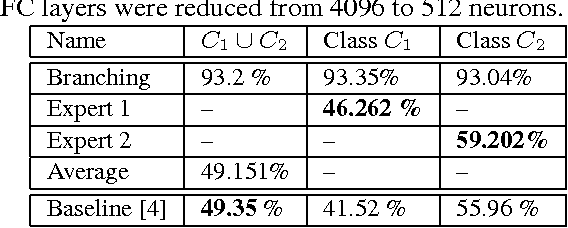
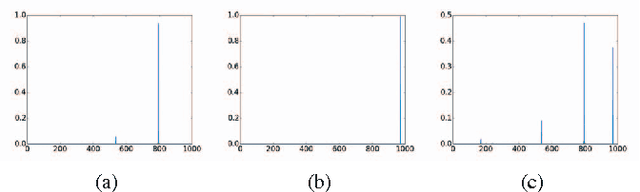
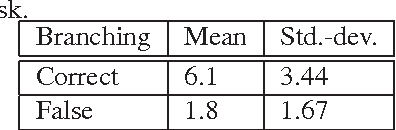
We present a new supervised architecture termed Mediated Mixture-of-Experts (MMoE) that allows us to improve classification accuracy of Deep Convolutional Networks (DCN). Our architecture achieves this with the help of expert networks: A network is trained on a disjoint subset of a given dataset and then run in parallel to other experts during deployment. A mediator is employed if experts contradict each other. This allows our framework to naturally support incremental learning, as adding new classes requires (re-)training of the new expert only. We also propose two measures to control computational complexity: An early-stopping mechanism halts experts that have low confidence in their prediction. The system allows to trade-off accuracy and complexity without further retraining. We also suggest to share low-level convolutional layers between experts in an effort to avoid computation of a near-duplicate feature set. We evaluate our system on a popular dataset and report improved accuracy compared to a single model of same configuration.