 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgramAlly: Creating Custom Visual Access Programs via Multi-Modal End-User Programming
Aug 20, 2024
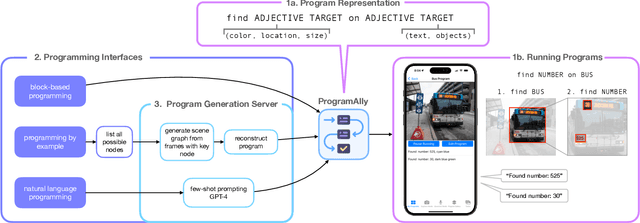

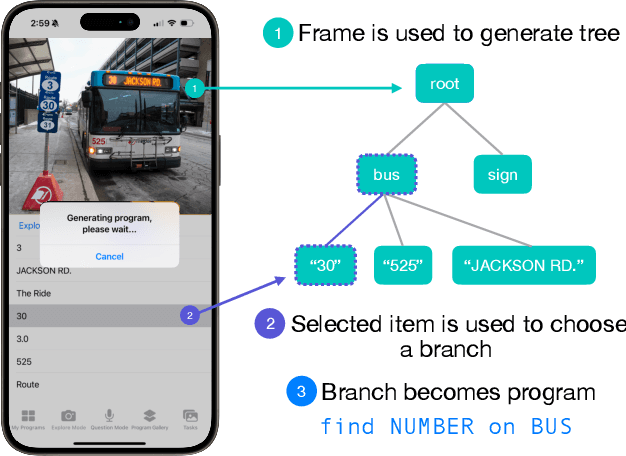
Existing visual assistive technologies are built for simple and common use cases, and have few avenues for blind people to customize their functionalities. Drawing from prior work on DIY assistive technology, this paper investigates end-user programming as a means for users to create and customize visual access programs to meet their unique needs. We introduce ProgramAlly, a system for creating custom filters for visual information, e.g., 'find NUMBER on BUS', leveraging three end-user programming approaches: block programming, natural language, and programming by example. To implement ProgramAlly, we designed a representation of visual filtering tasks based on scenarios encountered by blind people, and integrated a set of on-device and cloud models for generating and running these programs. In user studies with 12 blind adults, we found that participants preferred different programming modalities depending on the task, and envisioned using visual access programs to address unique accessibility challenges that are otherwise difficult with existing applications. Through ProgramAlly, we present an exploration of how blind end-users can create visual access programs to customize and control their experiences.
VRCopilot: Authoring 3D Layouts with Generative AI Models in VR
Aug 18, 2024
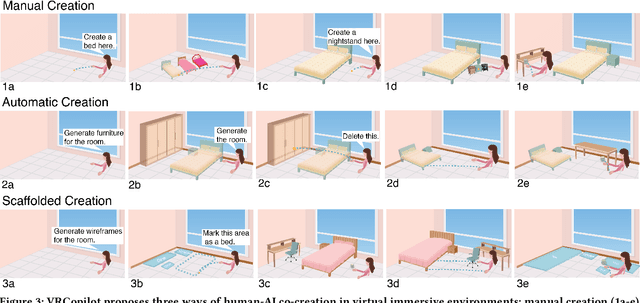
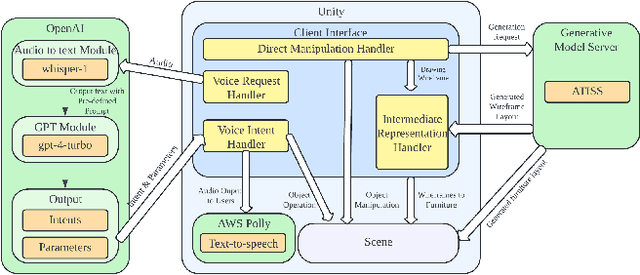

Immersive authoring provides an intuitive medium for users to create 3D scenes via direct manipulation in Virtual Reality (VR). Recent advances in generative AI have enabled the automatic creation of realistic 3D layouts. However, it is unclear how capabilities of generative AI can be used in immersive authoring to support fluid interactions, user agency, and creativity. We introduce VRCopilot, a mixed-initiative system that integrates pre-trained generative AI models into immersive authoring to facilitate human-AI co-creation in VR. VRCopilot presents multimodal interactions to support rapid prototyping and iterations with AI, and intermediate representations such as wireframes to augment user controllability over the created content. Through a series of user studies, we evaluated the potential and challenges in manual, scaffolded, and automatic creation in immersive authoring. We found that scaffolded creation using wireframes enhanced the user agency compared to automatic creation. We also found that manual creation via multimodal specification offers the highest sense of creativity and agency.
WorldScribe: Towards Context-Aware Live Visual Descriptions
Aug 13, 2024



Automated live visual descriptions can aid blind people in understanding their surroundings with autonomy and independence. However, providing descriptions that are rich, contextual, and just-in-time has been a long-standing challenge in accessibility. In this work, we develop WorldScribe, a system that generates automated live real-world visual descriptions that are customizable and adaptive to users' contexts: (i) WorldScribe's descriptions are tailored to users' intents and prioritized based on semantic relevance. (ii) WorldScribe is adaptive to visual contexts, e.g., providing consecutively succinct descriptions for dynamic scenes, while presenting longer and detailed ones for stable settings. (iii) WorldScribe is adaptive to sound contexts, e.g., increasing volume in noisy environments, or pausing when conversations start. Powered by a suite of vision, language, and sound recognition models, WorldScribe introduces a description generation pipeline that balances the tradeoffs between their richness and latency to support real-time use. The design of WorldScribe is informed by prior work on providing visual descriptions and a formative study with blind participants. Our user study and subsequent pipeline evaluation show that WorldScribe can provide real-time and fairly accurate visual descriptions to facilitate environment understanding that is adaptive and customized to users' contexts. Finally, we discuss the implications and further steps toward making live visual descriptions more context-aware and humanized.
EditScribe: Non-Visual Image Editing with Natural Language Verification Loops
Aug 13, 2024



Image editing is an iterative process that requires precise visual evaluation and manipulation for the output to match the editing intent. However, current image editing tools do not provide accessible interaction nor sufficient feedback for blind and low vision individuals to achieve this level of control. To address this, we developed EditScribe, a prototype system that makes image editing accessible using natural language verification loops powered by large multimodal models. Using EditScribe, the user first comprehends the image content through initial general and object descriptions, then specifies edit actions using open-ended natural language prompts. EditScribe performs the image edit, and provides four types of verification feedback for the user to verify the performed edit, including a summary of visual changes, AI judgement, and updated general and object descriptions. The user can ask follow-up questions to clarify and probe into the edits or verification feedback, before performing another edit. In a study with ten blind or low-vision users, we found that EditScribe supported participants to perform and verify image edit actions non-visually. We observed different prompting strategies from participants, and their perceptions on the various types of verification feedback. Finally, we discuss the implications of leveraging natural language verification loops to make visual authoring non-visually accessible.
Sound Unblending: Exploring Sound Manipulations for Accessible Mixed-Reality Awareness
Jan 20, 2024



Mixed-reality (MR) soundscapes blend real-world sound with virtual audio from hearing devices, presenting intricate auditory information that is hard to discern and differentiate. This is particularly challenging for blind or visually impaired individuals, who rely on sounds and descriptions in their everyday lives. To understand how complex audio information is consumed, we analyzed online forum posts within the blind community, identifying prevailing challenges, needs, and desired solutions. We synthesized the results and proposed Sound Unblending for increasing MR sound awareness, which includes six sound manipulations: Ambience Builder, Feature Shifter, Earcon Generator, Prioritizer, Spatializer, and Stylizer. To evaluate the effectiveness of sound unblending, we conducted a user study with 18 blind participants across three simulated MR scenarios, where participants identified specific sounds within intricate soundscapes. We found that sound unblending increased MR sound awareness and minimized cognitive load. Finally, we developed three real-world example applications to demonstrate the practicality of sound unblending.
Designing Disaggregated Evaluations of AI Systems: Choices, Considerations, and Tradeoffs
Mar 10, 2021Several pieces of work have uncovered performance disparities by conducting "disaggregated evaluations" of AI systems. We build on these efforts by focusing on the choices that must be made when designing a disaggregated evaluation, as well as some of the key considerations that underlie these design choices and the tradeoffs between these considerations. We argue that a deeper understanding of the choices, considerations, and tradeoffs involved in designing disaggregated evaluations will better enable researchers, practitioners, and the public to understand the ways in which AI systems may be underperforming for particular groups of people.
StateLens: A Reverse Engineering Solution for Making Existing Dynamic Touchscreens Accessible
Aug 20, 2019

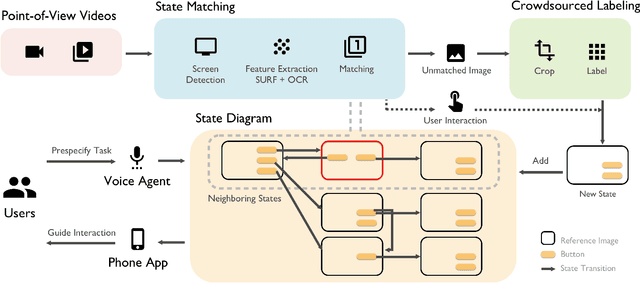
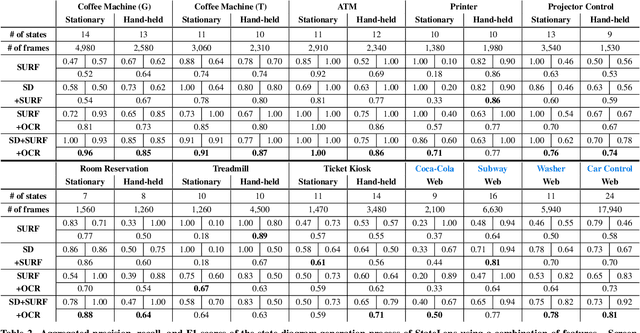
Blind people frequently encounter inaccessible dynamic touchscreens in their everyday lives that are difficult, frustrating, and often impossible to use independently. Touchscreens are often the only way to control everything from coffee machines and payment terminals, to subway ticket machines and in-flight entertainment systems. Interacting with dynamic touchscreens is difficult non-visually because the visual user interfaces change, interactions often occur over multiple different screens, and it is easy to accidentally trigger interface actions while exploring the screen. To solve these problems, we introduce StateLens - a three-part reverse engineering solution that makes existing dynamic touchscreens accessible. First, StateLens reverse engineers the underlying state diagrams of existing interfaces using point-of-view videos found online or taken by users using a hybrid crowd-computer vision pipeline. Second, using the state diagrams, StateLens automatically generates conversational agents to guide blind users through specifying the tasks that the interface can perform, allowing the StateLens iOS application to provide interactive guidance and feedback so that blind users can access the interface. Finally, a set of 3D-printed accessories enable blind people to explore capacitive touchscreens without the risk of triggering accidental touches on the interface. Our technical evaluation shows that StateLens can accurately reconstruct interfaces from stationary, hand-held, and web videos; and, a user study of the complete system demonstrates that StateLens successfully enables blind users to access otherwise inaccessible dynamic touchscreens.
Toward Fairness in AI for People with Disabilities: A Research Roadmap
Aug 02, 2019AI technologies have the potential to dramatically impact the lives of people with disabilities (PWD). Indeed, improving the lives of PWD is a motivator for many state-of-the-art AI systems, such as automated speech recognition tools that can caption videos for people who are deaf and hard of hearing, or language prediction algorithms that can augment communication for people with speech or cognitive disabilities. However, widely deployed AI systems may not work properly for PWD, or worse, may actively discriminate against them. These considerations regarding fairness in AI for PWD have thus far received little attention. In this position paper, we identify potential areas of concern regarding how several AI technology categories may impact particular disability constituencies if care is not taken in their design, development, and testing. We intend for this risk assessment of how various classes of AI might interact with various classes of disability to provide a roadmap for future research that is needed to gather data, test these hypotheses, and build more inclusive algorithms.
VizWiz Grand Challenge: Answering Visual Questions from Blind People
May 09, 2018
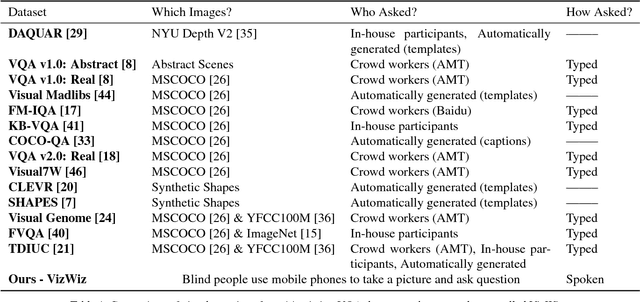

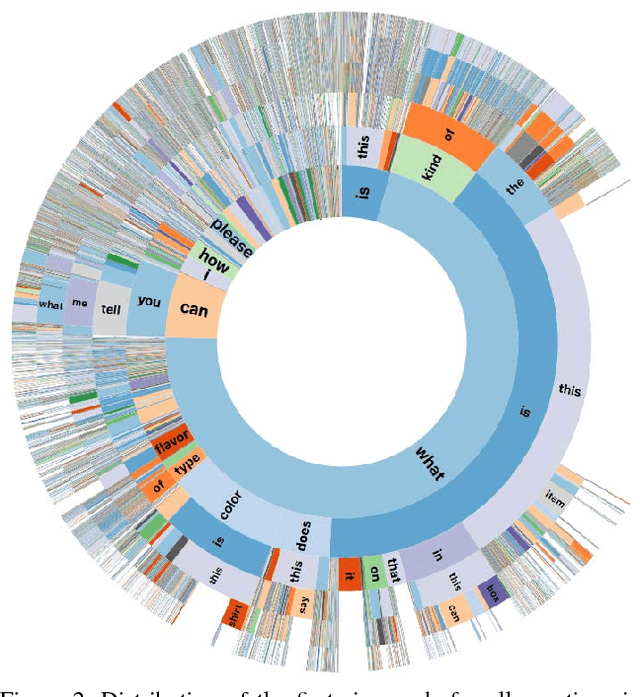
The study of algorithms to automatically answer visual questions currently is motivated by visual question answering (VQA) datasets constructed in artificial VQA settings. We propose VizWiz, the first goal-oriented VQA dataset arising from a natural VQA setting. VizWiz consists of over 31,000 visual questions originating from blind people who each took a picture using a mobile phone and recorded a spoken question about it, together with 10 crowdsourced answers per visual question. VizWiz differs from the many existing VQA datasets because (1) images are captured by blind photographers and so are often poor quality, (2) questions are spoken and so are more conversational, and (3) often visual questions cannot be answered. Evaluation of modern algorithms for answering visual questions and deciding if a visual question is answerable reveals that VizWiz is a challenging dataset. We introduce this dataset to encourage a larger community to develop more generalized algorithms that can assist blind people.