 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecForge: A Flexible and Efficient Open-Source Training Framework for Speculative Decoding
Mar 19, 2026Large language models incur high inference latency due to sequential autoregressive decoding. Speculative decoding alleviates this bottleneck by using a lightweight draft model to propose multiple tokens for batched verification. However, its adoption has been limited by the lack of high-quality draft models and scalable training infrastructure. We introduce SpecForge, an open-source, production-oriented framework for training speculative decoding models with full support for EAGLE-3. SpecForge incorporates target-draft decoupling, hybrid parallelism, optimized training kernels, and integration with production-grade inference engines, enabling up to 9.9x faster EAGLE-3 training for Qwen3-235B-A22B. In addition, we release SpecBundle, a suite of production-grade EAGLE-3 draft models trained with SpecForge for mainstream open-source LLMs. Through a systematic study of speculative decoding training recipes, SpecBundle addresses the scarcity of high-quality drafts in the community, and our draft models achieve up to 4.48x end-to-end inference speedup on SGLang, establishing SpecForge as a practical foundation for real-world speculative decoding deployment.
Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks
Jan 08, 2026We introduce enhanced Constitutional Classifiers that deliver production-grade jailbreak robustness with dramatically reduced computational costs and refusal rates compared to previous-generation defenses. Our system combines several key insights. First, we develop exchange classifiers that evaluate model responses in their full conversational context, which addresses vulnerabilities in last-generation systems that examine outputs in isolation. Second, we implement a two-stage classifier cascade where lightweight classifiers screen all traffic and escalate only suspicious exchanges to more expensive classifiers. Third, we train efficient linear probe classifiers and ensemble them with external classifiers to simultaneously improve robustness and reduce computational costs. Together, these techniques yield a production-grade system achieving a 40x computational cost reduction compared to our baseline exchange classifier, while maintaining a 0.05% refusal rate on production traffic. Through extensive red-teaming comprising over 1,700 hours, we demonstrate strong protection against universal jailbreaks -- no attack on this system successfully elicited responses to all eight target queries comparable in detail to an undefended model. Our work establishes Constitutional Classifiers as practical and efficient safeguards for large language models.
Corrective Diffusion Language Models
Dec 17, 2025
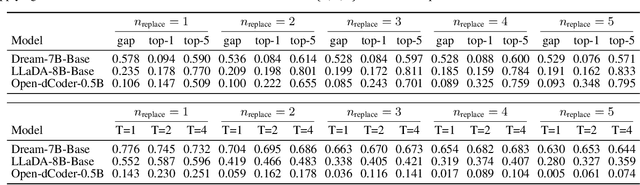
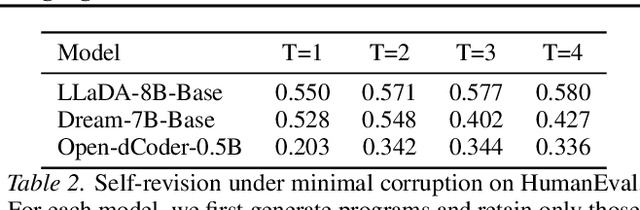
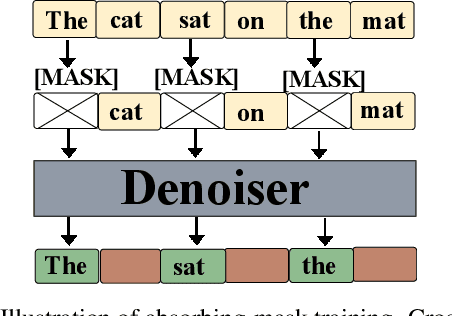
Diffusion language models are structurally well-suited for iterative error correction, as their non-causal denoising dynamics allow arbitrary positions in a sequence to be revised. However, standard masked diffusion language model (MDLM) training fails to reliably induce this behavior, as models often cannot identify unreliable tokens in a complete input, rendering confidence-guided refinement ineffective. We study corrective behavior in diffusion language models, defined as the ability to assign lower confidence to incorrect tokens and iteratively refine them while preserving correct content. We show that this capability is not induced by conventional masked diffusion objectives and propose a correction-oriented post-training principle that explicitly supervises visible incorrect tokens, enabling error-aware confidence and targeted refinement. To evaluate corrective behavior, we introduce the Code Revision Benchmark (CRB), a controllable and executable benchmark for assessing error localization and in-place correction. Experiments on code revision tasks and controlled settings demonstrate that models trained with our approach substantially outperform standard MDLMs in correction scenarios, while also improving pure completion performance. Our code is publicly available at https://github.com/zhangshuibai/CDLM.
Generalized Scattering Matrix Framework for Modeling Implantable Antennas in Multilayered Spherical Media
Jul 17, 2025This paper presents a unified and efficient framework for analyzing antennas embedded in spherically stratified media -- a model broadly applicable to implantable antennas in biomedical systems and radome-enclosed antennas in engineering applications. The proposed method decouples the modeling of the antenna and its surrounding medium by combining the antenna's free-space generalized scattering matrix (GSM) with a set of extended spherical scattering operators (SSOs) that rigorously capture the electromagnetic interactions with multilayered spherical environments. This decoupling enables rapid reevaluation under arbitrary material variations without re-simulating the antenna, offering substantial computational advantages over traditional dyadic Green's function (DGF)-based MoM approaches. The framework supports a wide range of spherical media, including radially inhomogeneous and uniaxially anisotropic layers. Extensive case studies demonstrate excellent agreement with full-wave and DGF-based solutions, confirming the method's accuracy, generality, and scalability. Code implementations are provided to facilitate adoption and future development.
VRCopilot: Authoring 3D Layouts with Generative AI Models in VR
Aug 18, 2024
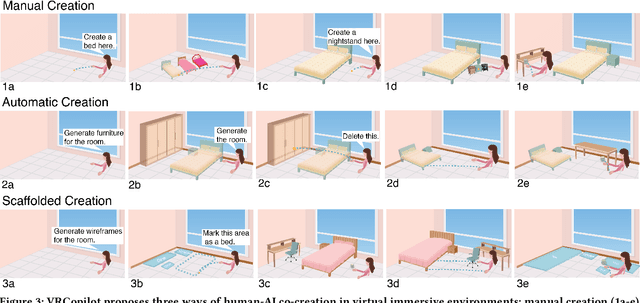
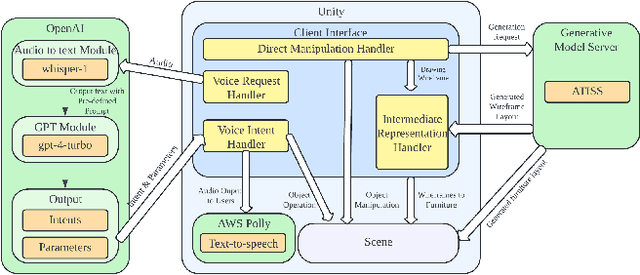

Immersive authoring provides an intuitive medium for users to create 3D scenes via direct manipulation in Virtual Reality (VR). Recent advances in generative AI have enabled the automatic creation of realistic 3D layouts. However, it is unclear how capabilities of generative AI can be used in immersive authoring to support fluid interactions, user agency, and creativity. We introduce VRCopilot, a mixed-initiative system that integrates pre-trained generative AI models into immersive authoring to facilitate human-AI co-creation in VR. VRCopilot presents multimodal interactions to support rapid prototyping and iterations with AI, and intermediate representations such as wireframes to augment user controllability over the created content. Through a series of user studies, we evaluated the potential and challenges in manual, scaffolded, and automatic creation in immersive authoring. We found that scaffolded creation using wireframes enhanced the user agency compared to automatic creation. We also found that manual creation via multimodal specification offers the highest sense of creativity and agency.
BLOS-BEV: Navigation Map Enhanced Lane Segmentation Network, Beyond Line of Sight
Jul 11, 2024



Bird's-eye-view (BEV) representation is crucial for the perception function in autonomous driving tasks. It is difficult to balance the accuracy, efficiency and range of BEV representation. The existing works are restricted to a limited perception range within 50 meters. Extending the BEV representation range can greatly benefit downstream tasks such as topology reasoning, scene understanding, and planning by offering more comprehensive information and reaction time. The Standard-Definition (SD) navigation maps can provide a lightweight representation of road structure topology, characterized by ease of acquisition and low maintenance costs. An intuitive idea is to combine the close-range visual information from onboard cameras with the beyond line-of-sight (BLOS) environmental priors from SD maps to realize expanded perceptual capabilities. In this paper, we propose BLOS-BEV, a novel BEV segmentation model that incorporates SD maps for accurate beyond line-of-sight perception, up to 200m. Our approach is applicable to common BEV architectures and can achieve excellent results by incorporating information derived from SD maps. We explore various feature fusion schemes to effectively integrate the visual BEV representations and semantic features from the SD map, aiming to leverage the complementary information from both sources optimally. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in BEV segmentation on nuScenes and Argoverse benchmark. Through multi-modal inputs, BEV segmentation is significantly enhanced at close ranges below 50m, while also demonstrating superior performance in long-range scenarios, surpassing other methods by over 20% mIoU at distances ranging from 50-200m.
A Large-Scale Dataset for Benchmarking Elevator Button Segmentation and Character Recognition
Mar 22, 2021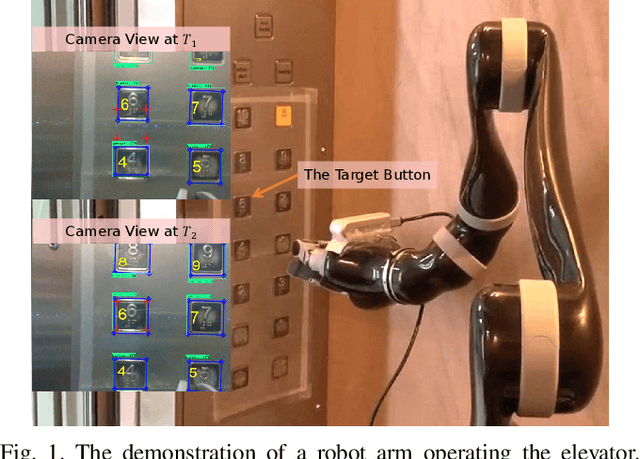
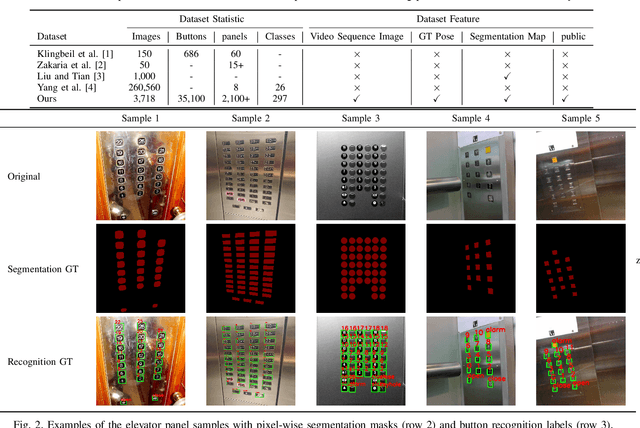
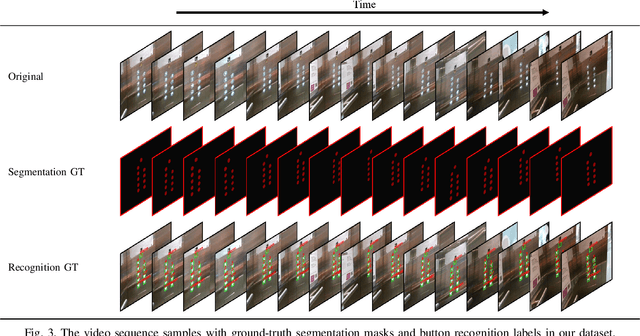
Human activities are hugely restricted by COVID-19, recently. Robots that can conduct inter-floor navigation attract much public attention, since they can substitute human workers to conduct the service work. However, current robots either depend on human assistance or elevator retrofitting, and fully autonomous inter-floor navigation is still not available. As the very first step of inter-floor navigation, elevator button segmentation and recognition hold an important position. Therefore, we release the first large-scale publicly available elevator panel dataset in this work, containing 3,718 panel images with 35,100 button labels, to facilitate more powerful algorithms on autonomous elevator operation. Together with the dataset, a number of deep learning based implementations for button segmentation and recognition are also released to benchmark future methods in the community. The dataset will be available at \url{https://github.com/zhudelong/elevator_button_recognition
Learning to Interrupt: A Hierarchical Deep Reinforcement Learning Framework for Efficient Exploration
Jul 30, 2018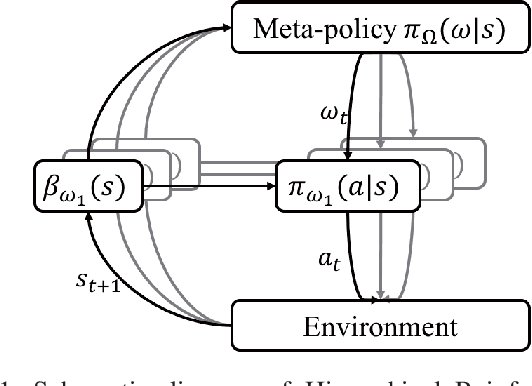
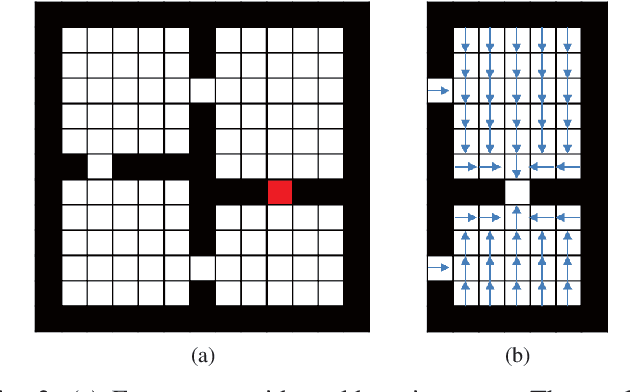
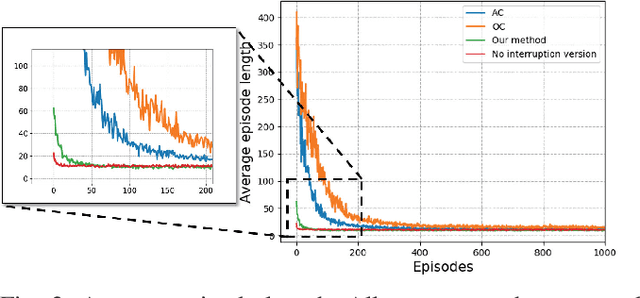
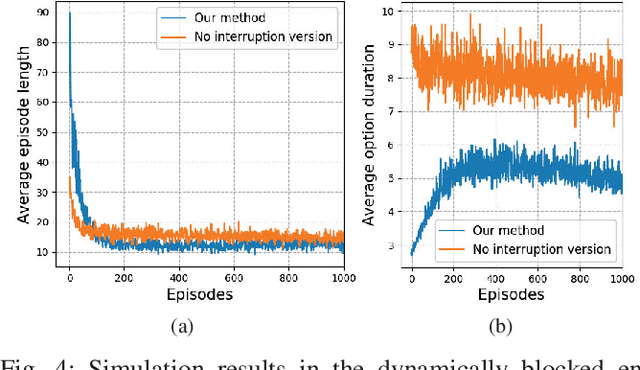
To achieve scenario intelligence, humans must transfer knowledge to robots by developing goal-oriented algorithms, which are sometimes insensitive to dynamically changing environments. While deep reinforcement learning achieves significant success recently, it is still extremely difficult to be deployed in real robots directly. In this paper, we propose a hybrid structure named Option-Interruption in which human knowledge is embedded into a hierarchical reinforcement learning framework. Our architecture has two key components: options, represented by existing human-designed methods, can significantly speed up the training process and interruption mechanism, based on learnable termination functions, enables our system to quickly respond to the external environment. To implement this architecture, we derive a set of update rules based on policy gradient methods and present a complete training process. In the experiment part, our method is evaluated in Four-room navigation and exploration task, which shows the efficiency and flexibility of our framework.