 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-LAD: Segment Anything Model Meets Zero-Shot Logic Anomaly Detection
Jun 02, 2024Visual anomaly detection is vital in real-world applications, such as industrial defect detection and medical diagnosis. However, most existing methods focus on local structural anomalies and fail to detect higher-level functional anomalies under logical conditions. Although recent studies have explored logical anomaly detection, they can only address simple anomalies like missing or addition and show poor generalizability due to being heavily data-driven. To fill this gap, we propose SAM-LAD, a zero-shot, plug-and-play framework for logical anomaly detection in any scene. First, we obtain a query image's feature map using a pre-trained backbone. Simultaneously, we retrieve the reference images and their corresponding feature maps via the nearest neighbor search of the query image. Then, we introduce the Segment Anything Model (SAM) to obtain object masks of the query and reference images. Each object mask is multiplied with the entire image's feature map to obtain object feature maps. Next, an Object Matching Model (OMM) is proposed to match objects in the query and reference images. To facilitate object matching, we further propose a Dynamic Channel Graph Attention (DCGA) module, treating each object as a keypoint and converting its feature maps into feature vectors. Finally, based on the object matching relations, an Anomaly Measurement Model (AMM) is proposed to detect objects with logical anomalies. Structural anomalies in the objects can also be detected. We validate our proposed SAM-LAD using various benchmarks, including industrial datasets (MVTec Loco AD, MVTec AD), and the logical dataset (DigitAnatomy). Extensive experimental results demonstrate that SAM-LAD outperforms existing SoTA methods, particularly in detecting logical anomalies.
UP-CrackNet: Unsupervised Pixel-Wise Road Crack Detection via Adversarial Image Restoration
Jan 28, 2024



Over the past decade, automated methods have been developed to detect cracks more efficiently, accurately, and objectively, with the ultimate goal of replacing conventional manual visual inspection techniques. Among these methods, semantic segmentation algorithms have demonstrated promising results in pixel-wise crack detection tasks. However, training such data-driven algorithms requires a large amount of human-annotated datasets with pixel-level annotations, which is a highly labor-intensive and time-consuming process. Moreover, supervised learning-based methods often struggle with poor generalization ability in unseen datasets. Therefore, we propose an unsupervised pixel-wise road crack detection network, known as UP-CrackNet. Our approach first generates multi-scale square masks and randomly selects them to corrupt undamaged road images by removing certain regions. Subsequently, a generative adversarial network is trained to restore the corrupted regions by leveraging the semantic context learned from surrounding uncorrupted regions. During the testing phase, an error map is generated by calculating the difference between the input and restored images, which allows for pixel-wise crack detection. Our comprehensive experimental results demonstrate that UP-CrackNet outperforms other general-purpose unsupervised anomaly detection algorithms, and exhibits comparable performance and superior generalizability when compared with state-of-the-art supervised crack segmentation algorithms. Our source code is publicly available at mias.group/UP-CrackNet.
Computer Vision for Road Imaging and Pothole Detection: A State-of-the-Art Review of Systems and Algorithms
Apr 28, 2022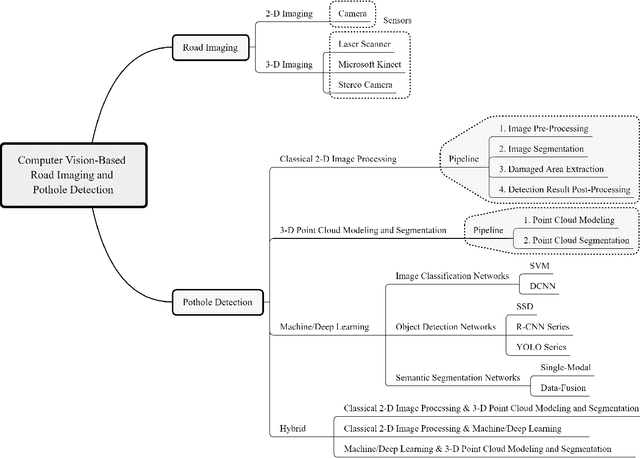
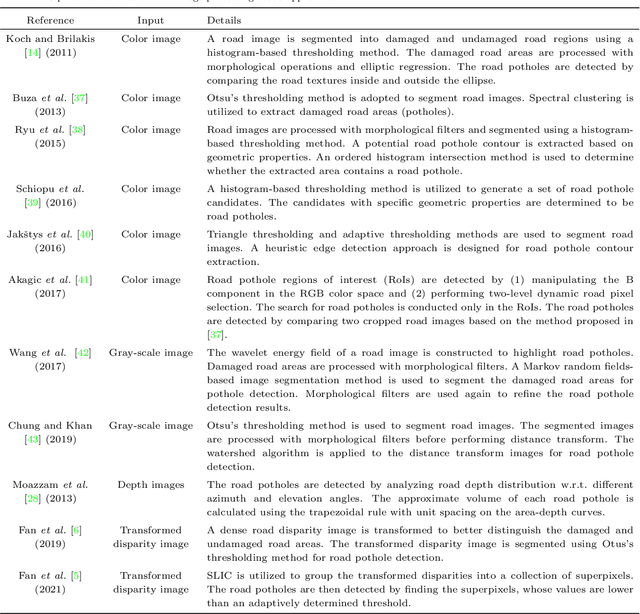

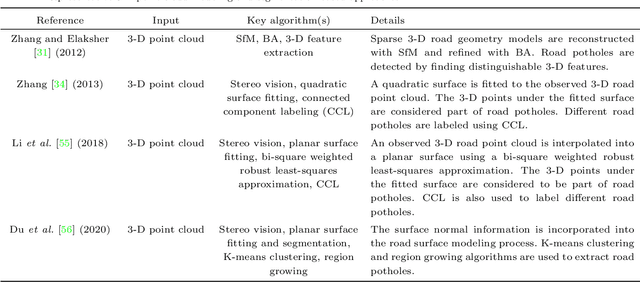
Computer vision algorithms have been prevalently utilized for 3-D road imaging and pothole detection for over two decades. Nonetheless, there is a lack of systematic survey articles on state-of-the-art (SoTA) computer vision techniques, especially deep learning models, developed to tackle these problems. This article first introduces the sensing systems employed for 2-D and 3-D road data acquisition, including camera(s), laser scanners, and Microsoft Kinect. Afterward, it thoroughly and comprehensively reviews the SoTA computer vision algorithms, including (1) classical 2-D image processing, (2) 3-D point cloud modeling and segmentation, and (3) machine/deep learning, developed for road pothole detection. This article also discusses the existing challenges and future development trends of computer vision-based road pothole detection approaches: classical 2-D image processing-based and 3-D point cloud modeling and segmentation-based approaches have already become history; and Convolutional neural networks (CNNs) have demonstrated compelling road pothole detection results and are promising to break the bottleneck with the future advances in self/un-supervised learning for multi-modal semantic segmentation. We believe that this survey can serve as practical guidance for developing the next-generation road condition assessment systems.
Deep Learning-based Biological Anatomical Landmark Detection in Colonoscopy Videos
Aug 06, 2021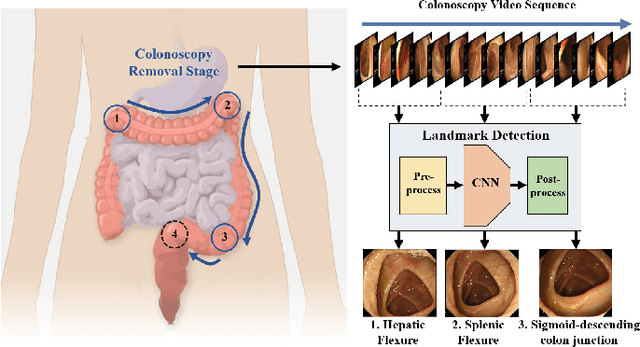

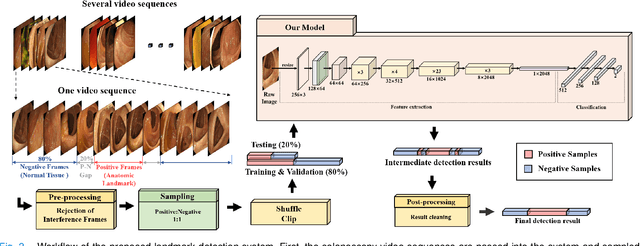
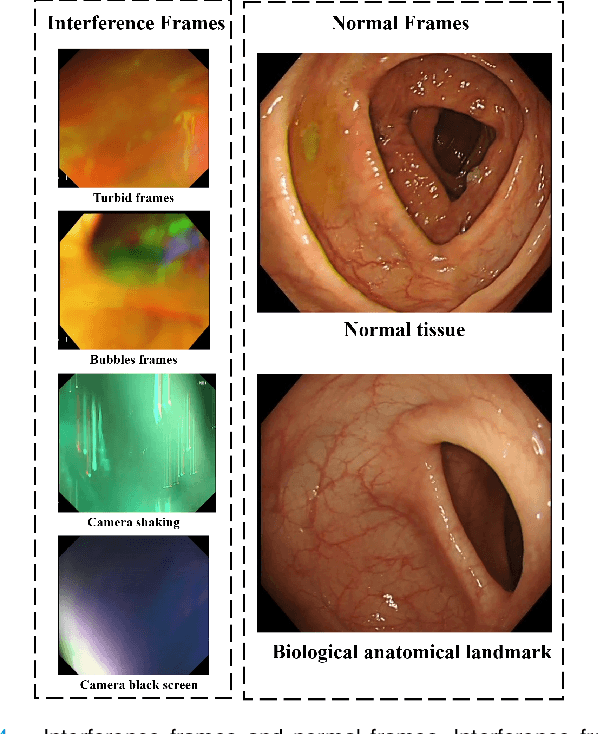
Colonoscopy is a standard imaging tool for visualizing the entire gastrointestinal (GI) tract of patients to capture lesion areas. However, it takes the clinicians excessive time to review a large number of images extracted from colonoscopy videos. Thus, automatic detection of biological anatomical landmarks within the colon is highly demanded, which can help reduce the burden of clinicians by providing guidance information for the locations of lesion areas. In this article, we propose a novel deep learning-based approach to detect biological anatomical landmarks in colonoscopy videos. First, raw colonoscopy video sequences are pre-processed to reject interference frames. Second, a ResNet-101 based network is used to detect three biological anatomical landmarks separately to obtain the intermediate detection results. Third, to achieve more reliable localization of the landmark periods within the whole video period, we propose to post-process the intermediate detection results by identifying the incorrectly predicted frames based on their temporal distribution and reassigning them back to the correct class. Finally, the average detection accuracy reaches 99.75\%. Meanwhile, the average IoU of 0.91 shows a high degree of similarity between our predicted landmark periods and ground truth. The experimental results demonstrate that our proposed model is capable of accurately detecting and localizing biological anatomical landmarks from colonoscopy videos.
A Large-Scale Dataset for Benchmarking Elevator Button Segmentation and Character Recognition
Mar 22, 2021
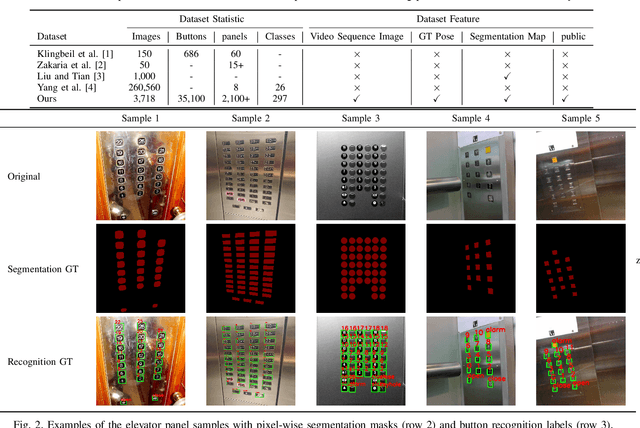
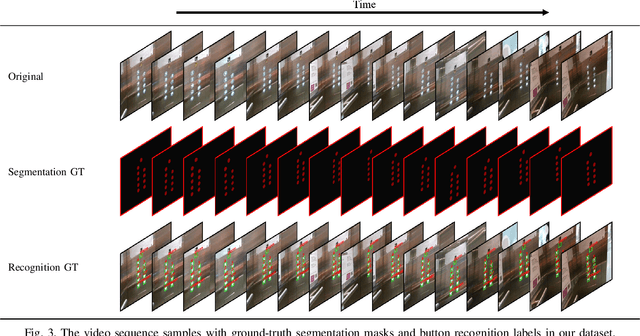
Human activities are hugely restricted by COVID-19, recently. Robots that can conduct inter-floor navigation attract much public attention, since they can substitute human workers to conduct the service work. However, current robots either depend on human assistance or elevator retrofitting, and fully autonomous inter-floor navigation is still not available. As the very first step of inter-floor navigation, elevator button segmentation and recognition hold an important position. Therefore, we release the first large-scale publicly available elevator panel dataset in this work, containing 3,718 panel images with 35,100 button labels, to facilitate more powerful algorithms on autonomous elevator operation. Together with the dataset, a number of deep learning based implementations for button segmentation and recognition are also released to benchmark future methods in the community. The dataset will be available at \url{https://github.com/zhudelong/elevator_button_recognition
Conditional Generative Adversarial Networks for Optimal Path Planning
Dec 06, 2020

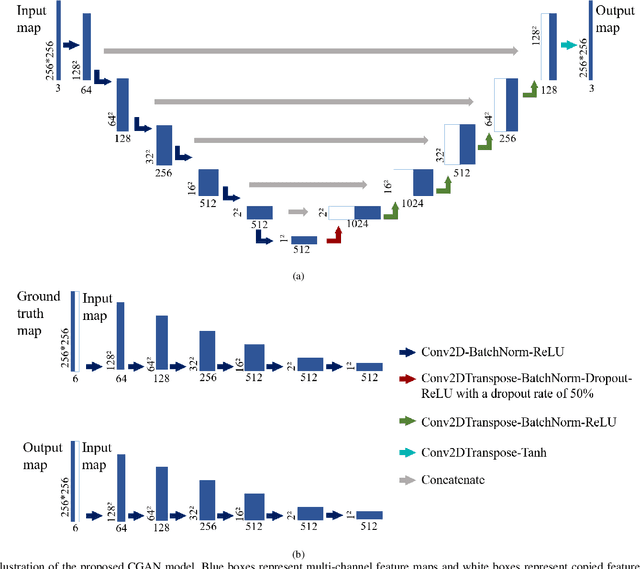

Path planning plays an important role in autonomous robot systems. Effective understanding of the surrounding environment and efficient generation of optimal collision-free path are both critical parts for solving path planning problem. Although conventional sampling-based algorithms, such as the rapidly-exploring random tree (RRT) and its improved optimal version (RRT*), have been widely used in path planning problems because of their ability to find a feasible path in even complex environments, they fail to find an optimal path efficiently. To solve this problem and satisfy the two aforementioned requirements, we propose a novel learning-based path planning algorithm which consists of a novel generative model based on the conditional generative adversarial networks (CGAN) and a modified RRT* algorithm (denoted by CGANRRT*). Given the map information, our CGAN model can generate an efficient possibility distribution of feasible paths, which can be utilized by the CGAN-RRT* algorithm to find the optimal path with a non-uniform sampling strategy. The CGAN model is trained by learning from ground truth maps, each of which is generated by putting all the results of executing RRT algorithm 50 times on one raw map. We demonstrate the efficient performance of this CGAN model by testing it on two groups of maps and comparing CGAN-RRT* algorithm with conventional RRT* algorithm.
Autonomous Removal of Perspective Distortion based on Detection Results of Robotic Elevator Button Corner
Jul 23, 2020
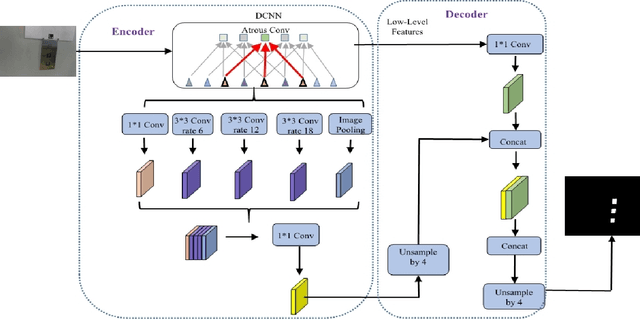


Elevator button recognition is an important function to realize the autonomous operation of elevators. However, challenging image conditions and various image distortions make it difficult to accurately recognize buttons. In this work, We propose a novel algorithm that can automatically correct perspective distortions of elevator panel images based on button corner detection results. The algorithm first leverages DeepLabv3+ model and Hough Transform method to obtain button segmentation results and button corner detection results, then utilizes pixel coordinates of standard button corners as reference features to estimate camera motions for correcting perspective distortions. The algorithm is much more robust to outliers and noise on the removal of perspective distortion than traditional geometric approaches as it only performs on a single image autonomously. 15 elevator panel images are captured from different angles of view as the dataset. The experimental results show that our approach significantly outperforms traditional geometric techniques in accuracy and robustness. Rectification results of the proposed algorithm is 77.4% better than the results of traditional geometric algorithm in average.
Autonomous Removal of Perspective Distortion for Robotic Elevator Button Recognition
Dec 26, 2019

Elevator button recognition is considered an indispensable function for enabling the autonomous elevator operation of mobile robots. However, due to unfavorable image conditions and various image distortions, the recognition accuracy remains to be improved. In this paper, we present a novel algorithm that can autonomously correct perspective distortions of elevator panel images. The algorithm first leverages the Gaussian Mixture Model (GMM) to conduct a grid fitting process based on button recognition results, then utilizes the estimated grid centers as reference features to estimate camera motions for correcting perspective distortions. The algorithm performs on a single image autonomously and does not need explicit feature detection or feature matching procedure, which is much more robust to noises and outliers than traditional feature-based geometric approaches. To verify the effectiveness of the algorithm, we collect an elevator panel dataset of 50 images captured from different angles of view. Experimental results show that the proposed algorithm can accurately estimate camera motions and effectively remove perspective distortions.