 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOS-BEV: Navigation Map Enhanced Lane Segmentation Network, Beyond Line of Sight
Jul 11, 2024



Bird's-eye-view (BEV) representation is crucial for the perception function in autonomous driving tasks. It is difficult to balance the accuracy, efficiency and range of BEV representation. The existing works are restricted to a limited perception range within 50 meters. Extending the BEV representation range can greatly benefit downstream tasks such as topology reasoning, scene understanding, and planning by offering more comprehensive information and reaction time. The Standard-Definition (SD) navigation maps can provide a lightweight representation of road structure topology, characterized by ease of acquisition and low maintenance costs. An intuitive idea is to combine the close-range visual information from onboard cameras with the beyond line-of-sight (BLOS) environmental priors from SD maps to realize expanded perceptual capabilities. In this paper, we propose BLOS-BEV, a novel BEV segmentation model that incorporates SD maps for accurate beyond line-of-sight perception, up to 200m. Our approach is applicable to common BEV architectures and can achieve excellent results by incorporating information derived from SD maps. We explore various feature fusion schemes to effectively integrate the visual BEV representations and semantic features from the SD map, aiming to leverage the complementary information from both sources optimally. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in BEV segmentation on nuScenes and Argoverse benchmark. Through multi-modal inputs, BEV segmentation is significantly enhanced at close ranges below 50m, while also demonstrating superior performance in long-range scenarios, surpassing other methods by over 20% mIoU at distances ranging from 50-200m.
MapLocNet: Coarse-to-Fine Feature Registration for Visual Re-Localization in Navigation Maps
Jul 11, 2024



Robust localization is the cornerstone of autonomous driving, especially in challenging urban environments where GPS signals suffer from multipath errors. Traditional localization approaches rely on high-definition (HD) maps, which consist of precisely annotated landmarks. However, building HD map is expensive and challenging to scale up. Given these limitations, leveraging navigation maps has emerged as a promising low-cost alternative for localization. Current approaches based on navigation maps can achieve highly accurate localization, but their complex matching strategies lead to unacceptable inference latency that fails to meet the real-time demands. To address these limitations, we propose a novel transformer-based neural re-localization method. Inspired by image registration, our approach performs a coarse-to-fine neural feature registration between navigation map and visual bird's-eye view features. Our method significantly outperforms the current state-of-the-art OrienterNet on both the nuScenes and Argoverse datasets, which is nearly 10%/20% localization accuracy and 30/16 FPS improvement on single-view and surround-view input settings, separately. We highlight that our research presents an HD-map-free localization method for autonomous driving, offering cost-effective, reliable, and scalable performance in challenging driving environments.
Privacy-Preserving Sequential Recommendation with Collaborative Confusion
Jan 09, 2024

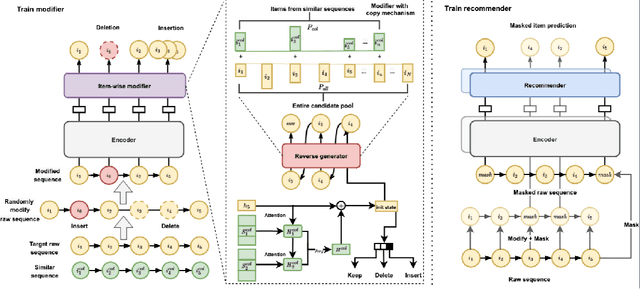
Sequential recommendation has attracted a lot of attention from both academia and industry, however the privacy risks associated to gathering and transferring users' personal interaction data are often underestimated or ignored. Existing privacy-preserving studies are mainly applied to traditional collaborative filtering or matrix factorization rather than sequential recommendation. Moreover, these studies are mostly based on differential privacy or federated learning, which often leads to significant performance degradation, or has high requirements for communication. In this work, we address privacy-preserving from a different perspective. Unlike existing research, we capture collaborative signals of neighbor interaction sequences and directly inject indistinguishable items into the target sequence before the recommendation process begins, thereby increasing the perplexity of the target sequence. Even if the target interaction sequence is obtained by attackers, it is difficult to discern which ones are the actual user interaction records. To achieve this goal, we propose a CoLlaborative-cOnfusion seqUential recommenDer, namely CLOUD, which incorporates a collaborative confusion mechanism to edit the raw interaction sequences before conducting recommendation. Specifically, CLOUD first calculates the similarity between the target interaction sequence and other neighbor sequences to find similar sequences. Then, CLOUD considers the shared representation of the target sequence and similar sequences to determine the operation to be performed: keep, delete, or insert. We design a copy mechanism to make items from similar sequences have a higher probability to be inserted into the target sequence. Finally, the modified sequence is used to train the recommender and predict the next item.
Prior-mean-assisted Bayesian optimization application on FRIB Front-End tunning
Nov 11, 2022Bayesian optimization~(BO) is often used for accelerator tuning due to its high sample efficiency. However, the computational scalability of training over large data-set can be problematic and the adoption of historical data in a computationally efficient way is not trivial. Here, we exploit a neural network model trained over historical data as a prior mean of BO for FRIB Front-End tuning.
Deep Factorization Model for Robust Recommendation
Nov 05, 2022Recently, malevolent user hacking has become a huge problem for real-world companies. In order to learn predictive models for recommender systems, factorization techniques have been developed to deal with user-item ratings. In this paper, we suggest a broad architecture of a factorization model with adversarial training to get over these issues. The effectiveness of our systems is demonstrated by experimental findings on real-world datasets.
Unbiased IoU for Spherical Image Object Detection
Aug 18, 2021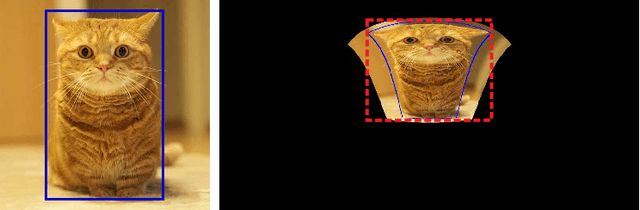
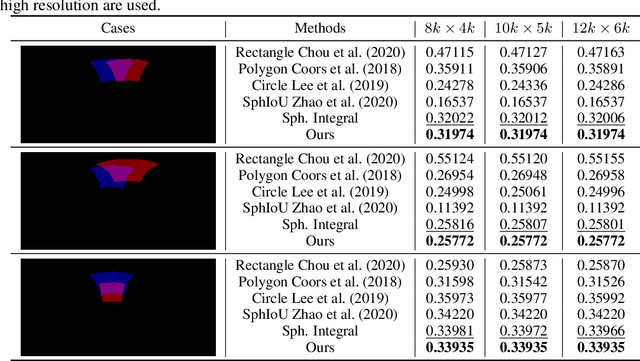
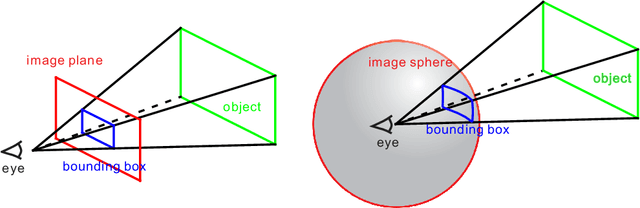

As one of the most fundamental and challenging problems in computer vision, object detection tries to locate object instances and find their categories in natural images. The most important step in the evaluation of object detection algorithm is calculating the intersection-over-union (IoU) between the predicted bounding box and the ground truth one. Although this procedure is well-defined and solved for planar images, it is not easy for spherical image object detection. Existing methods either compute the IoUs based on biased bounding box representations or make excessive approximations, thus would give incorrect results. In this paper, we first identify that spherical rectangles are unbiased bounding boxes for objects in spherical images, and then propose an analytical method for IoU calculation without any approximations. Based on the unbiased representation and calculation, we also present an anchor free object detection algorithm for spherical images. The experiments on two spherical object detection datasets show that the proposed method can achieve better performance than existing methods.
Dense Scale Network for Crowd Counting
Jun 24, 2019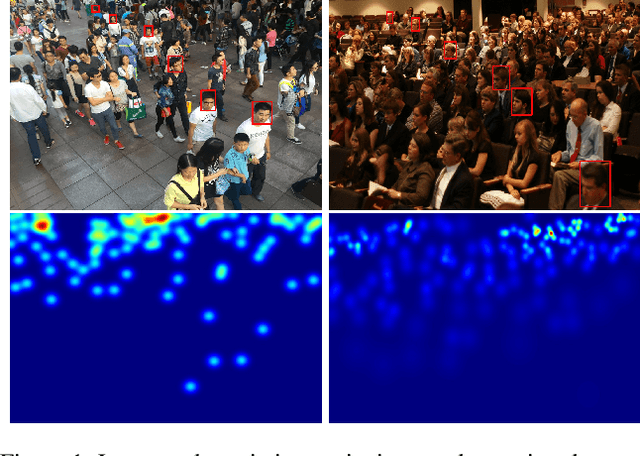
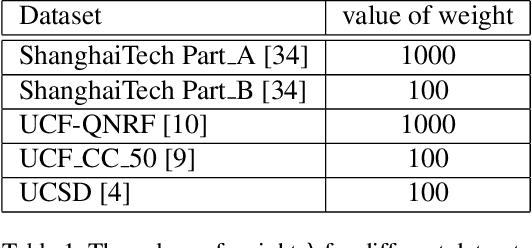
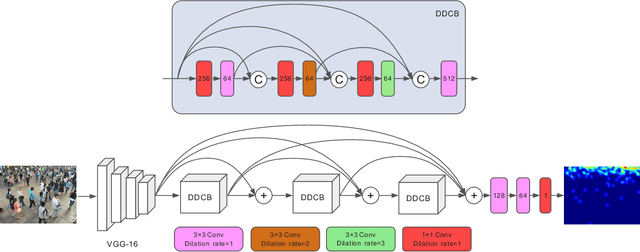
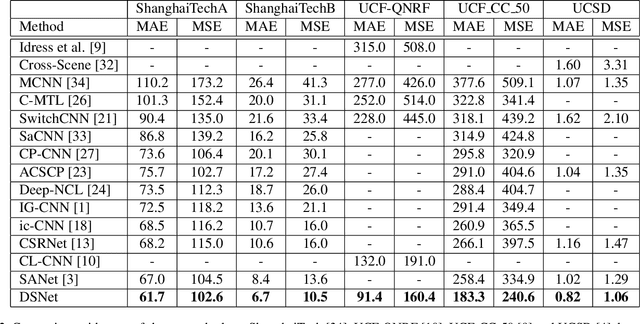
Crowd counting has been widely studied by computer vision community in recent years. Due to the large scale variation, it remains to be a challenging task. Previous methods adopt either multi-column CNN or single-column CNN with multiple branches to deal with this problem. However, restricted by the number of columns or branches, these methods can only capture a few different scales and have limited capability. In this paper, we propose a simple but effective network called DSNet for crowd counting, which can be easily trained in an end-to-end fashion. The key component of our network is the dense dilated convolution block, in which each dilation layer is densely connected with the others to preserve information from continuously varied scales. The dilation rates in dilation layers are carefully selected to prevent the block from gridding artifacts. To further enlarge the range of scales covered by the network, we cascade three blocks and link them with dense residual connections. We also introduce a novel multi-scale density level consistency loss for performance improvement. To evaluate our method, we compare it with state-of-the-art algorithms on four crowd counting datasets (ShanghaiTech, UCF-QNRF, UCF_CC_50 and UCSD). Experimental results demonstrate that DSNet can achieve the best performance and make significant improvements on all the four datasets (30% on the UCF-QNRF and UCF_CC_50, and 20% on the others).