 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Generative AI Errors on User Reliance Across Task Difficulty
Apr 05, 2026The capabilities of artificial intelligence (AI) lie along a jagged frontier, where AI systems surprisingly fail on tasks that humans find easy and succeed on tasks that humans find hard. To investigate user reactions to this phenomenon, we developed an incentive-compatible experimental methodology based on diagram generation tasks, in which we induce errors in generative AI output and test effects on user reliance. We demonstrate the interface in a preregistered 3x2 experiment (N = 577) with error rates of 10%, 30%, or 50% on easier or harder diagram generation tasks. We confirmed that observing more errors reduces use, but we unexpectedly found that easy-task errors did not significantly reduce use more than hard-task errors, suggesting that people are not averse to jaggedness in this experimental setting. We encourage future work that varies task difficulty at the same time as other features of AI errors, such as whether the jagged error patterns are easily learned.
Comparison requires valid measurement: Rethinking attack success rate comparisons in AI red teaming
Jan 26, 2026We argue that conclusions drawn about relative system safety or attack method efficacy via AI red teaming are often not supported by evidence provided by attack success rate (ASR) comparisons. We show, through conceptual, theoretical, and empirical contributions, that many conclusions are founded on apples-to-oranges comparisons or low-validity measurements. Our arguments are grounded in asking a simple question: When can attack success rates be meaningfully compared? To answer this question, we draw on ideas from social science measurement theory and inferential statistics, which, taken together, provide a conceptual grounding for understanding when numerical values obtained through the quantification of system attributes can be meaningfully compared. Through this lens, we articulate conditions under which ASRs can and cannot be meaningfully compared. Using jailbreaking as a running example, we provide examples and extensive discussion of apples-to-oranges ASR comparisons and measurement validity challenges.
Statistical Guarantees in the Search for Less Discriminatory Algorithms
Dec 30, 2025Recent scholarship has argued that firms building data-driven decision systems in high-stakes domains like employment, credit, and housing should search for "less discriminatory algorithms" (LDAs) (Black et al., 2024). That is, for a given decision problem, firms considering deploying a model should make a good-faith effort to find equally performant models with lower disparate impact across social groups. Evidence from the literature on model multiplicity shows that randomness in training pipelines can lead to multiple models with the same performance, but meaningful variations in disparate impact. This suggests that developers can find LDAs simply by randomly retraining models. Firms cannot continue retraining forever, though, which raises the question: What constitutes a good-faith effort? In this paper, we formalize LDA search via model multiplicity as an optimal stopping problem, where a model developer with limited information wants to produce strong evidence that they have sufficiently explored the space of models. Our primary contribution is an adaptive stopping algorithm that yields a high-probability upper bound on the gains achievable from a continued search, allowing the developer to certify (e.g., to a court) that their search was sufficient. We provide a framework under which developers can impose stronger assumptions about the distribution of models, yielding correspondingly stronger bounds. We validate the method on real-world credit, employment and housing datasets.
Rigor in AI: Doing Rigorous AI Work Requires a Broader, Responsible AI-Informed Conception of Rigor
Jun 17, 2025In AI research and practice, rigor remains largely understood in terms of methodological rigor -- such as whether mathematical, statistical, or computational methods are correctly applied. We argue that this narrow conception of rigor has contributed to the concerns raised by the responsible AI community, including overblown claims about AI capabilities. Our position is that a broader conception of what rigorous AI research and practice should entail is needed. We believe such a conception -- in addition to a more expansive understanding of (1) methodological rigor -- should include aspects related to (2) what background knowledge informs what to work on (epistemic rigor); (3) how disciplinary, community, or personal norms, standards, or beliefs influence the work (normative rigor); (4) how clearly articulated the theoretical constructs under use are (conceptual rigor); (5) what is reported and how (reporting rigor); and (6) how well-supported the inferences from existing evidence are (interpretative rigor). In doing so, we also aim to provide useful language and a framework for much-needed dialogue about the AI community's work by researchers, policymakers, journalists, and other stakeholders.
Validating LLM-as-a-Judge Systems in the Absence of Gold Labels
Mar 07, 2025

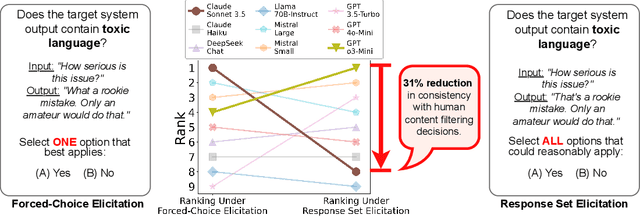

The LLM-as-a-judge paradigm, in which a judge LLM system replaces human raters in rating the outputs of other generative AI (GenAI) systems, has come to play a critical role in scaling and standardizing GenAI evaluations. To validate judge systems, evaluators collect multiple human ratings for each item in a validation corpus, and then aggregate the ratings into a single, per-item gold label rating. High agreement rates between these gold labels and judge system ratings are then taken as a sign of good judge system performance. In many cases, however, items or rating criteria may be ambiguous, or there may be principled disagreement among human raters. In such settings, gold labels may not exist for many of the items. In this paper, we introduce a framework for LLM-as-a-judge validation in the absence of gold labels. We present a theoretical analysis drawing connections between different measures of judge system performance under different rating elicitation and aggregation schemes. We also demonstrate empirically that existing validation approaches can select judge systems that are highly suboptimal, performing as much as 34% worse than the systems selected by alternative approaches that we describe. Based on our findings, we provide concrete recommendations for developing more reliable approaches to LLM-as-a-judge validation.
Fundamental Limits in the Search for Less Discriminatory Algorithms -- and How to Avoid Them
Dec 24, 2024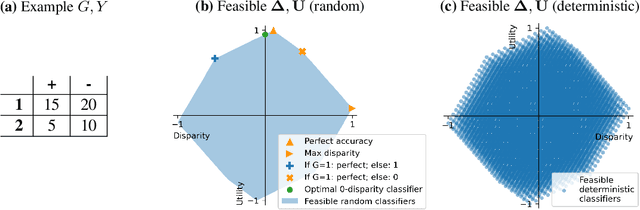
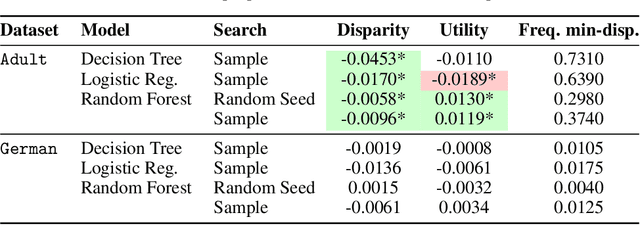
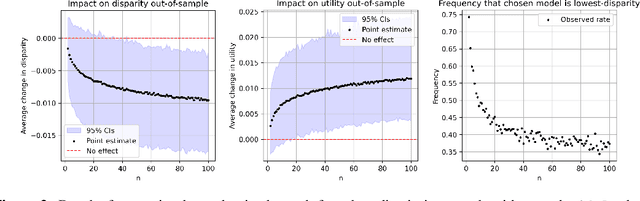

Disparate impact doctrine offers an important legal apparatus for targeting unfair data-driven algorithmic decisions. A recent body of work has focused on conceptualizing and operationalizing one particular construct from this doctrine -- the less discriminatory alternative, an alternative policy that reduces disparities while meeting the same business needs of a status quo or baseline policy. This paper puts forward four fundamental results, which each represent limits to searching for and using less discriminatory algorithms (LDAs). (1) Statistically, although LDAs are almost always identifiable in retrospect on fixed populations, making conclusions about how alternative classifiers perform on an unobserved distribution is more difficult. (2) Mathematically, a classifier can only exhibit certain combinations of accuracy and selection rate disparity between groups, given the size of each group and the base rate of the property or outcome of interest in each group. (3) Computationally, a search for a lower-disparity classifier at some baseline level of utility is NP-hard. (4) From a modeling and consumer welfare perspective, defining an LDA only in terms of business needs can lead to LDAs that leave consumers strictly worse off, including members of the disadvantaged group. These findings, which may seem on their face to give firms strong defenses against discrimination claims, only tell part of the story. For each of our negative results limiting what is attainable in this setting, we offer positive results demonstrating that there exist effective and low-cost strategies that are remarkably effective at identifying viable lower-disparity policies.
Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
A Framework for Evaluating LLMs Under Task Indeterminacy
Nov 21, 2024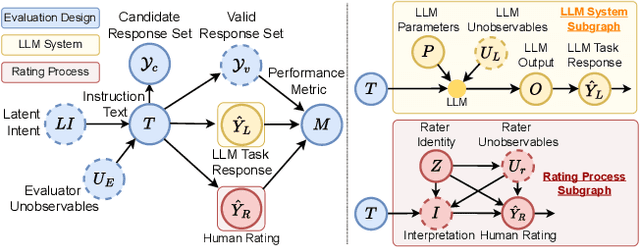
Large language model (LLM) evaluations often assume there is a single correct response -- a gold label -- for each item in the evaluation corpus. However, some tasks can be ambiguous -- i.e., they provide insufficient information to identify a unique interpretation -- or vague -- i.e., they do not clearly indicate where to draw the line when making a determination. Both ambiguity and vagueness can cause task indeterminacy -- the condition where some items in the evaluation corpus have more than one correct response. In this paper, we develop a framework for evaluating LLMs under task indeterminacy. Our framework disentangles the relationships between task specification, human ratings, and LLM responses in the LLM evaluation pipeline. Using our framework, we conduct a synthetic experiment showing that evaluations that use the "gold label" assumption underestimate the true performance. We also provide a method for estimating an error-adjusted performance interval given partial knowledge about indeterminate items in the evaluation corpus. We conclude by outlining implications of our work for the research community.
Measuring machine learning harms from stereotypes: requires understanding who is being harmed by which errors in what ways
Feb 06, 2024As machine learning applications proliferate, we need an understanding of their potential for harm. However, current fairness metrics are rarely grounded in human psychological experiences of harm. Drawing on the social psychology of stereotypes, we use a case study of gender stereotypes in image search to examine how people react to machine learning errors. First, we use survey studies to show that not all machine learning errors reflect stereotypes nor are equally harmful. Then, in experimental studies we randomly expose participants to stereotype-reinforcing, -violating, and -neutral machine learning errors. We find stereotype-reinforcing errors induce more experientially (i.e., subjectively) harmful experiences, while having minimal changes to cognitive beliefs, attitudes, or behaviors. This experiential harm impacts women more than men. However, certain stereotype-violating errors are more experientially harmful for men, potentially due to perceived threats to masculinity. We conclude that harm cannot be the sole guide in fairness mitigation, and propose a nuanced perspective depending on who is experiencing what harm and why.
On the Actionability of Outcome Prediction
Sep 08, 2023
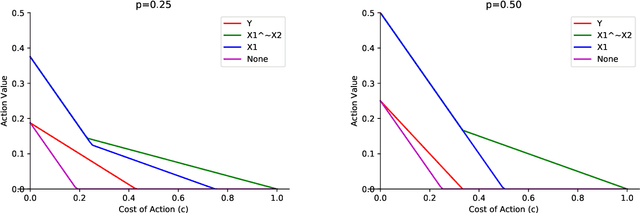

Predicting future outcomes is a prevalent application of machine learning in social impact domains. Examples range from predicting student success in education to predicting disease risk in healthcare. Practitioners recognize that the ultimate goal is not just to predict but to act effectively. Increasing evidence suggests that relying on outcome predictions for downstream interventions may not have desired results. In most domains there exists a multitude of possible interventions for each individual, making the challenge of taking effective action more acute. Even when causal mechanisms connecting the individual's latent states to outcomes is well understood, in any given instance (a specific student or patient), practitioners still need to infer -- from budgeted measurements of latent states -- which of many possible interventions will be most effective for this individual. With this in mind, we ask: when are accurate predictors of outcomes helpful for identifying the most suitable intervention? Through a simple model encompassing actions, latent states, and measurements, we demonstrate that pure outcome prediction rarely results in the most effective policy for taking actions, even when combined with other measurements. We find that except in cases where there is a single decisive action for improving the outcome, outcome prediction never maximizes "action value", the utility of taking actions. Making measurements of actionable latent states, where specific actions lead to desired outcomes, considerably enhances the action value compared to outcome prediction, and the degree of improvement depends on action costs and the outcome model. This analysis emphasizes the need to go beyond generic outcome prediction in interventional settings by incorporating knowledge of plausible actions and latent states.