 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCRuB: Social Concept Reasoning under Rubric-Based Evaluation
May 07, 2026While many studies of Large Language Model (LLM) reasoning capabilities emphasize mathematical or technical tasks, few address reasoning about social concepts: the abstract ideas shaping social norms, culture, and institutions. This understudied capability is essential for modern models acting as social agents, yet no systematic evaluation methodology targets it. We introduce SCRuB (Social Concept Reasoning under Rubric-Based Evaluation), a framework designed for this setting of task indeterminacy. Our goal is to measure the degree to which a model reasons about social concepts with the depth and critical rigor of a human expert. SCRuB proceeds in three phases: prompt construction from established sources, response generation by experts and models, and comparative evaluation using a five-dimensional critical thinking rubric. To enable generalization of the pipeline, we introduce a Panel of Disciplinary Perspectives ensemble validated against independent expert judges. We release SCRuBEval (n=4,711 evaluation prompts) and SCRuBAnnotations (300 expert-authored responses and 150 expert comparative judgments from 45 PhD-level scholars). Our results show that frontier models consistently outperform human experts across all five rubric dimensions. Across 1,170 pairwise comparisons, expert judges ranked a model response first in 80.8% of judgments and preferred model responses overall 74.4% of the time. Ultimately, this study provides the first expert-grounded demonstration of evaluation saturation for social concept reasoning: the single-turn exam-style format has reached its ceiling for models and humans alike.
Mysterious Projections: Multimodal LLMs Gain Domain-Specific Visual Capabilities Without Richer Cross-Modal Projections
Feb 26, 2024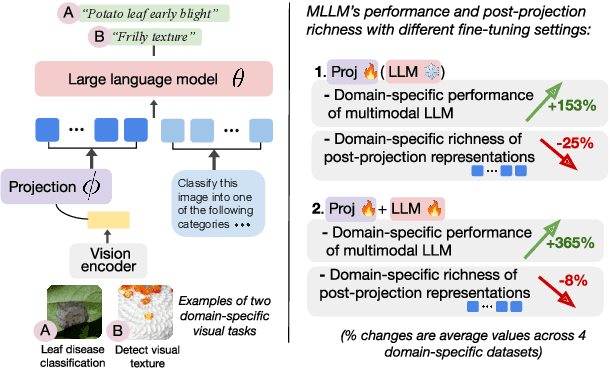
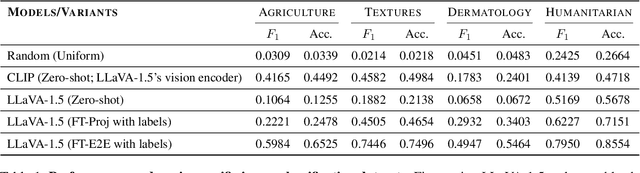
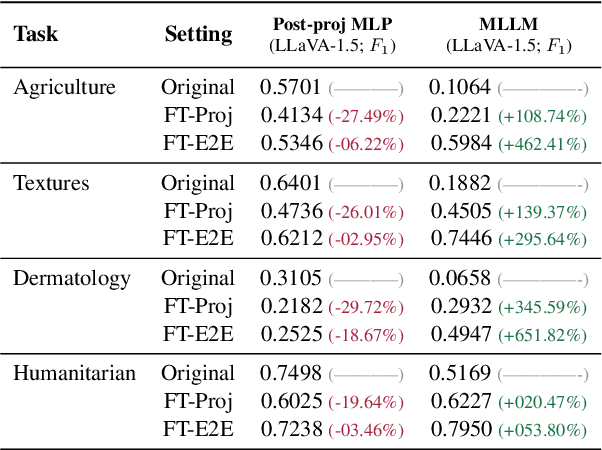
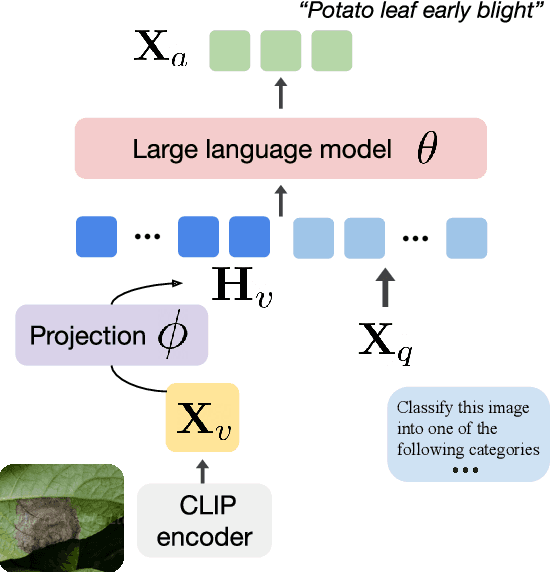
Multimodal large language models (MLLMs) like LLaVA and GPT-4(V) enable general-purpose conversations about images with the language modality. As off-the-shelf MLLMs may have limited capabilities on images from domains like dermatology and agriculture, they must be fine-tuned to unlock domain-specific applications. The prevalent architecture of current open-source MLLMs comprises two major modules: an image-language (cross-modal) projection network and a large language model. It is desirable to understand the roles of these two modules in modeling domain-specific visual attributes to inform the design of future models and streamline the interpretability efforts on the current models. To this end, via experiments on 4 datasets and under 2 fine-tuning settings, we find that as the MLLM is fine-tuned, it indeed gains domain-specific visual capabilities, but the updates do not lead to the projection extracting relevant domain-specific visual attributes. Our results indicate that the domain-specific visual attributes are modeled by the LLM, even when only the projection is fine-tuned. Through this study, we offer a potential reinterpretation of the role of cross-modal projections in MLLM architectures. Projection webpage: https://claws-lab.github.io/projection-in-MLLMs/
Predictive Churn with the Set of Good Models
Feb 12, 2024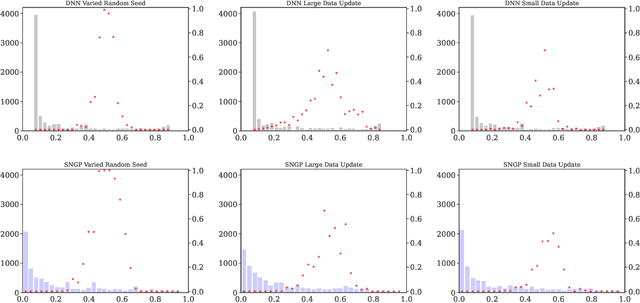

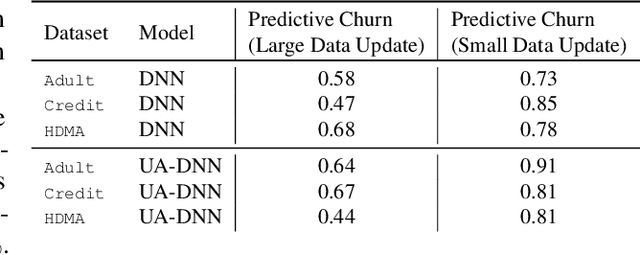
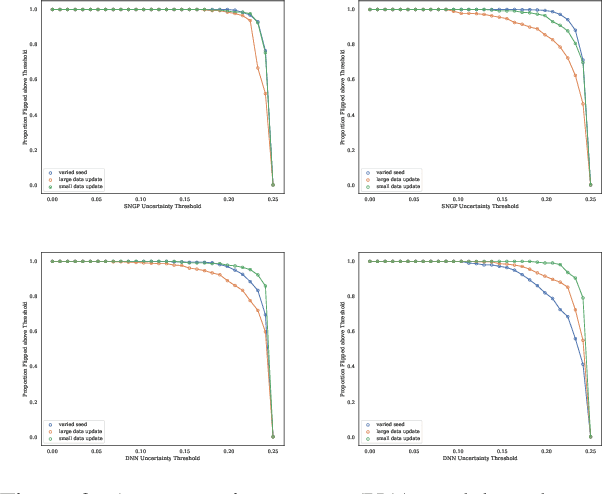
Machine learning models in modern mass-market applications are often updated over time. One of the foremost challenges faced is that, despite increasing overall performance, these updates may flip specific model predictions in unpredictable ways. In practice, researchers quantify the number of unstable predictions between models pre and post update -- i.e., predictive churn. In this paper, we study this effect through the lens of predictive multiplicity -- i.e., the prevalence of conflicting predictions over the set of near-optimal models (the Rashomon set). We show how traditional measures of predictive multiplicity can be used to examine expected churn over this set of prospective models -- i.e., the set of models that may be used to replace a baseline model in deployment. We present theoretical results on the expected churn between models within the Rashomon set from different perspectives. And we characterize expected churn over model updates via the Rashomon set, pairing our analysis with empirical results on real-world datasets -- showing how our approach can be used to better anticipate, reduce, and avoid churn in consumer-facing applications. Further, we show that our approach is useful even for models enhanced with uncertainty awareness.
Multi-Target Multiplicity: Flexibility and Fairness in Target Specification under Resource Constraints
Jun 23, 2023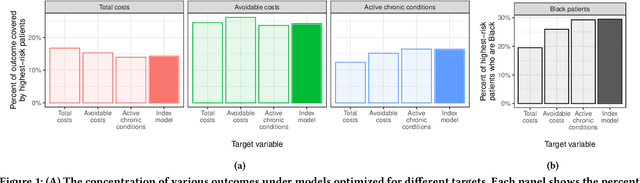



Prediction models have been widely adopted as the basis for decision-making in domains as diverse as employment, education, lending, and health. Yet, few real world problems readily present themselves as precisely formulated prediction tasks. In particular, there are often many reasonable target variable options. Prior work has argued that this is an important and sometimes underappreciated choice, and has also shown that target choice can have a significant impact on the fairness of the resulting model. However, the existing literature does not offer a formal framework for characterizing the extent to which target choice matters in a particular task. Our work fills this gap by drawing connections between the problem of target choice and recent work on predictive multiplicity. Specifically, we introduce a conceptual and computational framework for assessing how the choice of target affects individuals' outcomes and selection rate disparities across groups. We call this multi-target multiplicity. Along the way, we refine the study of single-target multiplicity by introducing notions of multiplicity that respect resource constraints -- a feature of many real-world tasks that is not captured by existing notions of predictive multiplicity. We apply our methods on a healthcare dataset, and show that the level of multiplicity that stems from target variable choice can be greater than that stemming from nearly-optimal models of a single target.
* Conference on Fairness, Accountability, and Transparency (FAccT '23), June 12-15, 2023, Chicago, IL, USA
Predictive Multiplicity in Probabilistic Classification
Jun 02, 2022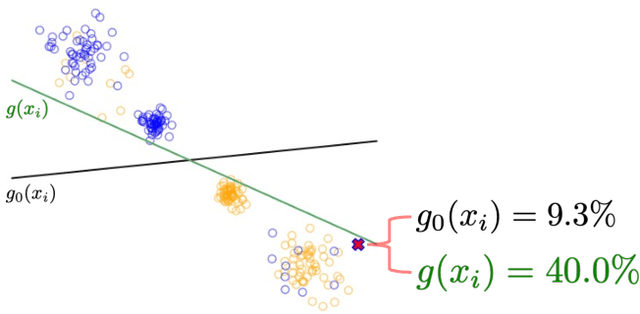
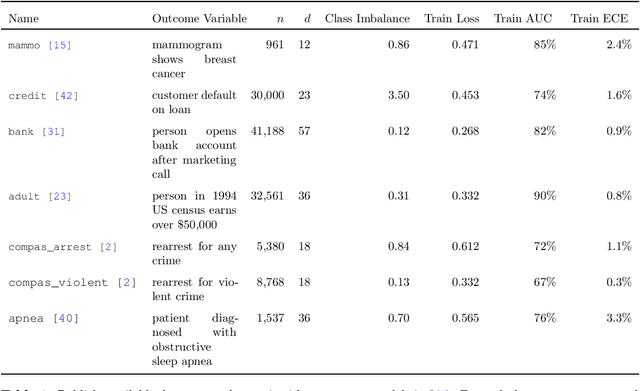


For a prediction task, there may exist multiple models that perform almost equally well. This multiplicity complicates how we typically develop and deploy machine learning models. We study how multiplicity affects predictions -- i.e., predictive multiplicity -- in probabilistic classification. We introduce new measures for this setting and present optimization-based methods to compute these measures for convex empirical risk minimization problems like logistic regression. We apply our methodology to gain insight into why predictive multiplicity arises. We study the incidence and prevalence of predictive multiplicity in real-world risk assessment tasks. Our results emphasize the need to report multiplicity more widely.