 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
A Thousand Words or An Image: Studying the Influence of Persona Modality in Multimodal LLMs
Feb 27, 2025Large language models (LLMs) have recently demonstrated remarkable advancements in embodying diverse personas, enhancing their effectiveness as conversational agents and virtual assistants. Consequently, LLMs have made significant strides in processing and integrating multimodal information. However, even though human personas can be expressed in both text and image, the extent to which the modality of a persona impacts the embodiment by the LLM remains largely unexplored. In this paper, we investigate how do different modalities influence the expressiveness of personas in multimodal LLMs. To this end, we create a novel modality-parallel dataset of 40 diverse personas varying in age, gender, occupation, and location. This consists of four modalities to equivalently represent a persona: image-only, text-only, a combination of image and small text, and typographical images, where text is visually stylized to convey persona-related attributes. We then create a systematic evaluation framework with 60 questions and corresponding metrics to assess how well LLMs embody each persona across its attributes and scenarios. Comprehensive experiments on $5$ multimodal LLMs show that personas represented by detailed text show more linguistic habits, while typographical images often show more consistency with the persona. Our results reveal that LLMs often overlook persona-specific details conveyed through images, highlighting underlying limitations and paving the way for future research to bridge this gap. We release the data and code at https://github.com/claws-lab/persona-modality .
Personalized Layer Selection for Graph Neural Networks
Jan 24, 2025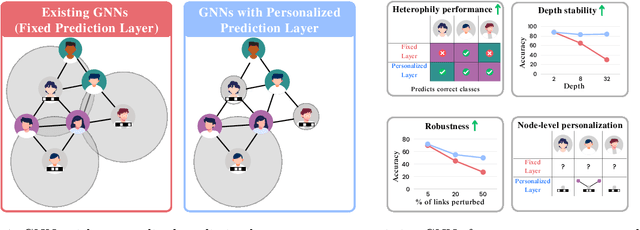
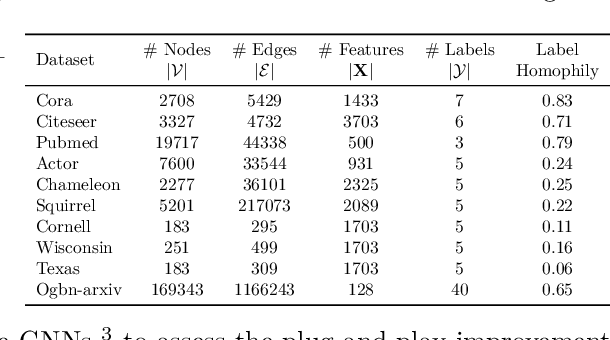
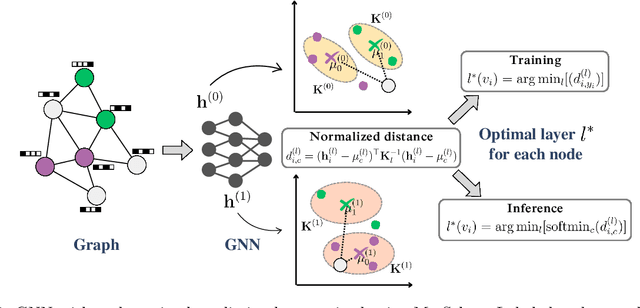
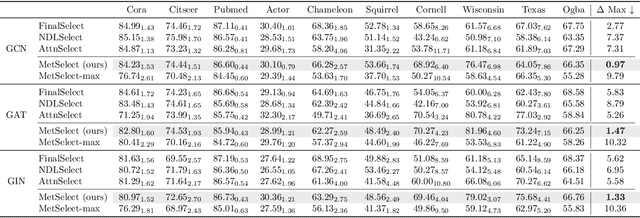
Graph Neural Networks (GNNs) combine node attributes over a fixed granularity of the local graph structure around a node to predict its label. However, different nodes may relate to a node-level property with a different granularity of its local neighborhood, and using the same level of smoothing for all nodes can be detrimental to their classification. In this work, we challenge the common fact that a single GNN layer can classify all nodes of a graph by training GNNs with a distinct personalized layer for each node. Inspired by metric learning, we propose a novel algorithm, MetSelect1, to select the optimal representation layer to classify each node. In particular, we identify a prototype representation of each class in a transformed GNN layer and then, classify using the layer where the distance is smallest to a class prototype after normalizing with that layer's variance. Results on 10 datasets and 3 different GNNs show that we significantly improve the node classification accuracy of GNNs in a plug-and-play manner. We also find that using variable layers for prediction enables GNNs to be deeper and more robust to poisoning attacks. We hope this work can inspire future works to learn more adaptive and personalized graph representations.
OG-RAG: Ontology-Grounded Retrieval-Augmented Generation For Large Language Models
Dec 12, 2024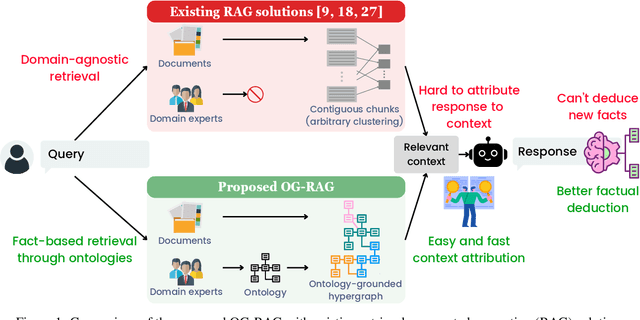

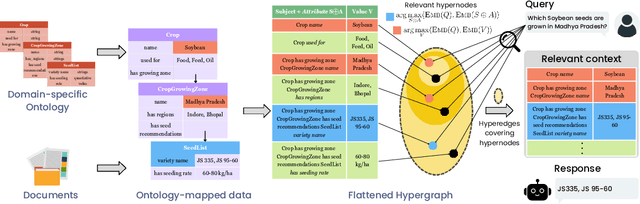
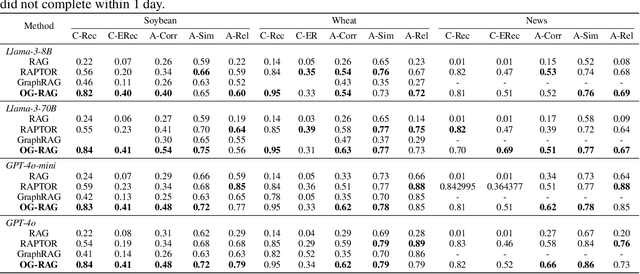
This paper presents OG-RAG, an Ontology-Grounded Retrieval Augmented Generation method designed to enhance LLM-generated responses by anchoring retrieval processes in domain-specific ontologies. While LLMs are widely used for tasks like question answering and search, they struggle to adapt to specialized knowledge, such as industrial workflows or knowledge work, without expensive fine-tuning or sub-optimal retrieval methods. Existing retrieval-augmented models, such as RAG, offer improvements but fail to account for structured domain knowledge, leading to suboptimal context generation. Ontologies, which conceptually organize domain knowledge by defining entities and their interrelationships, offer a structured representation to address this gap. OG-RAG constructs a hypergraph representation of domain documents, where each hyperedge encapsulates clusters of factual knowledge grounded using domain-specific ontology. An optimization algorithm then retrieves the minimal set of hyperedges that constructs a precise, conceptually grounded context for the LLM. This method enables efficient retrieval while preserving the complex relationships between entities. OG-RAG applies to domains where fact-based reasoning is essential, particularly in tasks that require workflows or decision-making steps to follow predefined rules and procedures. These include industrial workflows in healthcare, legal, and agricultural sectors, as well as knowledge-driven tasks such as news journalism, investigative research, consulting and more. Our evaluations demonstrate that OG-RAG increases the recall of accurate facts by 55% and improves response correctness by 40% across four different LLMs. Additionally, OG-RAG enables 30% faster attribution of responses to context and boosts fact-based reasoning accuracy by 27% compared to baseline methods.
$\textit{Who Speaks Matters}$: Analysing the Influence of the Speaker's Ethnicity on Hate Classification
Oct 27, 2024Large Language Models (LLMs) offer a lucrative promise for scalable content moderation, including hate speech detection. However, they are also known to be brittle and biased against marginalised communities and dialects. This requires their applications to high-stakes tasks like hate speech detection to be critically scrutinized. In this work, we investigate the robustness of hate speech classification using LLMs, particularly when explicit and implicit markers of the speaker's ethnicity are injected into the input. For the explicit markers, we inject a phrase that mentions the speaker's identity. For the implicit markers, we inject dialectal features. By analysing how frequently model outputs flip in the presence of these markers, we reveal varying degrees of brittleness across 4 popular LLMs and 5 ethnicities. We find that the presence of implicit dialect markers in inputs causes model outputs to flip more than the presence of explicit markers. Further, the percentage of flips varies across ethnicities. Finally, we find that larger models are more robust. Our findings indicate the need for exercising caution in deploying LLMs for high-stakes tasks like hate speech detection.
Mysterious Projections: Multimodal LLMs Gain Domain-Specific Visual Capabilities Without Richer Cross-Modal Projections
Feb 26, 2024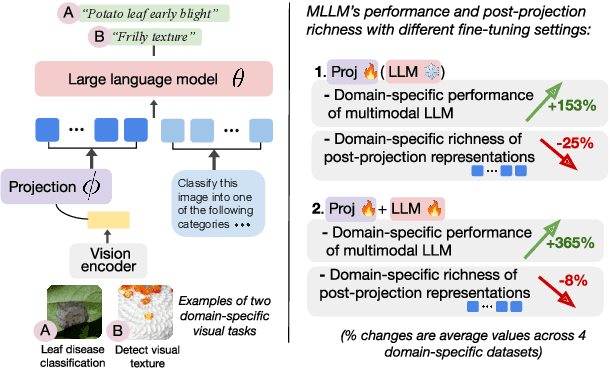
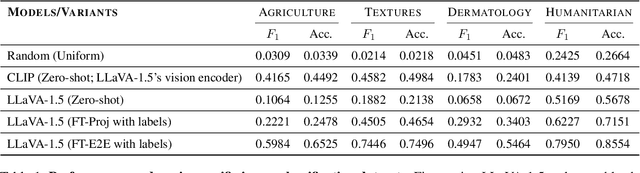
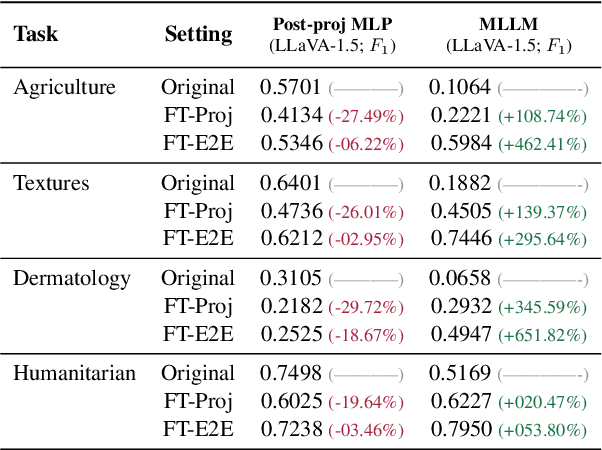
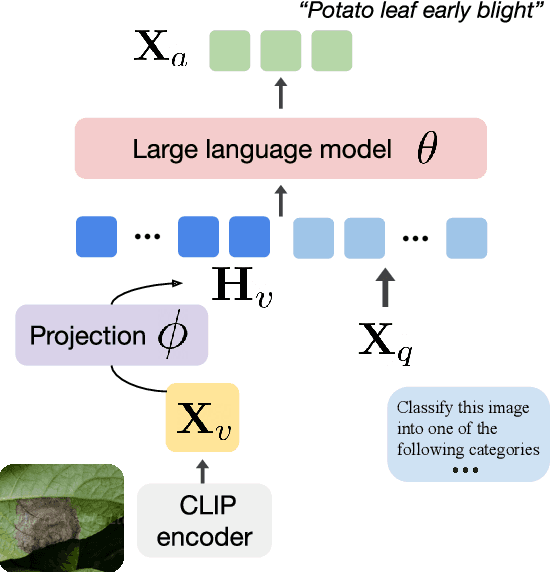
Multimodal large language models (MLLMs) like LLaVA and GPT-4(V) enable general-purpose conversations about images with the language modality. As off-the-shelf MLLMs may have limited capabilities on images from domains like dermatology and agriculture, they must be fine-tuned to unlock domain-specific applications. The prevalent architecture of current open-source MLLMs comprises two major modules: an image-language (cross-modal) projection network and a large language model. It is desirable to understand the roles of these two modules in modeling domain-specific visual attributes to inform the design of future models and streamline the interpretability efforts on the current models. To this end, via experiments on 4 datasets and under 2 fine-tuning settings, we find that as the MLLM is fine-tuned, it indeed gains domain-specific visual capabilities, but the updates do not lead to the projection extracting relevant domain-specific visual attributes. Our results indicate that the domain-specific visual attributes are modeled by the LLM, even when only the projection is fine-tuned. Through this study, we offer a potential reinterpretation of the role of cross-modal projections in MLLM architectures. Projection webpage: https://claws-lab.github.io/projection-in-MLLMs/
A Survey on Explainability of Graph Neural Networks
Jun 02, 2023



Graph neural networks (GNNs) are powerful graph-based deep-learning models that have gained significant attention and demonstrated remarkable performance in various domains, including natural language processing, drug discovery, and recommendation systems. However, combining feature information and combinatorial graph structures has led to complex non-linear GNN models. Consequently, this has increased the challenges of understanding the workings of GNNs and the underlying reasons behind their predictions. To address this, numerous explainability methods have been proposed to shed light on the inner mechanism of the GNNs. Explainable GNNs improve their security and enhance trust in their recommendations. This survey aims to provide a comprehensive overview of the existing explainability techniques for GNNs. We create a novel taxonomy and hierarchy to categorize these methods based on their objective and methodology. We also discuss the strengths, limitations, and application scenarios of each category. Furthermore, we highlight the key evaluation metrics and datasets commonly used to assess the explainability of GNNs. This survey aims to assist researchers and practitioners in understanding the existing landscape of explainability methods, identifying gaps, and fostering further advancements in interpretable graph-based machine learning.
NoisyTwins: Class-Consistent and Diverse Image Generation through StyleGANs
Apr 12, 2023StyleGANs are at the forefront of controllable image generation as they produce a latent space that is semantically disentangled, making it suitable for image editing and manipulation. However, the performance of StyleGANs severely degrades when trained via class-conditioning on large-scale long-tailed datasets. We find that one reason for degradation is the collapse of latents for each class in the $\mathcal{W}$ latent space. With NoisyTwins, we first introduce an effective and inexpensive augmentation strategy for class embeddings, which then decorrelates the latents based on self-supervision in the $\mathcal{W}$ space. This decorrelation mitigates collapse, ensuring that our method preserves intra-class diversity with class-consistency in image generation. We show the effectiveness of our approach on large-scale real-world long-tailed datasets of ImageNet-LT and iNaturalist 2019, where our method outperforms other methods by $\sim 19\%$ on FID, establishing a new state-of-the-art.
A Survey of Graph Neural Networks for Social Recommender Systems
Dec 12, 2022

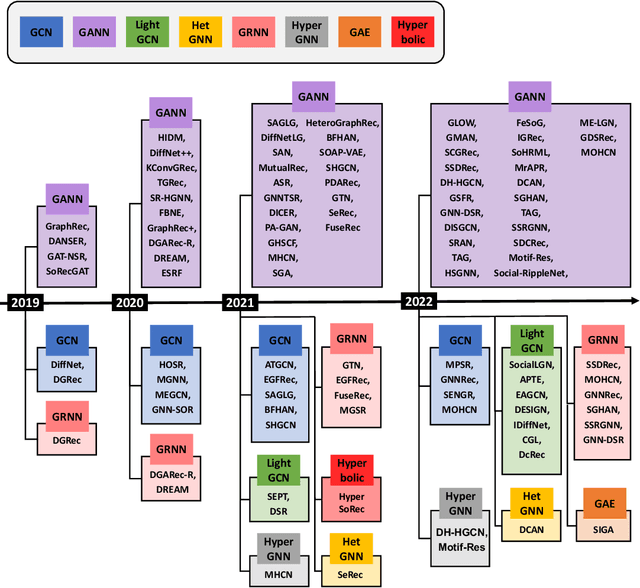

Social recommender systems (SocialRS) simultaneously leverage user-to-item interactions as well as user-to-user social relations for the task of generating item recommendations to users. Additionally exploiting social relations is clearly effective in understanding users' tastes due to the effects of homophily and social influence. For this reason, SocialRS has increasingly attracted attention. In particular, with the advance of Graph Neural Networks (GNN), many GNN-based SocialRS methods have been developed recently. Therefore, we conduct a comprehensive and systematic review of the literature on GNN-based SocialRS. In this survey, we first identify 80 papers on GNN-based SocialRS after annotating 2151 papers by following the PRISMA framework (Preferred Reporting Items for Systematic Reviews and Meta-Analysis). Then, we comprehensively review them in terms of their inputs and architectures to propose a novel taxonomy: (1) input taxonomy includes 5 groups of input type notations and 7 groups of input representation notations; (2) architecture taxonomy includes 8 groups of GNN encoder, 2 groups of decoder, and 12 groups of loss function notations. We classify the GNN-based SocialRS methods into several categories as per the taxonomy and describe their details. Furthermore, we summarize the benchmark datasets and metrics widely used to evaluate the GNN-based SocialRS methods. Finally, we conclude this survey by presenting some future research directions.
Signed Link Representation in Continuous-Time Dynamic Signed Networks
Jul 07, 2022
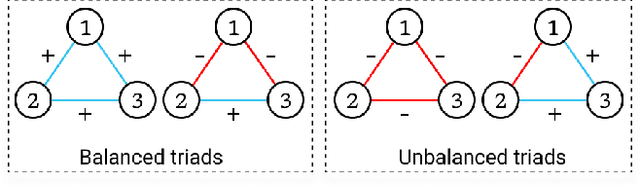

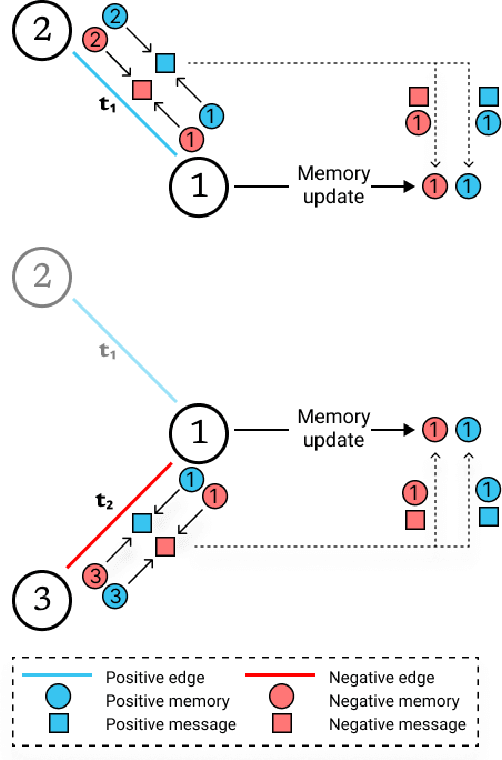
Signed networks allow us to model bi-faceted relationships and interactions, such as friend/enemy, support/oppose, etc. These interactions are often temporal in real datasets, where nodes and edges appear over time. Learning the dynamics of signed networks is thus crucial to effectively predict the sign and strength of future links. Existing works model either signed networks or dynamic networks but not both together. In this work, we study dynamic signed networks where links are both signed and evolving with time. Our model learns a Signed link's Evolution using Memory modules and Balanced Aggregation (hence, the name SEMBA). Each node maintains two separate memory encodings for positive and negative interactions. On the arrival of a new edge, each interacting node aggregates this signed information with its memories while exploiting balance theory. Node embeddings are generated using updated memories, which are then used to train for multiple downstream tasks, including link sign prediction and link weight prediction. Our results show that SEMBA outperforms all the baselines on the task of sign prediction by achieving up to an 8% increase in the AUC and up to a 50% reduction in FPR. Results on the task of predicting signed weights show that SEMBA reduces the mean squared error by 9% while achieving up to 69% reduction in the KL-divergence on the distribution of predicted signed weights.