 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLHAW: Controllable Underspecification for Long-Horizon Tasks
Feb 11, 2026Long-horizon workflow agents that operate effectively over extended periods are essential for truly autonomous systems. Their reliable execution critically depends on the ability to reason through ambiguous situations in which clarification seeking is necessary to ensure correct task execution. However, progress is limited by the lack of scalable, task-agnostic frameworks for systematically curating and measuring the impact of ambiguity across custom workflows. We address this gap by introducing LHAW (Long-Horizon Augmented Workflows), a modular, dataset-agnostic synthetic pipeline that transforms any well-specified task into controllable underspecified variants by systematically removing information across four dimensions - Goals, Constraints, Inputs, and Context - at configurable severity levels. Unlike approaches that rely on LLM predictions of ambiguity, LHAW validates variants through empirical agent trials, classifying them as outcome-critical, divergent, or benign based on observed terminal state divergence. We release 285 task variants from TheAgentCompany, SWE-Bench Pro and MCP-Atlas according to our taxonomy alongside formal analysis measuring how current agents detect, reason about, and resolve underspecification across ambiguous settings. LHAW provides the first systematic framework for cost-sensitive evaluation of agent clarification behavior in long-horizon settings, enabling development of reliable autonomous systems.
Agentic Rubrics as Contextual Verifiers for SWE Agents
Jan 07, 2026Verification is critical for improving agents: it provides the reward signal for Reinforcement Learning and enables inference-time gains through Test-Time Scaling (TTS). Despite its importance, verification in software engineering (SWE) agent settings often relies on code execution, which can be difficult to scale due to environment setup overhead. Scalable alternatives such as patch classifiers and heuristic methods exist, but they are less grounded in codebase context and harder to interpret. To this end, we explore Agentic Rubrics: an expert agent interacts with the repository to create a context-grounded rubric checklist, and candidate patches are then scored against it without requiring test execution. On SWE-Bench Verified under parallel TTS evaluation, Agentic Rubrics achieve a score of 54.2% on Qwen3-Coder-30B-A3B and 40.6% on Qwen3-32B, with at least a +3.5 percentage-point gain over the strongest baseline in our comparison set. We further analyze rubric behavior, showing that rubric scores are consistent with ground-truth tests while also flagging issues that tests do not capture. Our ablations show that agentic context gathering is essential for producing codebase-specific, unambiguous criteria. Together, these results suggest that Agentic Rubrics provide an efficient, scalable, and granular verification signal for SWE agents.
Signed Link Representation in Continuous-Time Dynamic Signed Networks
Jul 07, 2022
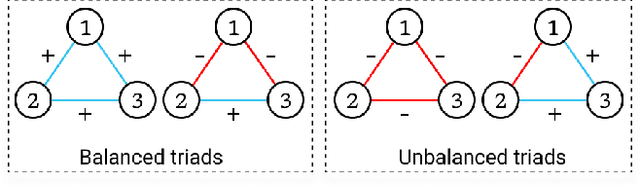

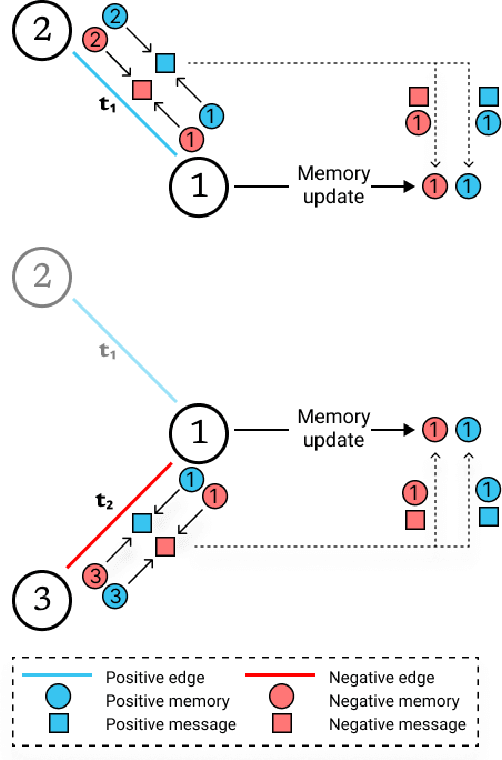
Signed networks allow us to model bi-faceted relationships and interactions, such as friend/enemy, support/oppose, etc. These interactions are often temporal in real datasets, where nodes and edges appear over time. Learning the dynamics of signed networks is thus crucial to effectively predict the sign and strength of future links. Existing works model either signed networks or dynamic networks but not both together. In this work, we study dynamic signed networks where links are both signed and evolving with time. Our model learns a Signed link's Evolution using Memory modules and Balanced Aggregation (hence, the name SEMBA). Each node maintains two separate memory encodings for positive and negative interactions. On the arrival of a new edge, each interacting node aggregates this signed information with its memories while exploiting balance theory. Node embeddings are generated using updated memories, which are then used to train for multiple downstream tasks, including link sign prediction and link weight prediction. Our results show that SEMBA outperforms all the baselines on the task of sign prediction by achieving up to an 8% increase in the AUC and up to a 50% reduction in FPR. Results on the task of predicting signed weights show that SEMBA reduces the mean squared error by 9% while achieving up to 69% reduction in the KL-divergence on the distribution of predicted signed weights.
AuthNet: A Deep Learning based Authentication Mechanism using Temporal Facial Feature Movements
Dec 19, 2020

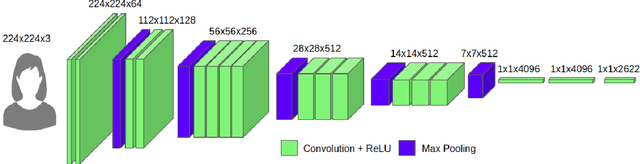

Biometric systems based on Machine learning and Deep learning are being extensively used as authentication mechanisms in resource-constrained environments like smartphones and other small computing devices. These AI-powered facial recognition mechanisms have gained enormous popularity in recent years due to their transparent, contact-less and non-invasive nature. While they are effective to a large extent, there are ways to gain unauthorized access using photographs, masks, glasses, etc. In this paper, we propose an alternative authentication mechanism that uses both facial recognition and the unique movements of that particular face while uttering a password, that is, the temporal facial feature movements. The proposed model is not inhibited by language barriers because a user can set a password in any language. When evaluated on the standard MIRACL-VC1 dataset, the proposed model achieved an accuracy of 98.1%, underscoring its effectiveness as an effective and robust system. The proposed method is also data-efficient since the model gave good results even when trained with only 10 positive video samples. The competence of the training of the network is also demonstrated by benchmarking the proposed system against various compounded Facial recognition and Lip reading models.