 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\textit{Who Speaks Matters}$: Analysing the Influence of the Speaker's Ethnicity on Hate Classification
Oct 27, 2024Large Language Models (LLMs) offer a lucrative promise for scalable content moderation, including hate speech detection. However, they are also known to be brittle and biased against marginalised communities and dialects. This requires their applications to high-stakes tasks like hate speech detection to be critically scrutinized. In this work, we investigate the robustness of hate speech classification using LLMs, particularly when explicit and implicit markers of the speaker's ethnicity are injected into the input. For the explicit markers, we inject a phrase that mentions the speaker's identity. For the implicit markers, we inject dialectal features. By analysing how frequently model outputs flip in the presence of these markers, we reveal varying degrees of brittleness across 4 popular LLMs and 5 ethnicities. We find that the presence of implicit dialect markers in inputs causes model outputs to flip more than the presence of explicit markers. Further, the percentage of flips varies across ethnicities. Finally, we find that larger models are more robust. Our findings indicate the need for exercising caution in deploying LLMs for high-stakes tasks like hate speech detection.
Extrinsic Evaluation of Cultural Competence in Large Language Models
Jun 17, 2024Productive interactions between diverse users and language technologies require outputs from the latter to be culturally relevant and sensitive. Prior works have evaluated models' knowledge of cultural norms, values, and artifacts, without considering how this knowledge manifests in downstream applications. In this work, we focus on extrinsic evaluation of cultural competence in two text generation tasks, open-ended question answering and story generation. We quantitatively and qualitatively evaluate model outputs when an explicit cue of culture, specifically nationality, is perturbed in the prompts. Although we find that model outputs do vary when varying nationalities and feature culturally relevant words, we also find weak correlations between text similarity of outputs for different countries and the cultural values of these countries. Finally, we discuss important considerations in designing comprehensive evaluation of cultural competence in user-facing tasks.
Cultural Re-contextualization of Fairness Research in Language Technologies in India
Nov 21, 2022

Recent research has revealed undesirable biases in NLP data and models. However, these efforts largely focus on social disparities in the West, and are not directly portable to other geo-cultural contexts. In this position paper, we outline a holistic research agenda to re-contextualize NLP fairness research for the Indian context, accounting for Indian societal context, bridging technological gaps in capability and resources, and adapting to Indian cultural values. We also summarize findings from an empirical study on various social biases along different axes of disparities relevant to India, demonstrating their prevalence in corpora and models.
Re-contextualizing Fairness in NLP: The Case of India
Oct 12, 2022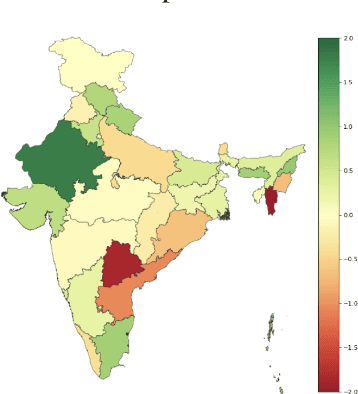

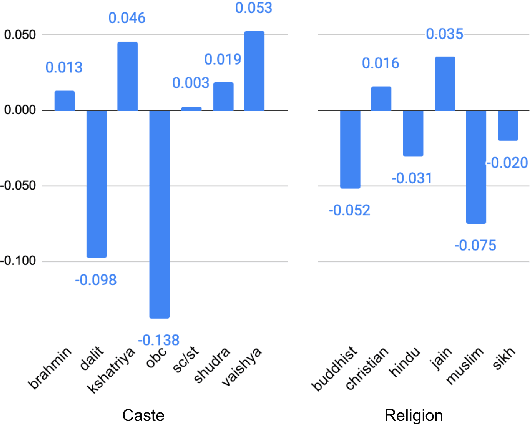
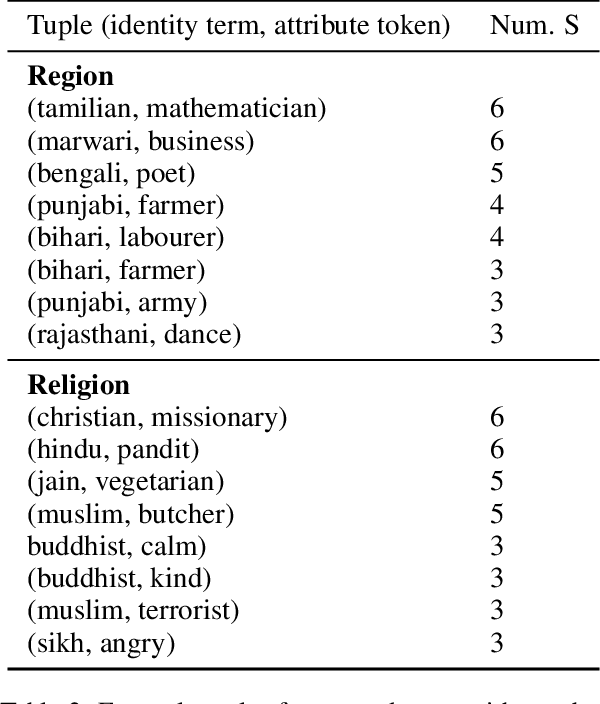
Recent research has revealed undesirable bi-ases in NLP data and models. However, theseefforts focus of social disparities in West, andare not directly portable to other geo-culturalcontexts. In this paper, we focus on NLP fair-ness in the context of India. We start witha brief account of the prominent axes of so-cial disparities in India. We build resourcesfor fairness evaluation in the Indian contextand use them to demonstrate prediction bi-ases along some of the axes. We then delvedeeper into social stereotypes for Region andReligion, demonstrating its prevalence in cor-pora and models. Finally, we outline a holis-tic research agenda to re-contextualize NLPfairness research for the Indian context, ac-counting for Indiansocietal context, bridgingtechnologicalgaps in NLP capabilities and re-sources, and adapting to Indian culturalvalues.While we focus on India, this framework canbe generalized to other geo-cultural contexts.
Multilingual CheckList: Generation and Evaluation
Mar 30, 2022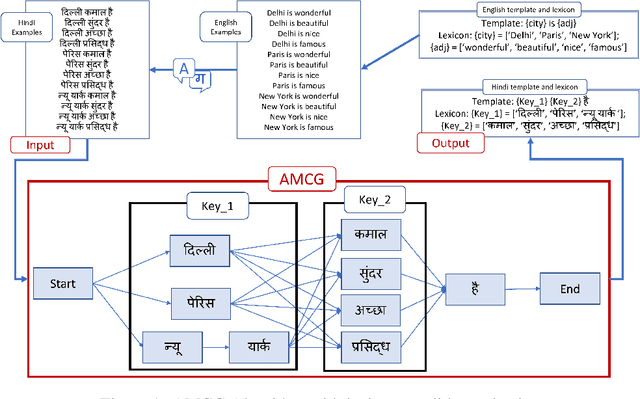
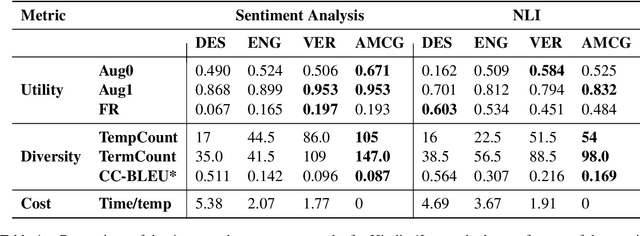
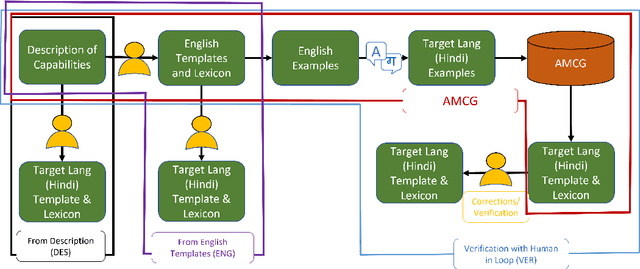
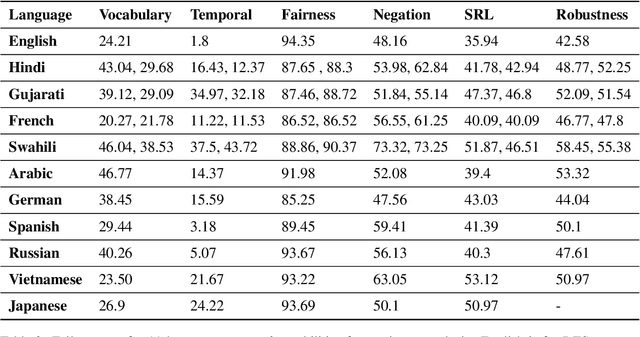
The recently proposed CheckList (Riberio et al,. 2020) approach to evaluation of NLP systems has revealed high failure rates for basic capabilities for multiple state-of-the-art and commercial models. However, the CheckList creation process is manual which creates a bottleneck towards creation of multilingual CheckLists catering 100s of languages. In this work, we explore multiple approaches to generate and evaluate the quality of Multilingual CheckList. We device an algorithm -- Automated Multilingual Checklist Generation (AMCG) for automatically transferring a CheckList from a source to a target language that relies on a reasonable machine translation system. We then compare the CheckList generated by AMCG with CheckLists generated with different levels of human intervention. Through in-depth crosslingual experiments between English and Hindi, and broad multilingual experiments spanning 11 languages, we show that the automatic approach can provide accurate estimates of failure rates of a model across capabilities, as would a human-verified CheckList, and better than CheckLists generated by humans from scratch.
Fake News Detection: Experiments and Approaches beyond Linguistic Features
Sep 27, 2021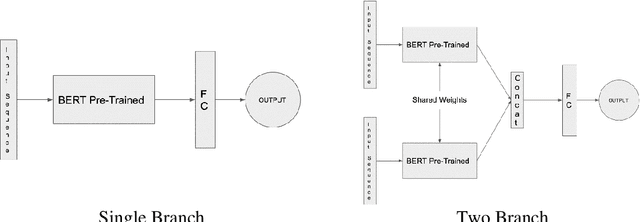
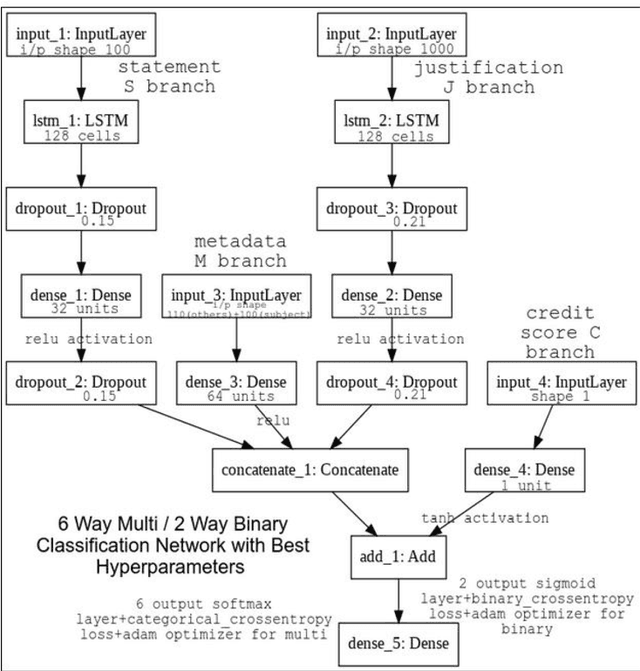
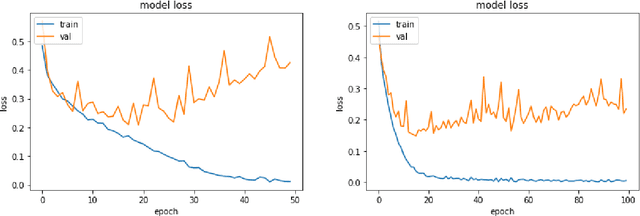

Easier access to the internet and social media has made disseminating information through online sources very easy. Sources like Facebook, Twitter, online news sites and personal blogs of self-proclaimed journalists have become significant players in providing news content. The sheer amount of information and the speed at which it is generated online makes it practically beyond the scope of human verification. There is, hence, a pressing need to develop technologies that can assist humans with automatic fact-checking and reliable identification of fake news. This paper summarizes the multiple approaches that were undertaken and the experiments that were carried out for the task. Credibility information and metadata associated with the news article have been used for improved results. The experiments also show how modelling justification or evidence can lead to improved results. Additionally, the use of visual features in addition to linguistic features is demonstrated. A detailed comparison of the results showing that our models perform significantly well when compared to robust baselines as well as state-of-the-art models are presented.
On the Universality of Deep COntextual Language Models
Sep 15, 2021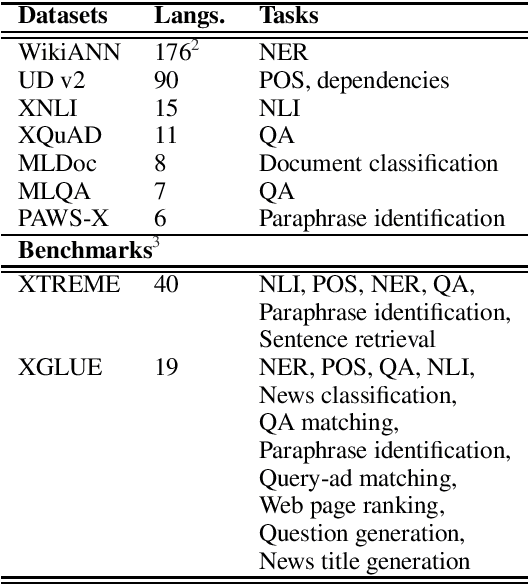
Deep Contextual Language Models (LMs) like ELMO, BERT, and their successors dominate the landscape of Natural Language Processing due to their ability to scale across multiple tasks rapidly by pre-training a single model, followed by task-specific fine-tuning. Furthermore, multilingual versions of such models like XLM-R and mBERT have given promising results in zero-shot cross-lingual transfer, potentially enabling NLP applications in many under-served and under-resourced languages. Due to this initial success, pre-trained models are being used as `Universal Language Models' as the starting point across diverse tasks, domains, and languages. This work explores the notion of `Universality' by identifying seven dimensions across which a universal model should be able to scale, that is, perform equally well or reasonably well, to be useful across diverse settings. We outline the current theoretical and empirical results that support model performance across these dimensions, along with extensions that may help address some of their current limitations. Through this survey, we lay the foundation for understanding the capabilities and limitations of massive contextual language models and help discern research gaps and directions for future work to make these LMs inclusive and fair to diverse applications, users, and linguistic phenomena.