 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgebitsa_nlp@LT-EDI-ACL2022: Leveraging Pretrained Language Models for Detecting Homophobia and Transphobia in Social Media Comments
Apr 09, 2022



Online social networks are ubiquitous and user-friendly. Nevertheless, it is vital to detect and moderate offensive content to maintain decency and empathy. However, mining social media texts is a complex task since users don't adhere to any fixed patterns. Comments can be written in any combination of languages and many of them may be low-resource. In this paper, we present our system for the LT-EDI shared task on detecting homophobia and transphobia in social media comments. We experiment with a number of monolingual and multilingual transformer based models such as mBERT along with a data augmentation technique for tackling class imbalance. Such pretrained large models have recently shown tremendous success on a variety of benchmark tasks in natural language processing. We observe their performance on a carefully annotated, real life dataset of YouTube comments in English as well as Tamil. Our submission achieved ranks 9, 6 and 3 with a macro-averaged F1-score of 0.42, 0.64 and 0.58 in the English, Tamil and Tamil-English subtasks respectively. The code for the system has been open sourced.
On the Universality of Deep COntextual Language Models
Sep 15, 2021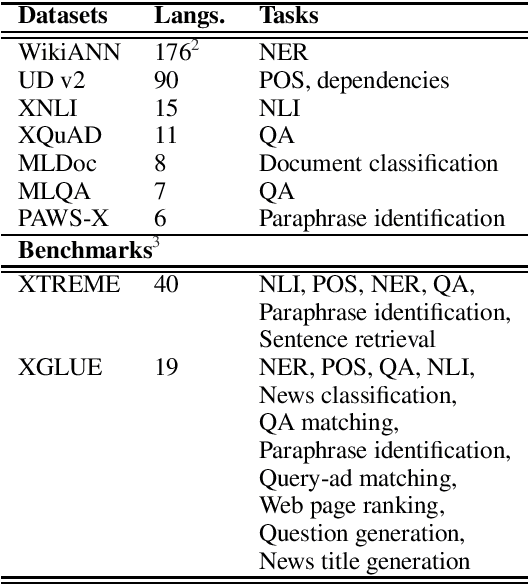
Deep Contextual Language Models (LMs) like ELMO, BERT, and their successors dominate the landscape of Natural Language Processing due to their ability to scale across multiple tasks rapidly by pre-training a single model, followed by task-specific fine-tuning. Furthermore, multilingual versions of such models like XLM-R and mBERT have given promising results in zero-shot cross-lingual transfer, potentially enabling NLP applications in many under-served and under-resourced languages. Due to this initial success, pre-trained models are being used as `Universal Language Models' as the starting point across diverse tasks, domains, and languages. This work explores the notion of `Universality' by identifying seven dimensions across which a universal model should be able to scale, that is, perform equally well or reasonably well, to be useful across diverse settings. We outline the current theoretical and empirical results that support model performance across these dimensions, along with extensions that may help address some of their current limitations. Through this survey, we lay the foundation for understanding the capabilities and limitations of massive contextual language models and help discern research gaps and directions for future work to make these LMs inclusive and fair to diverse applications, users, and linguistic phenomena.