 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScience Consultant Agent
Dec 18, 2025The Science Consultant Agent is a web-based Artificial Intelligence (AI) tool that helps practitioners select and implement the most effective modeling strategy for AI-based solutions. It operates through four core components: Questionnaire, Smart Fill, Research-Guided Recommendation, and Prototype Builder. By combining structured questionnaires, literature-backed solution recommendations, and prototype generation, the Science Consultant Agent accelerates development for everyone from Product Managers and Software Developers to Researchers. The full pipeline is illustrated in Figure 1.
InData: Towards Secure Multi-Step, Tool-Based Data Analysis
Nov 14, 2025Large language model agents for data analysis typically generate and execute code directly on databases. However, when applied to sensitive data, this approach poses significant security risks. To address this issue, we propose a security-motivated alternative: restrict LLMs from direct code generation and data access, and require them to interact with data exclusively through a predefined set of secure, verified tools. Although recent tool-use benchmarks exist, they primarily target tool selection and simple execution rather than the compositional, multi-step reasoning needed for complex data analysis. To reduce this gap, we introduce Indirect Data Engagement (InData), a dataset designed to assess LLMs' multi-step tool-based reasoning ability. InData includes data analysis questions at three difficulty levels--Easy, Medium, and Hard--capturing increasing reasoning complexity. We benchmark 15 open-source LLMs on InData and find that while large models (e.g., gpt-oss-120b) achieve high accuracy on Easy tasks (97.3%), performance drops sharply on Hard tasks (69.6%). These results show that current LLMs still lack robust multi-step tool-based reasoning ability. With InData, we take a step toward enabling the development and evaluation of LLMs with stronger multi-step tool-use capabilities. We will publicly release the dataset and code.
ClinStructor: AI-Powered Structuring of Unstructured Clinical Texts
Nov 14, 2025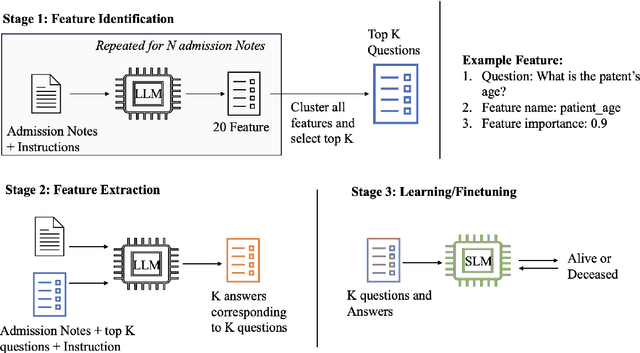

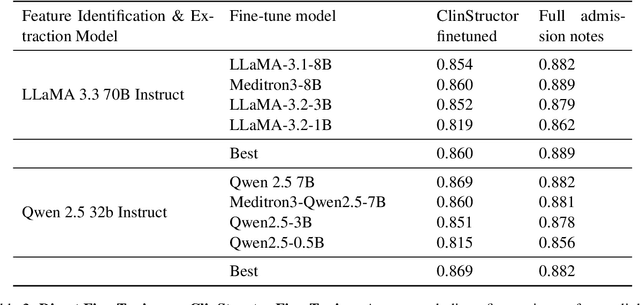
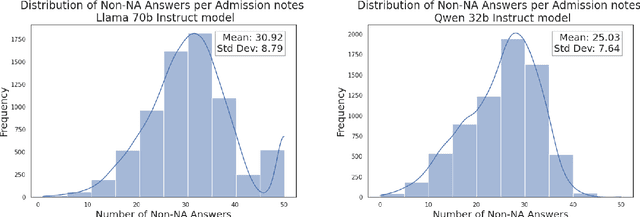
Clinical notes contain valuable, context-rich information, but their unstructured format introduces several challenges, including unintended biases (e.g., gender or racial bias), and poor generalization across clinical settings (e.g., models trained on one EHR system may perform poorly on another due to format differences) and poor interpretability. To address these issues, we present ClinStructor, a pipeline that leverages large language models (LLMs) to convert clinical free-text into structured, task-specific question-answer pairs prior to predictive modeling. Our method substantially enhances transparency and controllability and only leads to a modest reduction in predictive performance (a 2-3% drop in AUC), compared to direct fine-tuning, on the ICU mortality prediction task. ClinStructor lays a strong foundation for building reliable, interpretable, and generalizable machine learning models in clinical environments.
Additive Large Language Models for Semi-Structured Text
Nov 14, 2025Large Language Models have advanced clinical text classification, but their opaque predictions remain a critical barrier to practical adoption in research and clinical settings where investigators and physicians need to understand which parts of a patient's record drive risk signals. To address this challenge, we introduce \textbf{CALM}, short for \textbf{Classification with Additive Large Language Models}, an interpretable framework for semi-structured text where inputs are composed of semantically meaningful components, such as sections of an admission note or question-answer fields from an intake form. CALM predicts outcomes as the additive sum of each component's contribution, making these contributions part of the forward computation itself and enabling faithful explanations at both the patient and population level. The additive structure also enables clear visualizations, such as component-level risk curves similar to those used in generalized additive models, making the learned relationships easier to inspect and communicate. Although CALM expects semi-structured inputs, many clinical documents already have this form, and similar structure can often be automatically extracted from free-text notes. CALM achieves performance comparable to conventional LLM classifiers while improving trust, supporting quality-assurance checks, and revealing clinically meaningful patterns during model development and auditing.
Breaking the Batch Barrier (B3) of Contrastive Learning via Smart Batch Mining
May 16, 2025Contrastive learning (CL) is a prevalent technique for training embedding models, which pulls semantically similar examples (positives) closer in the representation space while pushing dissimilar ones (negatives) further apart. A key source of negatives are 'in-batch' examples, i.e., positives from other examples in the batch. Effectiveness of such models is hence strongly influenced by the size and quality of training batches. In this work, we propose 'Breaking the Batch Barrier' (B3), a novel batch construction strategy designed to curate high-quality batches for CL. Our approach begins by using a pretrained teacher embedding model to rank all examples in the dataset, from which a sparse similarity graph is constructed. A community detection algorithm is then applied to this graph to identify clusters of examples that serve as strong negatives for one another. The clusters are then used to construct batches that are rich in in-batch negatives. Empirical results on the MMEB multimodal embedding benchmark (36 tasks) demonstrate that our method sets a new state of the art, outperforming previous best methods by +1.3 and +2.9 points at the 7B and 2B model scales, respectively. Notably, models trained with B3 surpass existing state-of-the-art results even with a batch size as small as 64, which is 4-16x smaller than that required by other methods.
A Study on Leveraging Search and Self-Feedback for Agent Reasoning
Feb 17, 2025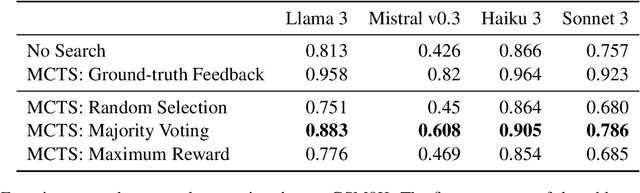
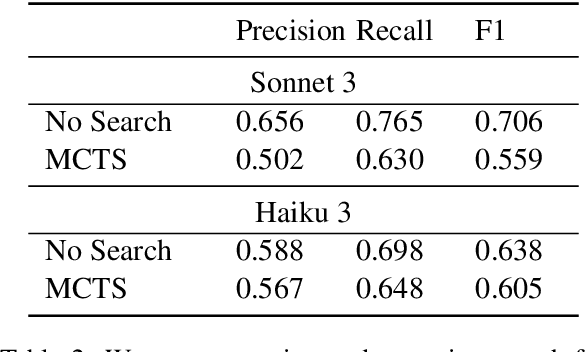

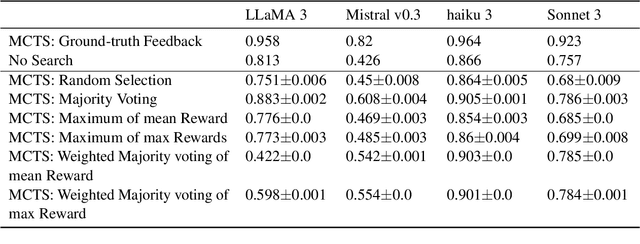
Recent works have demonstrated that incorporating search during inference can significantly improve reasoning capabilities of language agents. Some approaches may make use of the ground truth or rely on model's own generated feedback. The search algorithm uses this feedback to then produce values that will update its criterion for exploring and exploiting various reasoning paths. In this study, we investigate how search and model's self-feedback can be leveraged for reasoning tasks. First, we explore differences in ground-truth feedback and self-feedback during search for math reasoning. Second, we observe limitations in applying search techniques to more complex tasks like tool-calling and design domain-specific approaches to address these gaps. Our experiments reveal challenges related to generalization when solely relying on self-feedback during search. For search to work effectively, either access to the ground-truth is needed or feedback mechanisms need to be carefully designed for the specific task.
Taxonomy Expansion for Named Entity Recognition
May 22, 2023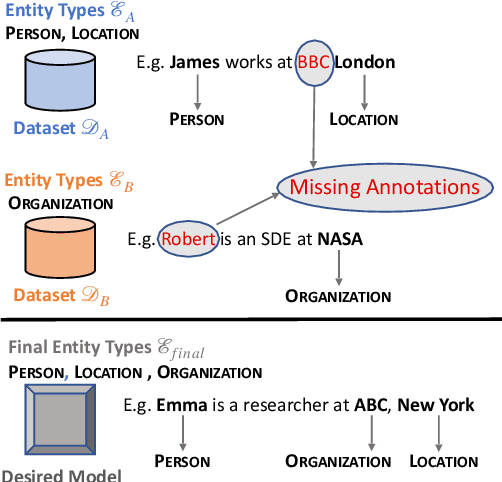
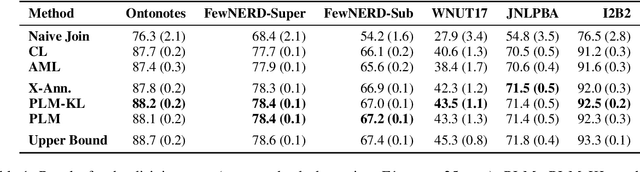
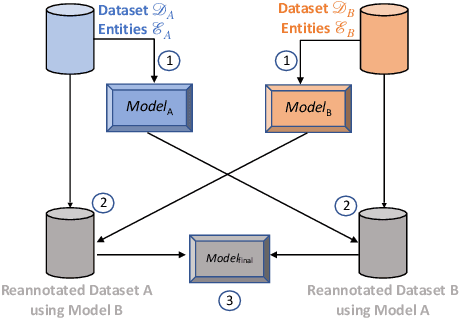
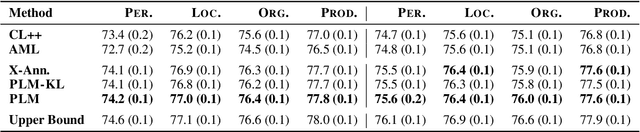
Training a Named Entity Recognition (NER) model often involves fixing a taxonomy of entity types. However, requirements evolve and we might need the NER model to recognize additional entity types. A simple approach is to re-annotate entire dataset with both existing and additional entity types and then train the model on the re-annotated dataset. However, this is an extremely laborious task. To remedy this, we propose a novel approach called Partial Label Model (PLM) that uses only partially annotated datasets. We experiment with 6 diverse datasets and show that PLM consistently performs better than most other approaches (0.5 - 2.5 F1), including in novel settings for taxonomy expansion not considered in prior work. The gap between PLM and all other approaches is especially large in settings where there is limited data available for the additional entity types (as much as 11 F1), thus suggesting a more cost effective approaches to taxonomy expansion.
Multilingual CheckList: Generation and Evaluation
Mar 30, 2022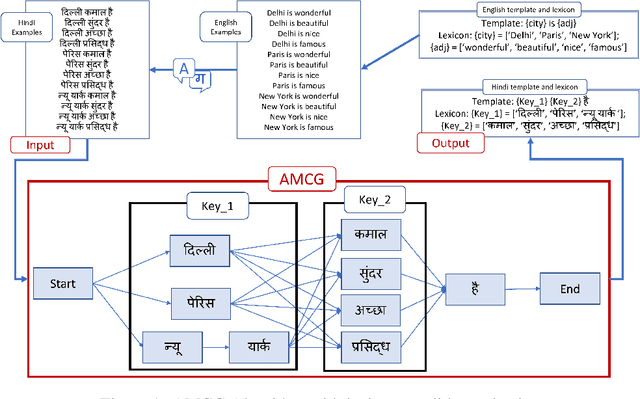
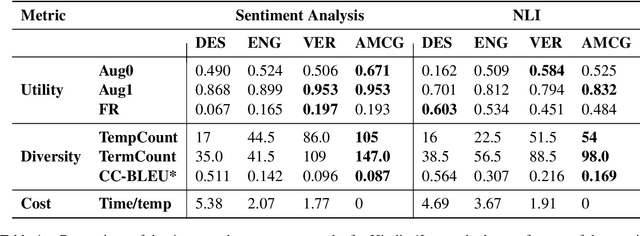
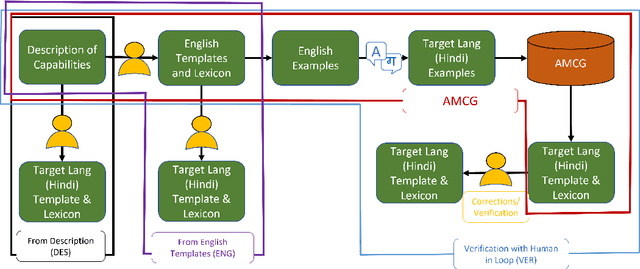
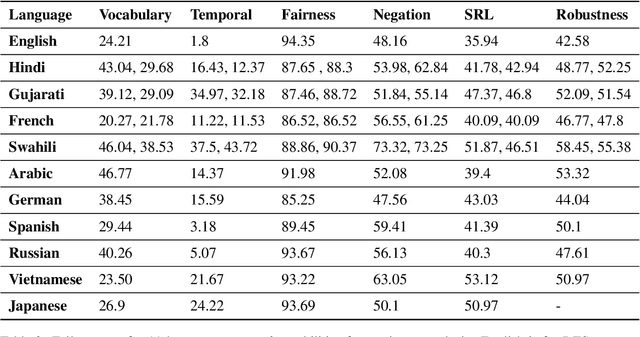
The recently proposed CheckList (Riberio et al,. 2020) approach to evaluation of NLP systems has revealed high failure rates for basic capabilities for multiple state-of-the-art and commercial models. However, the CheckList creation process is manual which creates a bottleneck towards creation of multilingual CheckLists catering 100s of languages. In this work, we explore multiple approaches to generate and evaluate the quality of Multilingual CheckList. We device an algorithm -- Automated Multilingual Checklist Generation (AMCG) for automatically transferring a CheckList from a source to a target language that relies on a reasonable machine translation system. We then compare the CheckList generated by AMCG with CheckLists generated with different levels of human intervention. Through in-depth crosslingual experiments between English and Hindi, and broad multilingual experiments spanning 11 languages, we show that the automatic approach can provide accurate estimates of failure rates of a model across capabilities, as would a human-verified CheckList, and better than CheckLists generated by humans from scratch.
Revisiting Methods for Finding Influential Examples
Nov 08, 2021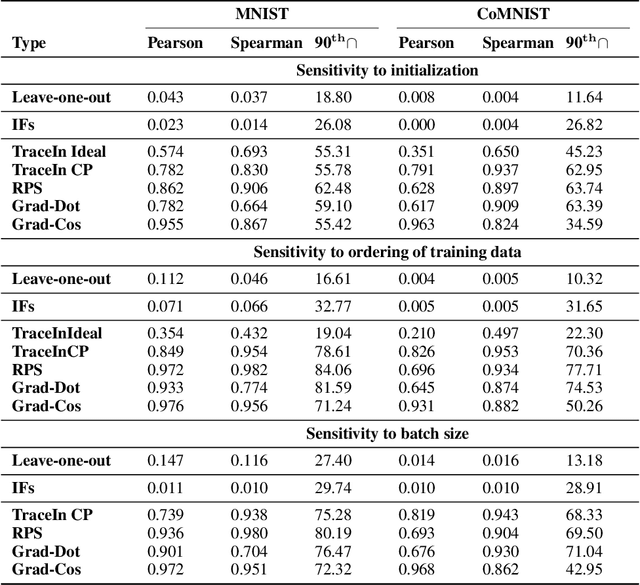
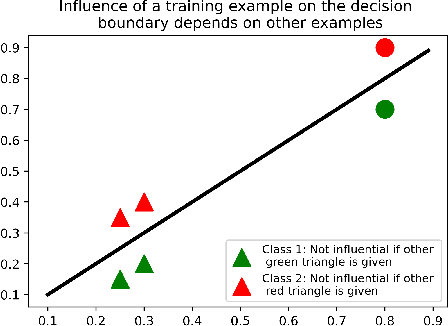
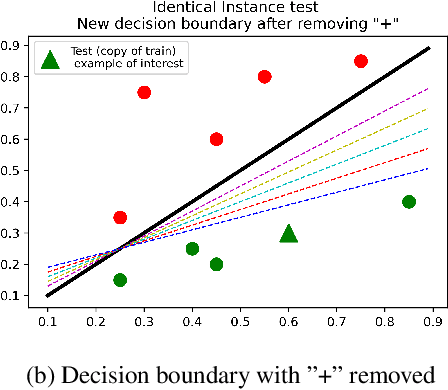
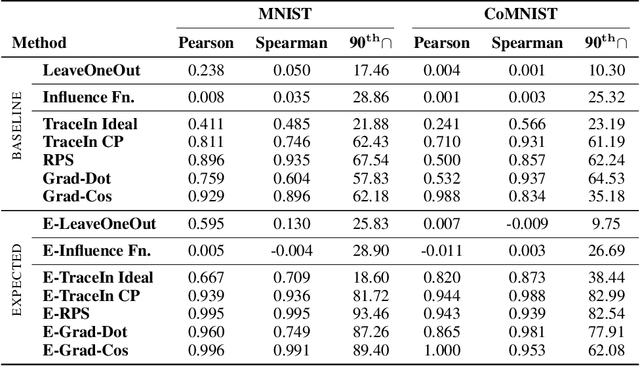
Several instance-based explainability methods for finding influential training examples for test-time decisions have been proposed recently, including Influence Functions, TraceIn, Representer Point Selection, Grad-Dot, and Grad-Cos. Typically these methods are evaluated using LOO influence (Cook's distance) as a gold standard, or using various heuristics. In this paper, we show that all of the above methods are unstable, i.e., extremely sensitive to initialization, ordering of the training data, and batch size. We suggest that this is a natural consequence of how in the literature, the influence of examples is assumed to be independent of model state and other examples -- and argue it is not. We show that LOO influence and heuristics are, as a result, poor metrics to measure the quality of instance-based explanations, and instead propose to evaluate such explanations by their ability to detect poisoning attacks. Further, we provide a simple, yet effective baseline to improve all of the above methods and show how it leads to very significant improvements on downstream tasks.
Analyzing the Effects of Reasoning Types on Cross-Lingual Transfer Performance
Oct 05, 2021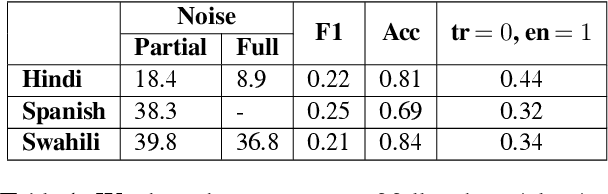
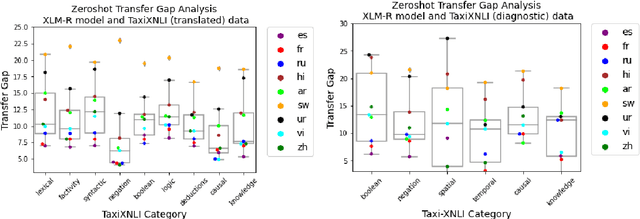
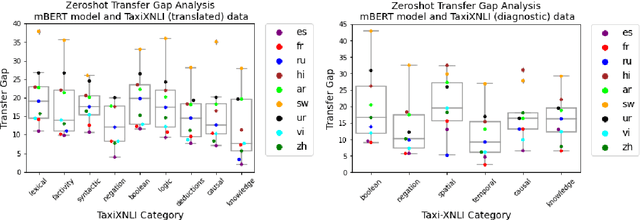
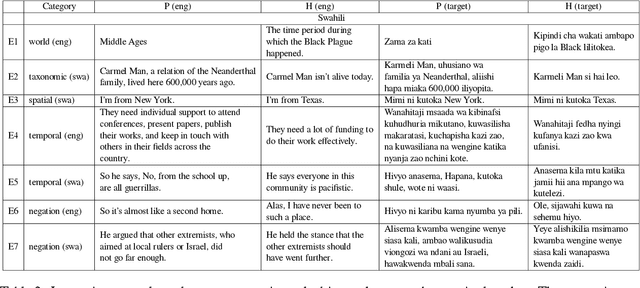
Multilingual language models achieve impressive zero-shot accuracies in many languages in complex tasks such as Natural Language Inference (NLI). Examples in NLI (and equivalent complex tasks) often pertain to various types of sub-tasks, requiring different kinds of reasoning. Certain types of reasoning have proven to be more difficult to learn in a monolingual context, and in the crosslingual context, similar observations may shed light on zero-shot transfer efficiency and few-shot sample selection. Hence, to investigate the effects of types of reasoning on transfer performance, we propose a category-annotated multilingual NLI dataset and discuss the challenges to scale monolingual annotations to multiple languages. We statistically observe interesting effects that the confluence of reasoning types and language similarities have on transfer performance.