 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdditive Large Language Models for Semi-Structured Text
Nov 14, 2025Large Language Models have advanced clinical text classification, but their opaque predictions remain a critical barrier to practical adoption in research and clinical settings where investigators and physicians need to understand which parts of a patient's record drive risk signals. To address this challenge, we introduce \textbf{CALM}, short for \textbf{Classification with Additive Large Language Models}, an interpretable framework for semi-structured text where inputs are composed of semantically meaningful components, such as sections of an admission note or question-answer fields from an intake form. CALM predicts outcomes as the additive sum of each component's contribution, making these contributions part of the forward computation itself and enabling faithful explanations at both the patient and population level. The additive structure also enables clear visualizations, such as component-level risk curves similar to those used in generalized additive models, making the learned relationships easier to inspect and communicate. Although CALM expects semi-structured inputs, many clinical documents already have this form, and similar structure can often be automatically extracted from free-text notes. CALM achieves performance comparable to conventional LLM classifiers while improving trust, supporting quality-assurance checks, and revealing clinically meaningful patterns during model development and auditing.
ClinStructor: AI-Powered Structuring of Unstructured Clinical Texts
Nov 14, 2025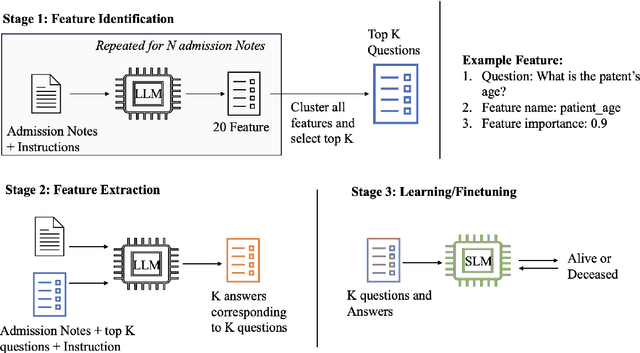

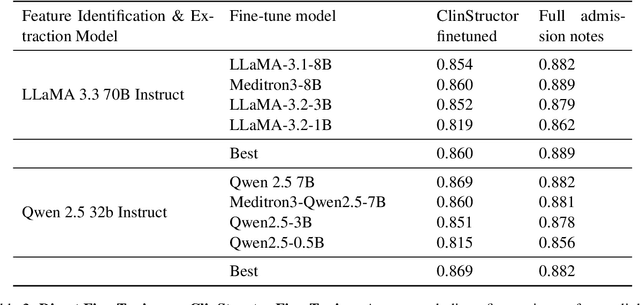
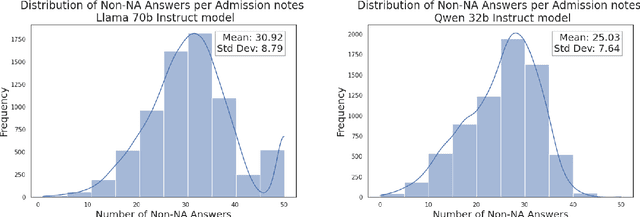
Clinical notes contain valuable, context-rich information, but their unstructured format introduces several challenges, including unintended biases (e.g., gender or racial bias), and poor generalization across clinical settings (e.g., models trained on one EHR system may perform poorly on another due to format differences) and poor interpretability. To address these issues, we present ClinStructor, a pipeline that leverages large language models (LLMs) to convert clinical free-text into structured, task-specific question-answer pairs prior to predictive modeling. Our method substantially enhances transparency and controllability and only leads to a modest reduction in predictive performance (a 2-3% drop in AUC), compared to direct fine-tuning, on the ICU mortality prediction task. ClinStructor lays a strong foundation for building reliable, interpretable, and generalizable machine learning models in clinical environments.
InData: Towards Secure Multi-Step, Tool-Based Data Analysis
Nov 14, 2025Large language model agents for data analysis typically generate and execute code directly on databases. However, when applied to sensitive data, this approach poses significant security risks. To address this issue, we propose a security-motivated alternative: restrict LLMs from direct code generation and data access, and require them to interact with data exclusively through a predefined set of secure, verified tools. Although recent tool-use benchmarks exist, they primarily target tool selection and simple execution rather than the compositional, multi-step reasoning needed for complex data analysis. To reduce this gap, we introduce Indirect Data Engagement (InData), a dataset designed to assess LLMs' multi-step tool-based reasoning ability. InData includes data analysis questions at three difficulty levels--Easy, Medium, and Hard--capturing increasing reasoning complexity. We benchmark 15 open-source LLMs on InData and find that while large models (e.g., gpt-oss-120b) achieve high accuracy on Easy tasks (97.3%), performance drops sharply on Hard tasks (69.6%). These results show that current LLMs still lack robust multi-step tool-based reasoning ability. With InData, we take a step toward enabling the development and evaluation of LLMs with stronger multi-step tool-use capabilities. We will publicly release the dataset and code.
Breaking the Batch Barrier (B3) of Contrastive Learning via Smart Batch Mining
May 16, 2025Contrastive learning (CL) is a prevalent technique for training embedding models, which pulls semantically similar examples (positives) closer in the representation space while pushing dissimilar ones (negatives) further apart. A key source of negatives are 'in-batch' examples, i.e., positives from other examples in the batch. Effectiveness of such models is hence strongly influenced by the size and quality of training batches. In this work, we propose 'Breaking the Batch Barrier' (B3), a novel batch construction strategy designed to curate high-quality batches for CL. Our approach begins by using a pretrained teacher embedding model to rank all examples in the dataset, from which a sparse similarity graph is constructed. A community detection algorithm is then applied to this graph to identify clusters of examples that serve as strong negatives for one another. The clusters are then used to construct batches that are rich in in-batch negatives. Empirical results on the MMEB multimodal embedding benchmark (36 tasks) demonstrate that our method sets a new state of the art, outperforming previous best methods by +1.3 and +2.9 points at the 7B and 2B model scales, respectively. Notably, models trained with B3 surpass existing state-of-the-art results even with a batch size as small as 64, which is 4-16x smaller than that required by other methods.
Atomic Consistency Preference Optimization for Long-Form Question Answering
May 14, 2025Large Language Models (LLMs) frequently produce factoid hallucinations - plausible yet incorrect answers. A common mitigation strategy is model alignment, which improves factual accuracy by training on curated factual and non-factual pairs. However, this approach often relies on a stronger model (e.g., GPT-4) or an external knowledge base to assess factual correctness, which may not always be accessible. To address this, we propose Atomic Consistency Preference Optimization (ACPO), a self-supervised preference-tuning method that enhances factual accuracy without external supervision. ACPO leverages atomic consistency signals, i.e., the agreement of individual facts across multiple stochastic responses, to identify high- and low-quality data pairs for model alignment. By eliminating the need for costly GPT calls, ACPO provides a scalable and efficient approach to improving factoid question-answering. Despite being self-supervised, empirical results demonstrate that ACPO outperforms FactAlign, a strong supervised alignment baseline, by 1.95 points on the LongFact and BioGen datasets, highlighting its effectiveness in enhancing factual reliability without relying on external models or knowledge bases.
GenEOL: Harnessing the Generative Power of LLMs for Training-Free Sentence Embeddings
Oct 18, 2024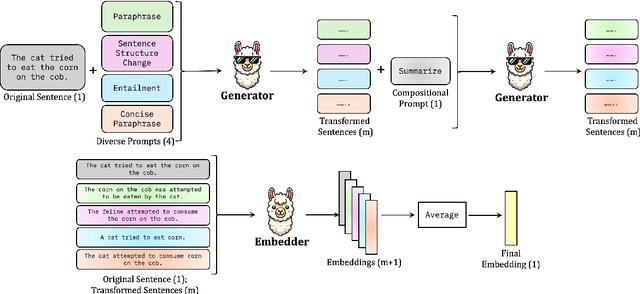
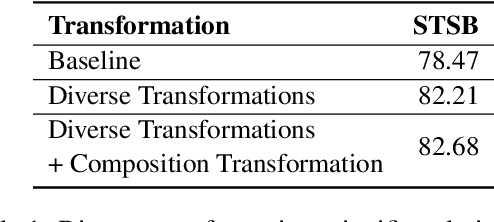
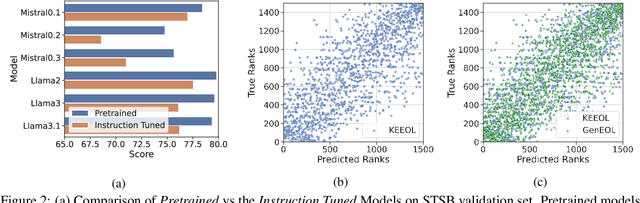
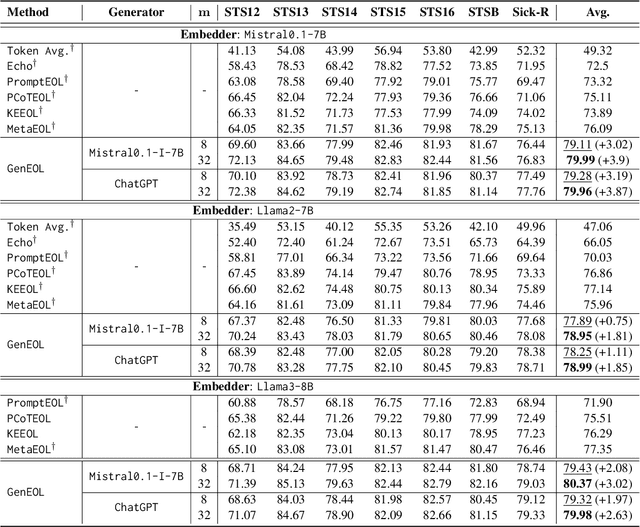
Training-free embedding methods directly leverage pretrained large language models (LLMs) to embed text, bypassing the costly and complex procedure of contrastive learning. Previous training-free embedding methods have mainly focused on optimizing embedding prompts and have overlooked the benefits of utilizing the generative abilities of LLMs. We propose a novel method, GenEOL, which uses LLMs to generate diverse transformations of a sentence that preserve its meaning, and aggregates the resulting embeddings of these transformations to enhance the overall sentence embedding. GenEOL significantly outperforms the existing training-free embedding methods by an average of 2.85 points across several LLMs on the sentence semantic text similarity (STS) benchmark. Our analysis shows that GenEOL stabilizes representation quality across LLM layers and is robust to perturbations of embedding prompts. GenEOL also achieves notable gains on multiple clustering, reranking and pair-classification tasks from the MTEB benchmark.
Atomic Self-Consistency for Better Long Form Generations
May 21, 2024
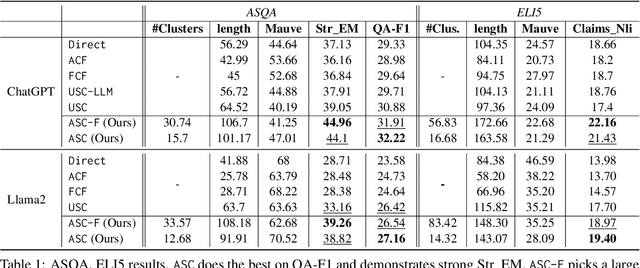
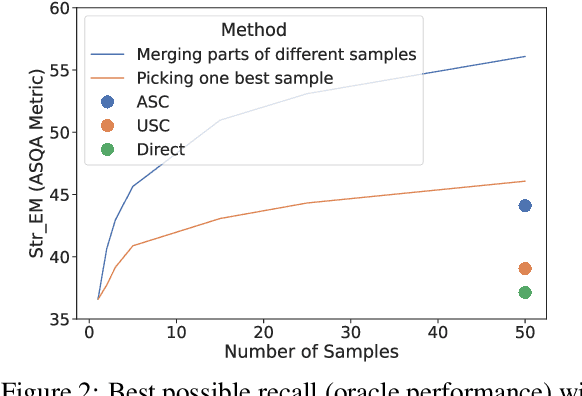
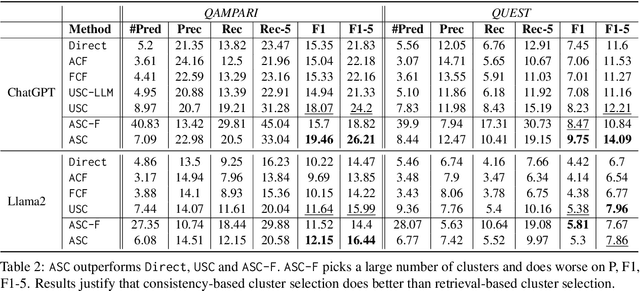
Recent work has aimed to improve LLM generations by filtering out hallucinations, thereby improving the precision of the information in responses. Correctness of a long-form response, however, also depends on the recall of multiple pieces of information relevant to the question. In this paper, we introduce Atomic Self-Consistency (ASC), a technique for improving the recall of relevant information in an LLM response. ASC follows recent work, Universal Self-Consistency (USC) in using multiple stochastic samples from an LLM to improve the long-form response. Unlike USC which only focuses on selecting the best single generation, ASC picks authentic subparts from the samples and merges them into a superior composite answer. Through extensive experiments and ablations, we show that merging relevant subparts of multiple samples performs significantly better than picking a single sample. ASC demonstrates significant gains over USC on multiple factoids and open-ended QA datasets - ASQA, QAMPARI, QUEST, ELI5 with ChatGPT and Llama2. Our analysis also reveals untapped potential for enhancing long-form generations using approach of merging multiple samples.
Calibrating Long-form Generations from Large Language Models
Feb 09, 2024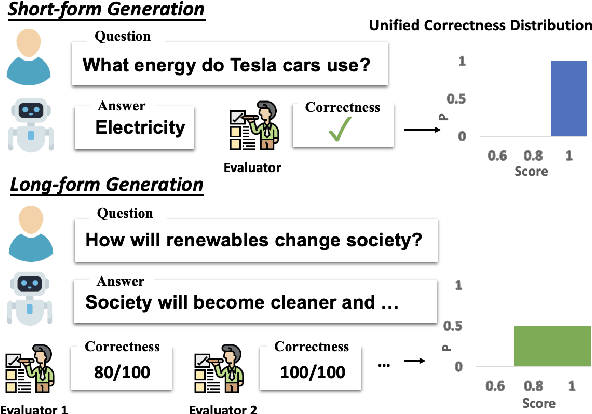
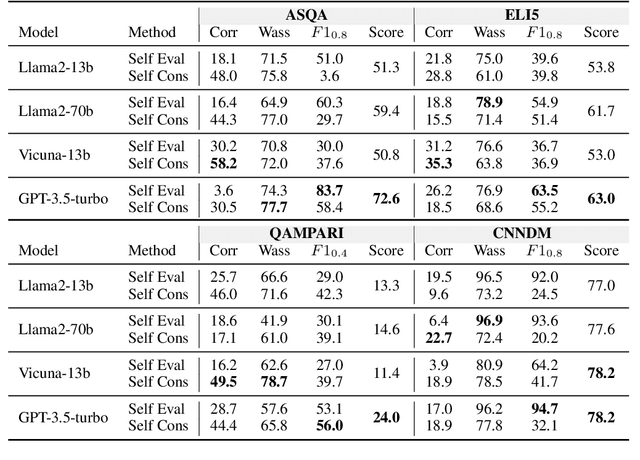
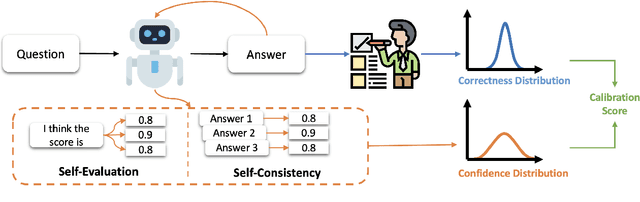
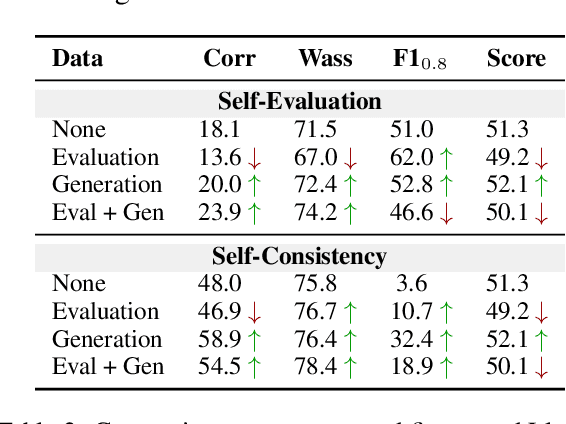
To enhance Large Language Models' (LLMs) reliability, calibration is essential -- the model's assessed confidence scores should align with the actual likelihood of its responses being correct. However, current confidence elicitation methods and calibration metrics typically rely on a binary true/false assessment of response correctness. This approach does not apply to long-form generation, where an answer can be partially correct. Addressing this gap, we introduce a unified calibration framework, in which both the correctness of the LLMs' responses and their associated confidence levels are treated as distributions across a range of scores. Within this framework, we develop three metrics to precisely evaluate LLM calibration and further propose two confidence elicitation methods based on self-consistency and self-evaluation. Our experiments, which include long-form QA and summarization tasks, demonstrate that larger models don't necessarily guarantee better calibration, that calibration performance is found to be metric-dependent, and that self-consistency methods excel in factoid datasets. We also find that calibration can be enhanced through techniques such as fine-tuning, integrating relevant source documents, scaling the temperature, and combining self-consistency with self-evaluation. Lastly, we showcase a practical application of our system: selecting and cascading open-source models and ChatGPT to optimize correctness given a limited API budget. This research not only challenges existing notions of LLM calibration but also offers practical methodologies for improving trustworthiness in long-form generation.
Longtonotes: OntoNotes with Longer Coreference Chains
Oct 07, 2022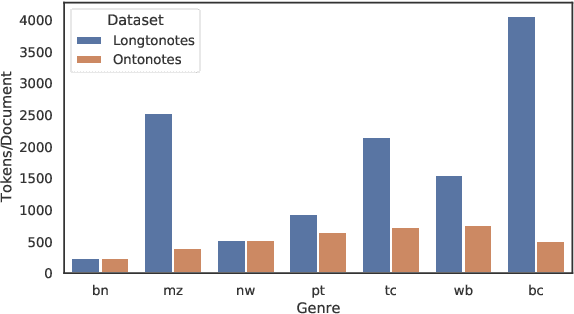
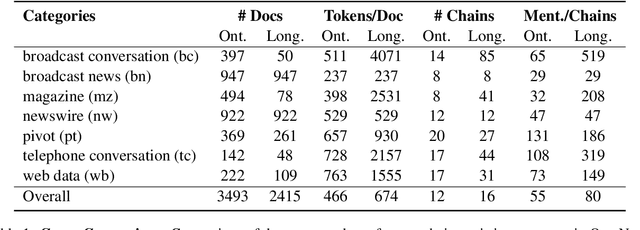
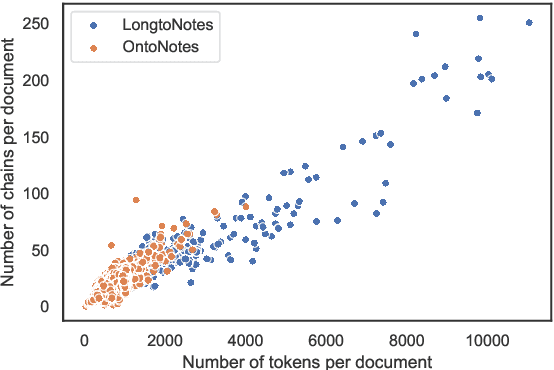
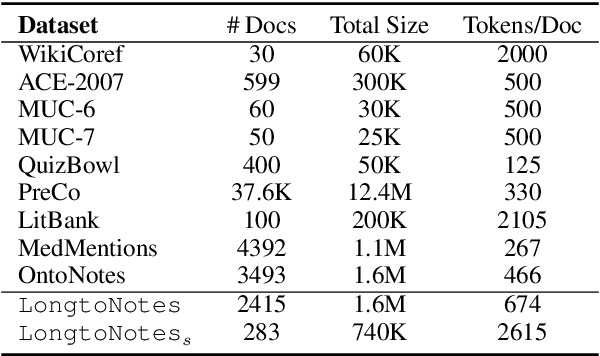
Ontonotes has served as the most important benchmark for coreference resolution. However, for ease of annotation, several long documents in Ontonotes were split into smaller parts. In this work, we build a corpus of coreference-annotated documents of significantly longer length than what is currently available. We do so by providing an accurate, manually-curated, merging of annotations from documents that were split into multiple parts in the original Ontonotes annotation process. The resulting corpus, which we call LongtoNotes contains documents in multiple genres of the English language with varying lengths, the longest of which are up to 8x the length of documents in Ontonotes, and 2x those in Litbank. We evaluate state-of-the-art neural coreference systems on this new corpus, analyze the relationships between model architectures/hyperparameters and document length on performance and efficiency of the models, and demonstrate areas of improvement in long-document coreference modeling revealed by our new corpus. Our data and code is available at: https://github.com/kumar-shridhar/LongtoNotes.