 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenEOL: Harnessing the Generative Power of LLMs for Training-Free Sentence Embeddings
Paper and Code
Oct 18, 2024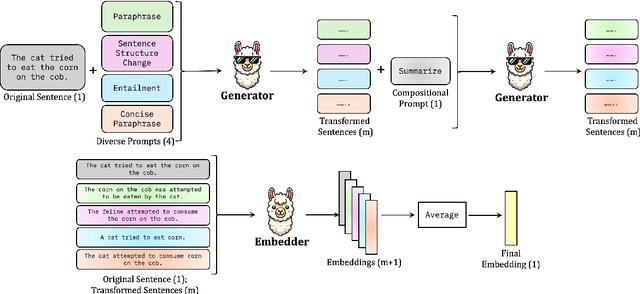
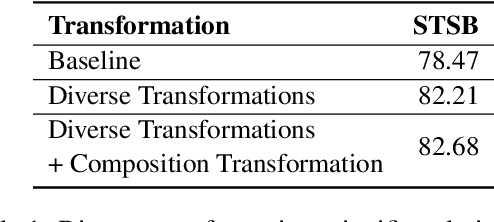
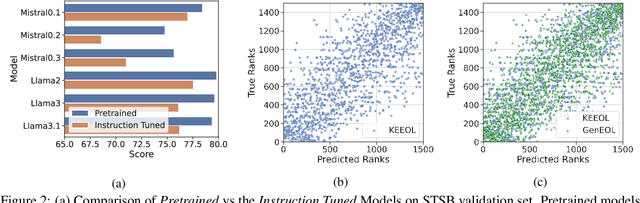
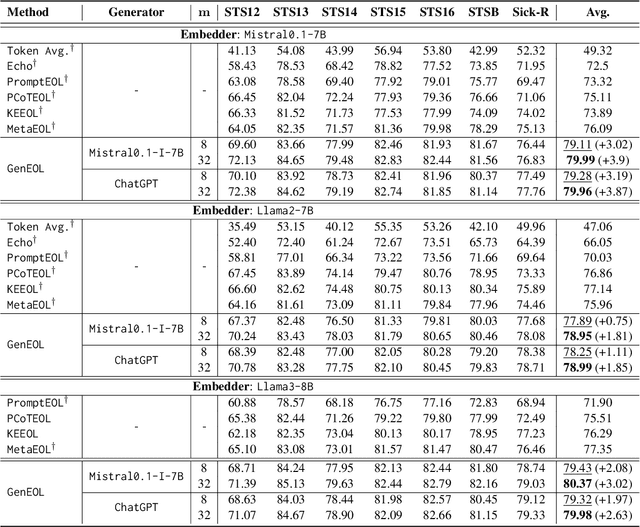
Training-free embedding methods directly leverage pretrained large language models (LLMs) to embed text, bypassing the costly and complex procedure of contrastive learning. Previous training-free embedding methods have mainly focused on optimizing embedding prompts and have overlooked the benefits of utilizing the generative abilities of LLMs. We propose a novel method, GenEOL, which uses LLMs to generate diverse transformations of a sentence that preserve its meaning, and aggregates the resulting embeddings of these transformations to enhance the overall sentence embedding. GenEOL significantly outperforms the existing training-free embedding methods by an average of 2.85 points across several LLMs on the sentence semantic text similarity (STS) benchmark. Our analysis shows that GenEOL stabilizes representation quality across LLM layers and is robust to perturbations of embedding prompts. GenEOL also achieves notable gains on multiple clustering, reranking and pair-classification tasks from the MTEB benchmark.