 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing LLM-Based Multi-Agent System with Textual Feedback: A Case Study on Software Development
May 22, 2025We have seen remarkable progress in large language models (LLMs) empowered multi-agent systems solving complex tasks necessitating cooperation among experts with diverse skills. However, optimizing LLM-based multi-agent systems remains challenging. In this work, we perform an empirical case study on group optimization of role-based multi-agent systems utilizing natural language feedback for challenging software development tasks under various evaluation dimensions. We propose a two-step agent prompts optimization pipeline: identifying underperforming agents with their failure explanations utilizing textual feedback and then optimizing system prompts of identified agents utilizing failure explanations. We then study the impact of various optimization settings on system performance with two comparison groups: online against offline optimization and individual against group optimization. For group optimization, we study two prompting strategies: one-pass and multi-pass prompting optimizations. Overall, we demonstrate the effectiveness of our optimization method for role-based multi-agent systems tackling software development tasks evaluated on diverse evaluation dimensions, and we investigate the impact of diverse optimization settings on group behaviors of the multi-agent systems to provide practical insights for future development.
A Study on Leveraging Search and Self-Feedback for Agent Reasoning
Feb 17, 2025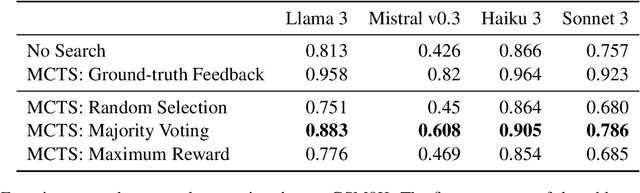
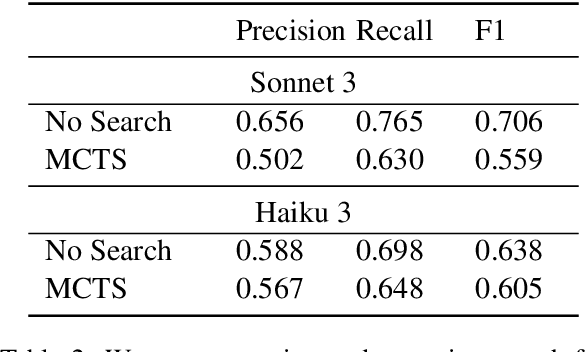

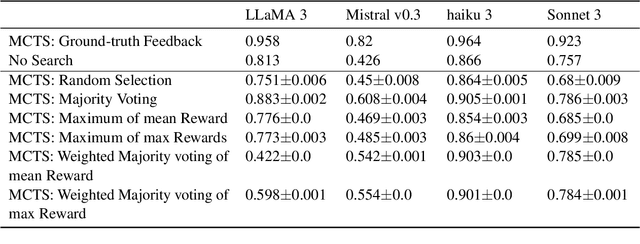
Recent works have demonstrated that incorporating search during inference can significantly improve reasoning capabilities of language agents. Some approaches may make use of the ground truth or rely on model's own generated feedback. The search algorithm uses this feedback to then produce values that will update its criterion for exploring and exploiting various reasoning paths. In this study, we investigate how search and model's self-feedback can be leveraged for reasoning tasks. First, we explore differences in ground-truth feedback and self-feedback during search for math reasoning. Second, we observe limitations in applying search techniques to more complex tasks like tool-calling and design domain-specific approaches to address these gaps. Our experiments reveal challenges related to generalization when solely relying on self-feedback during search. For search to work effectively, either access to the ground-truth is needed or feedback mechanisms need to be carefully designed for the specific task.
General Purpose Verification for Chain of Thought Prompting
Apr 30, 2024



Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
droidlet: modular, heterogenous, multi-modal agents
Jan 25, 2021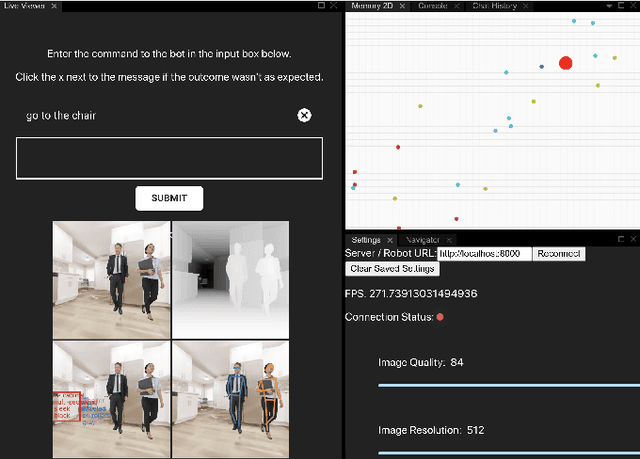
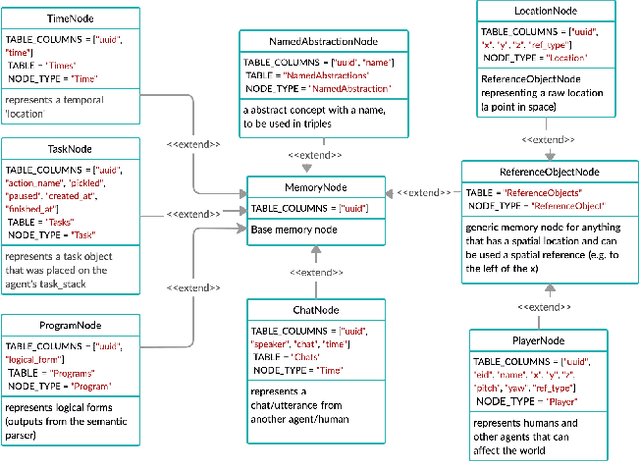
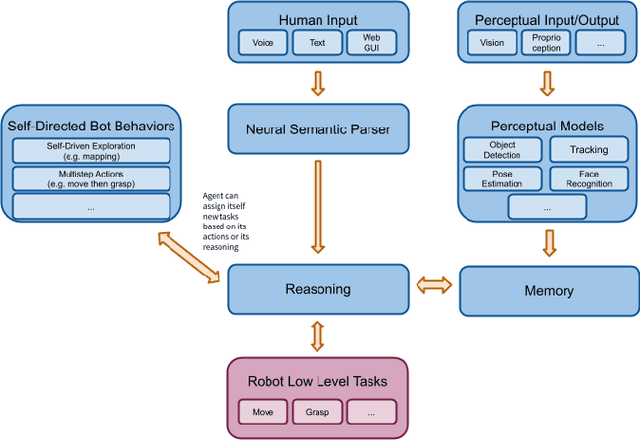
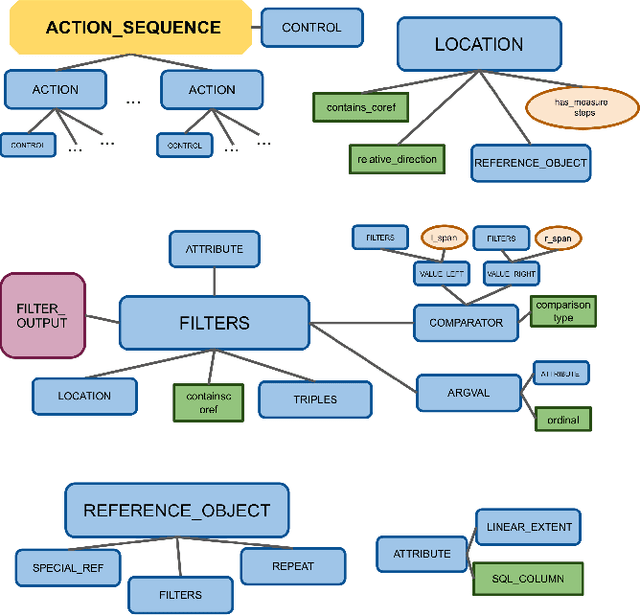
In recent years, there have been significant advances in building end-to-end Machine Learning (ML) systems that learn at scale. But most of these systems are: (a) isolated (perception, speech, or language only); (b) trained on static datasets. On the other hand, in the field of robotics, large-scale learning has always been difficult. Supervision is hard to gather and real world physical interactions are expensive. In this work we introduce and open-source droidlet, a modular, heterogeneous agent architecture and platform. It allows us to exploit both large-scale static datasets in perception and language and sophisticated heuristics often used in robotics; and provides tools for interactive annotation. Furthermore, it brings together perception, language and action onto one platform, providing a path towards agents that learn from the richness of real world interactions.