 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrect, Concise and Complete: Multi-stage Training For Adaptive Reasoning
Jan 06, 2026The reasoning capabilities of large language models (LLMs) have improved substantially through increased test-time computation, typically in the form of intermediate tokens known as chain-of-thought (CoT). However, CoT often becomes unnecessarily long, increasing computation cost without actual accuracy gains or sometimes even degrading performance, a phenomenon known as ``overthinking''. We propose a multi-stage efficient reasoning method that combines supervised fine-tuning -- via rejection sampling or reasoning trace reformatting -- with reinforcement learning using an adaptive length penalty. We introduce a lightweight reward function that penalizes tokens generated after the first correct answer but encouraging self-verification only when beneficial. We conduct a holistic evaluation across seven diverse reasoning tasks, analyzing the accuracy-response length trade-off. Our approach reduces response length by an average of 28\% for 8B models and 40\% for 32B models, while incurring only minor performance drops of 1.6 and 2.5 points, respectively. Despite its conceptual simplicity, it achieves a superior trade-off compared to more complex state-of-the-art efficient reasoning methods, scoring 76.6, in terms of the area under the Overthinking-Adjusted Accuracy curve ($\text{AUC}_{\text{OAA}}$) -- 5 points above the base model and 2.5 points above the second-best approach.
Towards Long Context Hallucination Detection
Apr 28, 2025Large Language Models (LLMs) have demonstrated remarkable performance across various tasks. However, they are prone to contextual hallucination, generating information that is either unsubstantiated or contradictory to the given context. Although many studies have investigated contextual hallucinations in LLMs, addressing them in long-context inputs remains an open problem. In this work, we take an initial step toward solving this problem by constructing a dataset specifically designed for long-context hallucination detection. Furthermore, we propose a novel architecture that enables pre-trained encoder models, such as BERT, to process long contexts and effectively detect contextual hallucinations through a decomposition and aggregation mechanism. Our experimental results show that the proposed architecture significantly outperforms previous models of similar size as well as LLM-based models across various metrics, while providing substantially faster inference.
Open Domain Question Answering with Conflicting Contexts
Oct 16, 2024



Open domain question answering systems frequently rely on information retrieved from large collections of text (such as the Web) to answer questions. However, such collections of text often contain conflicting information, and indiscriminately depending on this information may result in untruthful and inaccurate answers. To understand the gravity of this problem, we collect a human-annotated dataset, Question Answering with Conflicting Contexts (QACC), and find that as much as 25% of unambiguous, open domain questions can lead to conflicting contexts when retrieved using Google Search. We evaluate and benchmark three powerful Large Language Models (LLMs) with our dataset QACC and demonstrate their limitations in effectively addressing questions with conflicting information. To explore how humans reason through conflicting contexts, we request our annotators to provide explanations for their selections of correct answers. We demonstrate that by finetuning LLMs to explain their answers, we can introduce richer information into their training that guide them through the process of reasoning with conflicting contexts.
Unraveling and Mitigating Safety Alignment Degradation of Vision-Language Models
Oct 11, 2024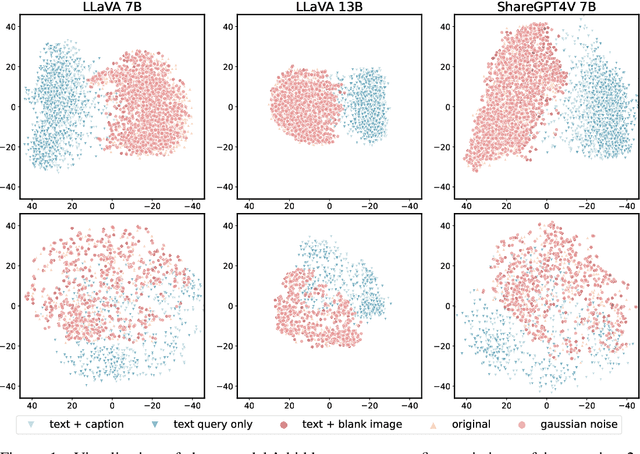
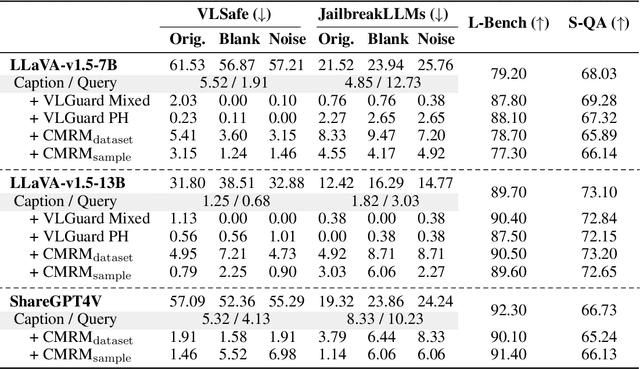
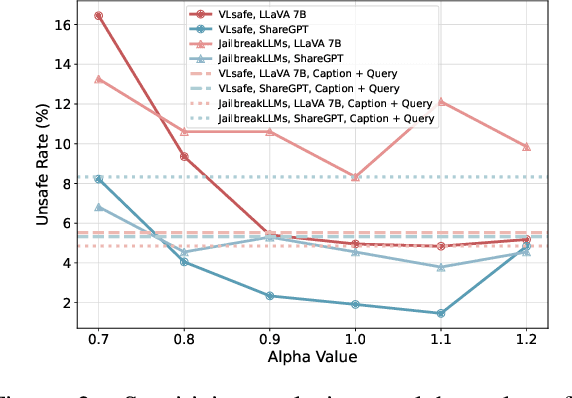

The safety alignment ability of Vision-Language Models (VLMs) is prone to be degraded by the integration of the vision module compared to its LLM backbone. We investigate this phenomenon, dubbed as ''safety alignment degradation'' in this paper, and show that the challenge arises from the representation gap that emerges when introducing vision modality to VLMs. In particular, we show that the representations of multi-modal inputs shift away from that of text-only inputs which represent the distribution that the LLM backbone is optimized for. At the same time, the safety alignment capabilities, initially developed within the textual embedding space, do not successfully transfer to this new multi-modal representation space. To reduce safety alignment degradation, we introduce Cross-Modality Representation Manipulation (CMRM), an inference time representation intervention method for recovering the safety alignment ability that is inherent in the LLM backbone of VLMs, while simultaneously preserving the functional capabilities of VLMs. The empirical results show that our framework significantly recovers the alignment ability that is inherited from the LLM backbone with minimal impact on the fluency and linguistic capabilities of pre-trained VLMs even without additional training. Specifically, the unsafe rate of LLaVA-7B on multi-modal input can be reduced from 61.53% to as low as 3.15% with only inference-time intervention. WARNING: This paper contains examples of toxic or harmful language.
General Purpose Verification for Chain of Thought Prompting
Apr 30, 2024



Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
Characterizing and Measuring Linguistic Dataset Drift
May 26, 2023
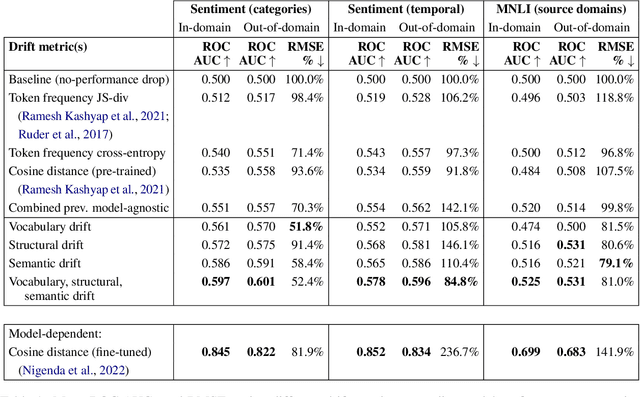

NLP models often degrade in performance when real world data distributions differ markedly from training data. However, existing dataset drift metrics in NLP have generally not considered specific dimensions of linguistic drift that affect model performance, and they have not been validated in their ability to predict model performance at the individual example level, where such metrics are often used in practice. In this paper, we propose three dimensions of linguistic dataset drift: vocabulary, structural, and semantic drift. These dimensions correspond to content word frequency divergences, syntactic divergences, and meaning changes not captured by word frequencies (e.g. lexical semantic change). We propose interpretable metrics for all three drift dimensions, and we modify past performance prediction methods to predict model performance at both the example and dataset level for English sentiment classification and natural language inference. We find that our drift metrics are more effective than previous metrics at predicting out-of-domain model accuracies (mean 16.8% root mean square error decrease), particularly when compared to popular fine-tuned embedding distances (mean 47.7% error decrease). Fine-tuned embedding distances are much more effective at ranking individual examples by expected performance, but decomposing into vocabulary, structural, and semantic drift produces the best example rankings of all considered model-agnostic drift metrics (mean 6.7% ROC AUC increase).
Taxonomy Expansion for Named Entity Recognition
May 22, 2023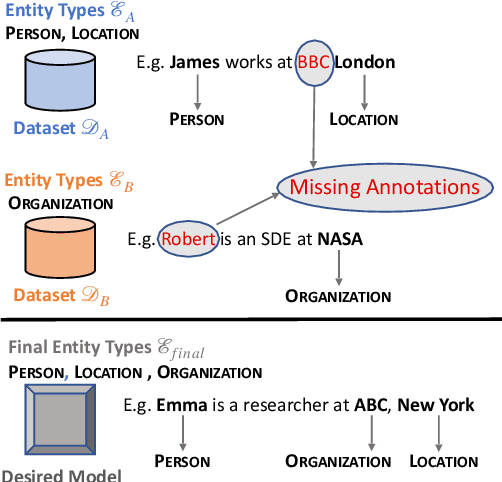
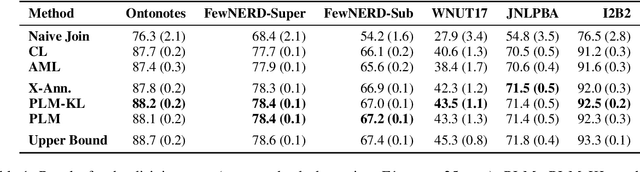
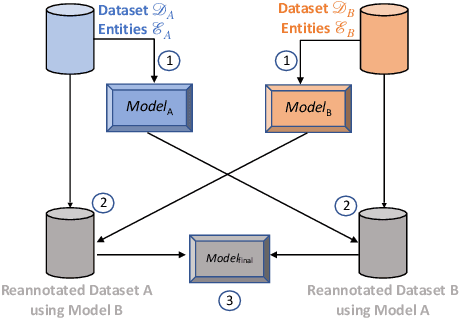
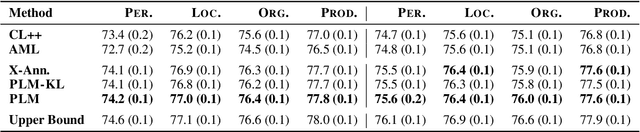
Training a Named Entity Recognition (NER) model often involves fixing a taxonomy of entity types. However, requirements evolve and we might need the NER model to recognize additional entity types. A simple approach is to re-annotate entire dataset with both existing and additional entity types and then train the model on the re-annotated dataset. However, this is an extremely laborious task. To remedy this, we propose a novel approach called Partial Label Model (PLM) that uses only partially annotated datasets. We experiment with 6 diverse datasets and show that PLM consistently performs better than most other approaches (0.5 - 2.5 F1), including in novel settings for taxonomy expansion not considered in prior work. The gap between PLM and all other approaches is especially large in settings where there is limited data available for the additional entity types (as much as 11 F1), thus suggesting a more cost effective approaches to taxonomy expansion.
A Weak Supervision Approach for Few-Shot Aspect Based Sentiment
May 19, 2023
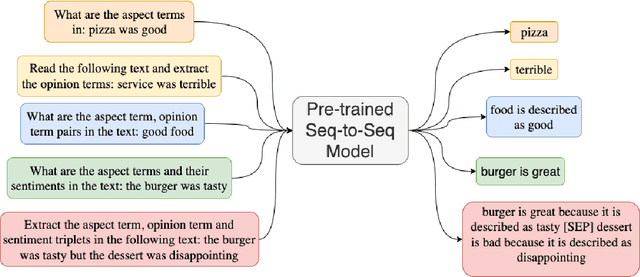
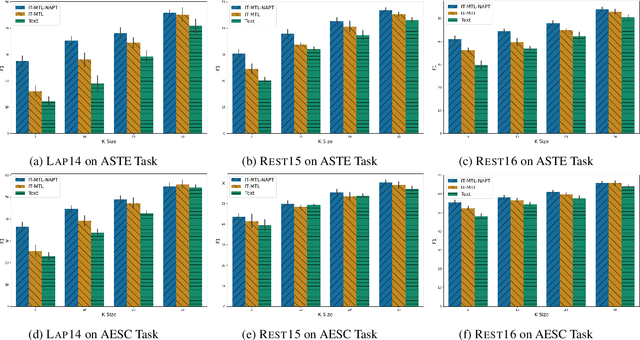

We explore how weak supervision on abundant unlabeled data can be leveraged to improve few-shot performance in aspect-based sentiment analysis (ABSA) tasks. We propose a pipeline approach to construct a noisy ABSA dataset, and we use it to adapt a pre-trained sequence-to-sequence model to the ABSA tasks. We test the resulting model on three widely used ABSA datasets, before and after fine-tuning. Our proposed method preserves the full fine-tuning performance while showing significant improvements (15.84% absolute F1) in the few-shot learning scenario for the harder tasks. In zero-shot (i.e., without fine-tuning), our method outperforms the previous state of the art on the aspect extraction sentiment classification (AESC) task and is, additionally, capable of performing the harder aspect sentiment triplet extraction (ASTE) task.
Comparing Biases and the Impact of Multilingual Training across Multiple Languages
May 18, 2023



Studies in bias and fairness in natural language processing have primarily examined social biases within a single language and/or across few attributes (e.g. gender, race). However, biases can manifest differently across various languages for individual attributes. As a result, it is critical to examine biases within each language and attribute. Of equal importance is to study how these biases compare across languages and how the biases are affected when training a model on multilingual data versus monolingual data. We present a bias analysis across Italian, Chinese, English, Hebrew, and Spanish on the downstream sentiment analysis task to observe whether specific demographics are viewed more positively. We study bias similarities and differences across these languages and investigate the impact of multilingual vs. monolingual training data. We adapt existing sentiment bias templates in English to Italian, Chinese, Hebrew, and Spanish for four attributes: race, religion, nationality, and gender. Our results reveal similarities in bias expression such as favoritism of groups that are dominant in each language's culture (e.g. majority religions and nationalities). Additionally, we find an increased variation in predictions across protected groups, indicating bias amplification, after multilingual finetuning in comparison to multilingual pretraining.
Dynamic Benchmarking of Masked Language Models on Temporal Concept Drift with Multiple Views
Feb 23, 2023



Temporal concept drift refers to the problem of data changing over time. In NLP, that would entail that language (e.g. new expressions, meaning shifts) and factual knowledge (e.g. new concepts, updated facts) evolve over time. Focusing on the latter, we benchmark $11$ pretrained masked language models (MLMs) on a series of tests designed to evaluate the effect of temporal concept drift, as it is crucial that widely used language models remain up-to-date with the ever-evolving factual updates of the real world. Specifically, we provide a holistic framework that (1) dynamically creates temporal test sets of any time granularity (e.g. month, quarter, year) of factual data from Wikidata, (2) constructs fine-grained splits of tests (e.g. updated, new, unchanged facts) to ensure comprehensive analysis, and (3) evaluates MLMs in three distinct ways (single-token probing, multi-token generation, MLM scoring). In contrast to prior work, our framework aims to unveil how robust an MLM is over time and thus to provide a signal in case it has become outdated, by leveraging multiple views of evaluation.