 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Classification and Calibration Performance in Decision-Making LLMs via Calibration Aware Reinforcement Learning
Jan 19, 2026Large language models (LLMs) are increasingly deployed in decision-making tasks, where not only accuracy but also reliable confidence estimates are essential. Well-calibrated confidence enables downstream systems to decide when to trust a model and when to defer to fallback mechanisms. In this work, we conduct a systematic study of calibration in two widely used fine-tuning paradigms: supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). We show that while RLVR improves task performance, it produces extremely overconfident models, whereas SFT yields substantially better calibration, even under distribution shift, though with smaller performance gains. Through targeted experiments, we diagnose RLVR's failure, showing that decision tokens act as extraction steps of the decision in reasoning traces and do not carry confidence information, which prevents reinforcement learning from surfacing calibrated alternatives. Based on this insight, we propose a calibration-aware reinforcement learning formulation that directly adjusts decision-token probabilities. Our method preserves RLVR's accuracy level while mitigating overconfidence, reducing ECE scores up to 9 points.
Detecting Training Data of Large Language Models via Expectation Maximization
Oct 10, 2024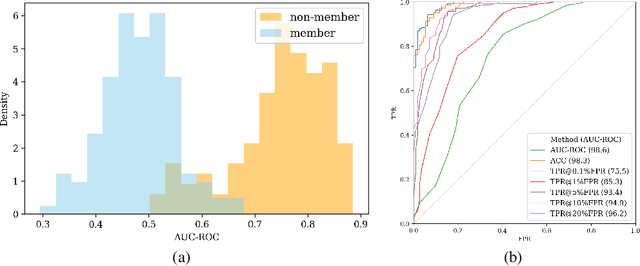
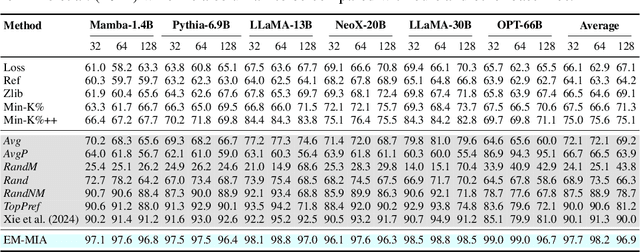

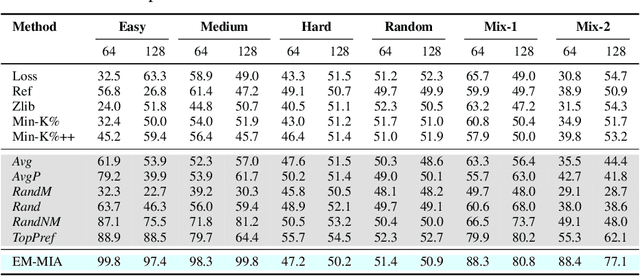
The widespread deployment of large language models (LLMs) has led to impressive advancements, yet information about their training data, a critical factor in their performance, remains undisclosed. Membership inference attacks (MIAs) aim to determine whether a specific instance was part of a target model's training data. MIAs can offer insights into LLM outputs and help detect and address concerns such as data contamination and compliance with privacy and copyright standards. However, applying MIAs to LLMs presents unique challenges due to the massive scale of pre-training data and the ambiguous nature of membership. Additionally, creating appropriate benchmarks to evaluate MIA methods is not straightforward, as training and test data distributions are often unknown. In this paper, we introduce EM-MIA, a novel MIA method for LLMs that iteratively refines membership scores and prefix scores via an expectation-maximization algorithm, leveraging the duality that the estimates of these scores can be improved by each other. Membership scores and prefix scores assess how each instance is likely to be a member and discriminative as a prefix, respectively. Our method achieves state-of-the-art results on the WikiMIA dataset. To further evaluate EM-MIA, we present OLMoMIA, a benchmark built from OLMo resources, which allows us to control the difficulty of MIA tasks with varying degrees of overlap between training and test data distributions. We believe that EM-MIA serves as a robust MIA method for LLMs and that OLMoMIA provides a valuable resource for comprehensively evaluating MIA approaches, thereby driving future research in this critical area.
General Purpose Verification for Chain of Thought Prompting
Apr 30, 2024



Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
Few-Shot Data-to-Text Generation via Unified Representation and Multi-Source Learning
Aug 10, 2023We present a novel approach for structured data-to-text generation that addresses the limitations of existing methods that primarily focus on specific types of structured data. Our proposed method aims to improve performance in multi-task training, zero-shot and few-shot scenarios by providing a unified representation that can handle various forms of structured data such as tables, knowledge graph triples, and meaning representations. We demonstrate that our proposed approach can effectively adapt to new structured forms, and can improve performance in comparison to current methods. For example, our method resulted in a 66% improvement in zero-shot BLEU scores when transferring models trained on table inputs to a knowledge graph dataset. Our proposed method is an important step towards a more general data-to-text generation framework.
EvEntS ReaLM: Event Reasoning of Entity States via Language Models
Nov 10, 2022This paper investigates models of event implications. Specifically, how well models predict entity state-changes, by targeting their understanding of physical attributes. Nominally, Large Language models (LLM) have been exposed to procedural knowledge about how objects interact, yet our benchmarking shows they fail to reason about the world. Conversely, we also demonstrate that existing approaches often misrepresent the surprising abilities of LLMs via improper task encodings and that proper model prompting can dramatically improve performance of reported baseline results across multiple tasks. In particular, our results indicate that our prompting technique is especially useful for unseen attributes (out-of-domain) or when only limited data is available.
Event-Related Bias Removal for Real-time Disaster Events
Nov 02, 2020


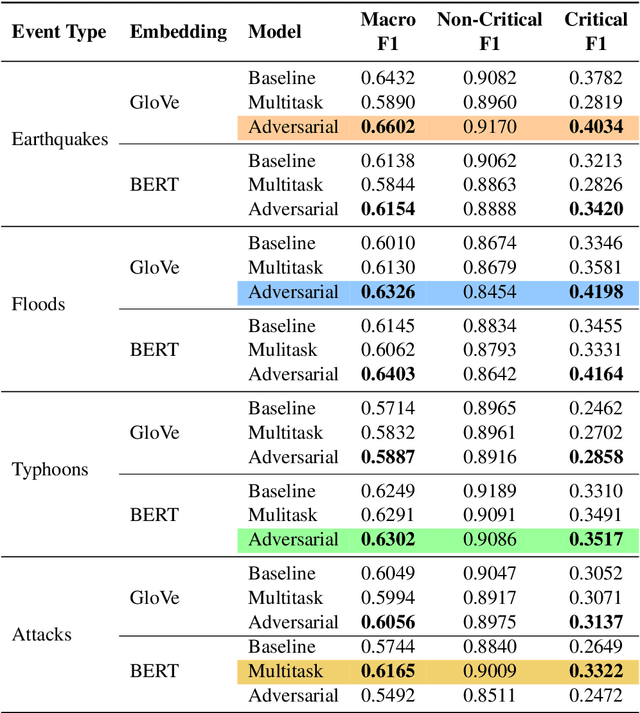
Social media has become an important tool to share information about crisis events such as natural disasters and mass attacks. Detecting actionable posts that contain useful information requires rapid analysis of huge volume of data in real-time. This poses a complex problem due to the large amount of posts that do not contain any actionable information. Furthermore, the classification of information in real-time systems requires training on out-of-domain data, as we do not have any data from a new emerging crisis. Prior work focuses on models pre-trained on similar event types. However, those models capture unnecessary event-specific biases, like the location of the event, which affect the generalizability and performance of the classifiers on new unseen data from an emerging new event. In our work, we train an adversarial neural model to remove latent event-specific biases and improve the performance on tweet importance classification.
Definition Frames: Using Definitions for Hybrid Concept Representations
Sep 10, 2019



Concept representations is a particularly active area in NLP. Although recent advances in distributional semantics have shown tremendous improvements in performance, they still lack semantic interpretability. In this paper, we introduce a novel hybrid representation called Definition Frames, which is extracted from definitions under the formulation of domain-transfer Relation Extraction. Definition Frames are easily reformulated to a matrix representation where each row is semantically meaningful. This results in a fluid representation, where we can prune dimension(s) according to the type of information we want to retain for any specific task. Our results show that Definition Frames (1) maintain the significant semantic information of the original definition (human evaluation) and (2) have competitive performance with other distributional semantic approaches on word similarity tasks. Furthermore, our experiments show substantial improvements over word-embeddings when fine-tuned to a task even using only a linear transform.
Linguistic Markers of Influence in Informal Interactions
Jul 14, 2017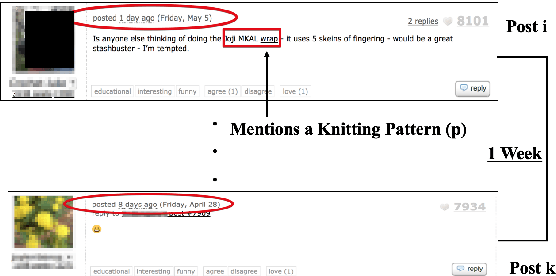
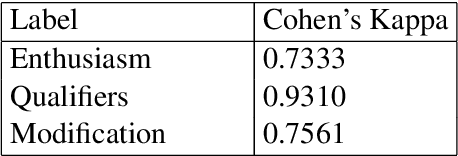
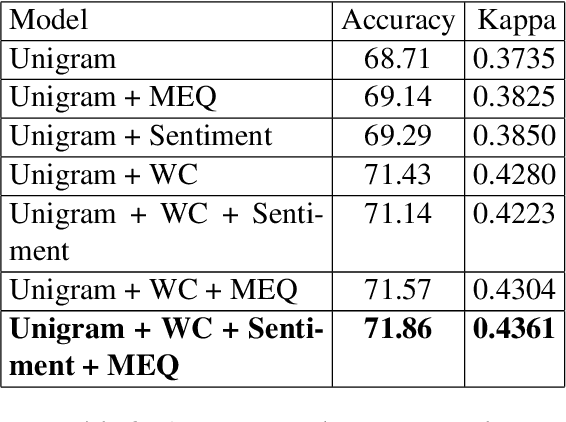
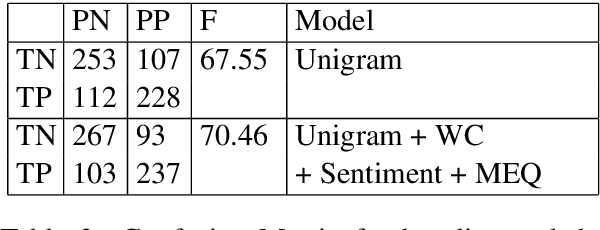
There has been a long standing interest in understanding `Social Influence' both in Social Sciences and in Computational Linguistics. In this paper, we present a novel approach to study and measure interpersonal influence in daily interactions. Motivated by the basic principles of influence, we attempt to identify indicative linguistic features of the posts in an online knitting community. We present the scheme used to operationalize and label the posts with indicator features. Experiments with the identified features show an improvement in the classification accuracy of influence by 3.15%. Our results illustrate the important correlation between the characteristics of the language and its potential to influence others.