 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Training Data of Large Language Models via Expectation Maximization
Paper and Code
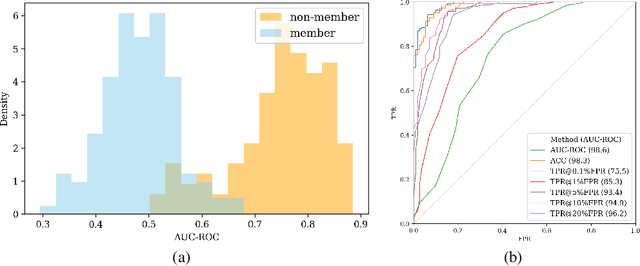
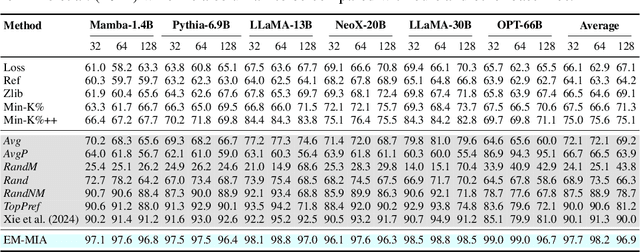

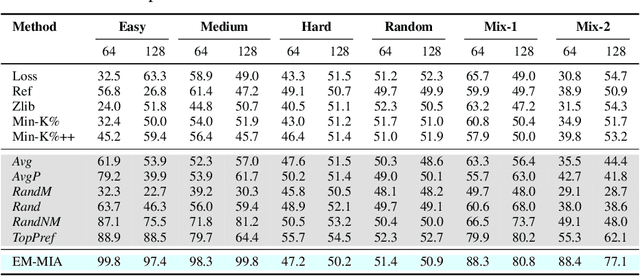
The widespread deployment of large language models (LLMs) has led to impressive advancements, yet information about their training data, a critical factor in their performance, remains undisclosed. Membership inference attacks (MIAs) aim to determine whether a specific instance was part of a target model's training data. MIAs can offer insights into LLM outputs and help detect and address concerns such as data contamination and compliance with privacy and copyright standards. However, applying MIAs to LLMs presents unique challenges due to the massive scale of pre-training data and the ambiguous nature of membership. Additionally, creating appropriate benchmarks to evaluate MIA methods is not straightforward, as training and test data distributions are often unknown. In this paper, we introduce EM-MIA, a novel MIA method for LLMs that iteratively refines membership scores and prefix scores via an expectation-maximization algorithm, leveraging the duality that the estimates of these scores can be improved by each other. Membership scores and prefix scores assess how each instance is likely to be a member and discriminative as a prefix, respectively. Our method achieves state-of-the-art results on the WikiMIA dataset. To further evaluate EM-MIA, we present OLMoMIA, a benchmark built from OLMo resources, which allows us to control the difficulty of MIA tasks with varying degrees of overlap between training and test data distributions. We believe that EM-MIA serves as a robust MIA method for LLMs and that OLMoMIA provides a valuable resource for comprehensively evaluating MIA approaches, thereby driving future research in this critical area.