 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveying the Effects of Quality, Diversity, and Complexity in Synthetic Data From Large Language Models
Dec 04, 2024



Synthetic data generation with Large Language Models is a promising paradigm for augmenting natural data over a nearly infinite range of tasks. Given this variety, direct comparisons among synthetic data generation algorithms are scarce, making it difficult to understand where improvement comes from and what bottlenecks exist. We propose to evaluate algorithms via the makeup of synthetic data generated by each algorithm in terms of data quality, diversity, and complexity. We choose these three characteristics for their significance in open-ended processes and the impact each has on the capabilities of downstream models. We find quality to be essential for in-distribution model generalization, diversity to be essential for out-of-distribution generalization, and complexity to be beneficial for both. Further, we emphasize the existence of Quality-Diversity trade-offs in training data and the downstream effects on model performance. We then examine the effect of various components in the synthetic data pipeline on each data characteristic. This examination allows us to taxonomize and compare synthetic data generation algorithms through the components they utilize and the resulting effects on data QDC composition. This analysis extends into a discussion on the importance of balancing QDC in synthetic data for efficient reinforcement learning and self-improvement algorithms. Analogous to the QD trade-offs in training data, often there exist trade-offs between model output quality and output diversity which impact the composition of synthetic data. We observe that many models are currently evaluated and optimized only for output quality, thereby limiting output diversity and the potential for self-improvement. We argue that balancing these trade-offs is essential to the development of future self-improvement algorithms and highlight a number of works making progress in this direction.
Learning to Play 7 Wonders Duel Without Human Supervision
Jun 02, 2024

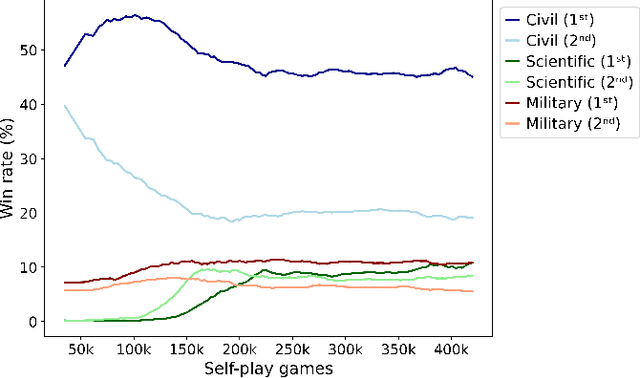
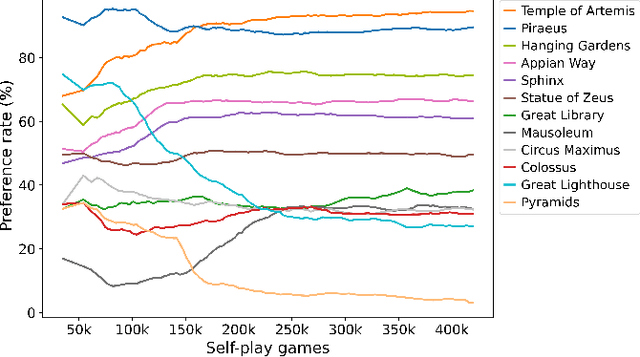
This paper introduces ZeusAI, an artificial intelligence system developed to play the board game 7 Wonders Duel. Inspired by the AlphaZero reinforcement learning algorithm, ZeusAI relies on a combination of Monte Carlo Tree Search and a Transformer Neural Network to learn the game without human supervision. ZeusAI competes at the level of top human players, develops both known and novel strategies, and allows us to test rule variants to improve the game's balance. This work demonstrates how AI can help in understanding and enhancing board games.
General Purpose Verification for Chain of Thought Prompting
Apr 30, 2024



Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
Fewer Truncations Improve Language Modeling
Apr 16, 2024



In large language model training, input documents are typically concatenated together and then split into sequences of equal length to avoid padding tokens. Despite its efficiency, the concatenation approach compromises data integrity -- it inevitably breaks many documents into incomplete pieces, leading to excessive truncations that hinder the model from learning to compose logically coherent and factually consistent content that is grounded on the complete context. To address the issue, we propose Best-fit Packing, a scalable and efficient method that packs documents into training sequences through length-aware combinatorial optimization. Our method completely eliminates unnecessary truncations while retaining the same training efficiency as concatenation. Empirical results from both text and code pre-training show that our method achieves superior performance (e.g., relatively +4.7% on reading comprehension; +16.8% in context following; and +9.2% on program synthesis), and reduces closed-domain hallucination effectively by up to 58.3%.
Taxonomy Expansion for Named Entity Recognition
May 22, 2023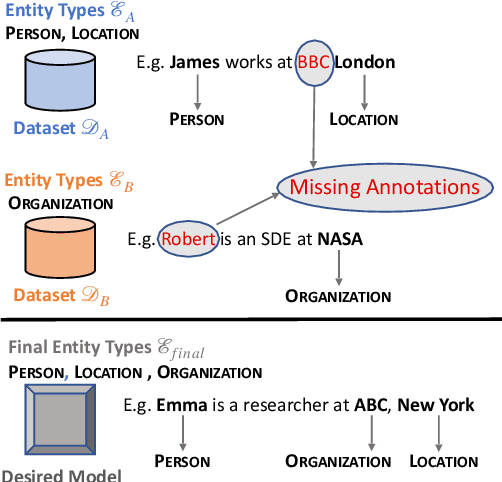
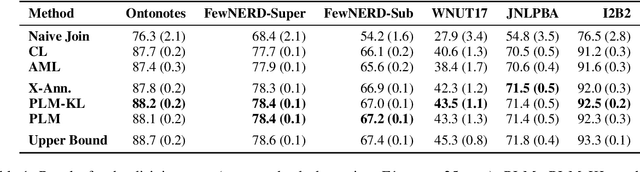
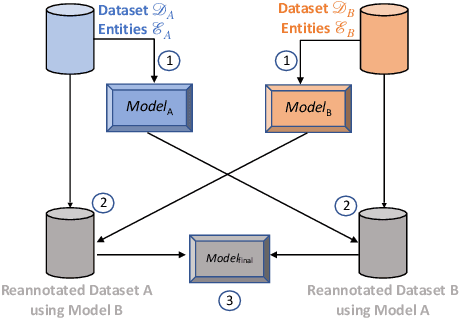
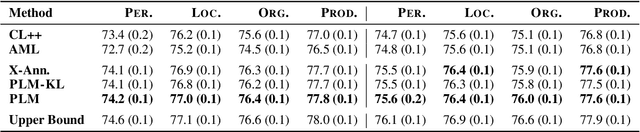
Training a Named Entity Recognition (NER) model often involves fixing a taxonomy of entity types. However, requirements evolve and we might need the NER model to recognize additional entity types. A simple approach is to re-annotate entire dataset with both existing and additional entity types and then train the model on the re-annotated dataset. However, this is an extremely laborious task. To remedy this, we propose a novel approach called Partial Label Model (PLM) that uses only partially annotated datasets. We experiment with 6 diverse datasets and show that PLM consistently performs better than most other approaches (0.5 - 2.5 F1), including in novel settings for taxonomy expansion not considered in prior work. The gap between PLM and all other approaches is especially large in settings where there is limited data available for the additional entity types (as much as 11 F1), thus suggesting a more cost effective approaches to taxonomy expansion.
A Weak Supervision Approach for Few-Shot Aspect Based Sentiment
May 19, 2023
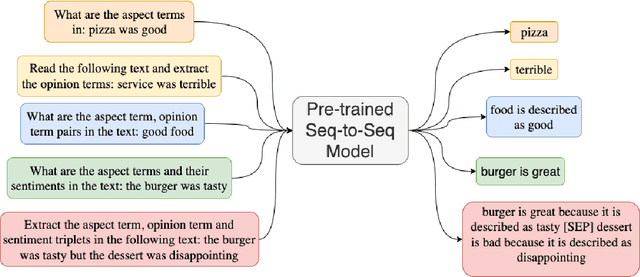
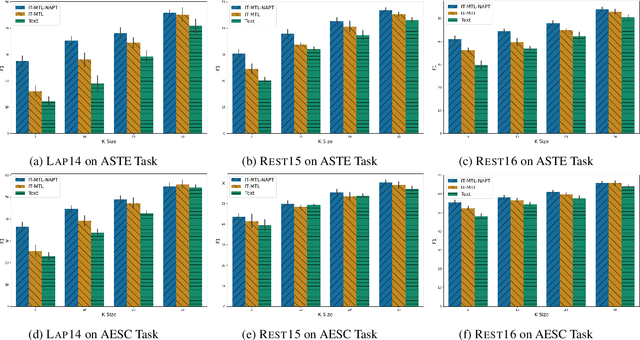

We explore how weak supervision on abundant unlabeled data can be leveraged to improve few-shot performance in aspect-based sentiment analysis (ABSA) tasks. We propose a pipeline approach to construct a noisy ABSA dataset, and we use it to adapt a pre-trained sequence-to-sequence model to the ABSA tasks. We test the resulting model on three widely used ABSA datasets, before and after fine-tuning. Our proposed method preserves the full fine-tuning performance while showing significant improvements (15.84% absolute F1) in the few-shot learning scenario for the harder tasks. In zero-shot (i.e., without fine-tuning), our method outperforms the previous state of the art on the aspect extraction sentiment classification (AESC) task and is, additionally, capable of performing the harder aspect sentiment triplet extraction (ASTE) task.
À-la-carte Prompt Tuning : Combining Distinct Data Via Composable Prompting
Feb 15, 2023We introduce \`A-la-carte Prompt Tuning (APT), a transformer-based scheme to tune prompts on distinct data so that they can be arbitrarily composed at inference time. The individual prompts can be trained in isolation, possibly on different devices, at different times, and on different distributions or domains. Furthermore each prompt only contains information about the subset of data it was exposed to during training. During inference, models can be assembled based on arbitrary selections of data sources, which we call "\`a-la-carte learning". \`A-la-carte learning enables constructing bespoke models specific to each user's individual access rights and preferences. We can add or remove information from the model by simply adding or removing the corresponding prompts without retraining from scratch. We demonstrate that \`a-la-carte built models achieve accuracy within $5\%$ of models trained on the union of the respective sources, with comparable cost in terms of training and inference time. For the continual learning benchmarks Split CIFAR-100 and CORe50, we achieve state-of-the-art performance.
DIVA: Dataset Derivative of a Learning Task
Nov 18, 2021
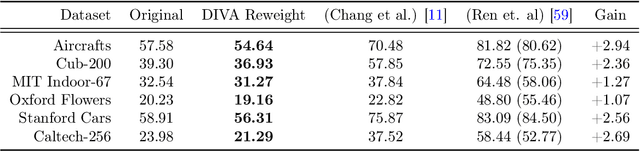

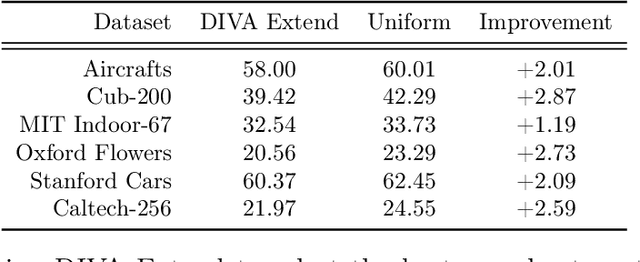
We present a method to compute the derivative of a learning task with respect to a dataset. A learning task is a function from a training set to the validation error, which can be represented by a trained deep neural network (DNN). The "dataset derivative" is a linear operator, computed around the trained model, that informs how perturbations of the weight of each training sample affect the validation error, usually computed on a separate validation dataset. Our method, DIVA (Differentiable Validation) hinges on a closed-form differentiable expression of the leave-one-out cross-validation error around a pre-trained DNN. Such expression constitutes the dataset derivative. DIVA could be used for dataset auto-curation, for example removing samples with faulty annotations, augmenting a dataset with additional relevant samples, or rebalancing. More generally, DIVA can be used to optimize the dataset, along with the parameters of the model, as part of the training process without the need for a separate validation dataset, unlike bi-level optimization methods customary in AutoML. To illustrate the flexibility of DIVA, we report experiments on sample auto-curation tasks such as outlier rejection, dataset extension, and automatic aggregation of multi-modal data.
Structured Prediction as Translation between Augmented Natural Languages
Jan 28, 2021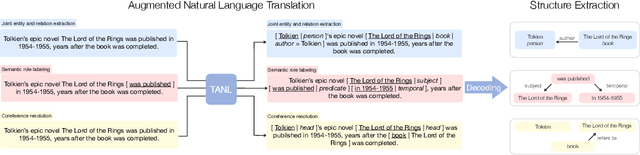
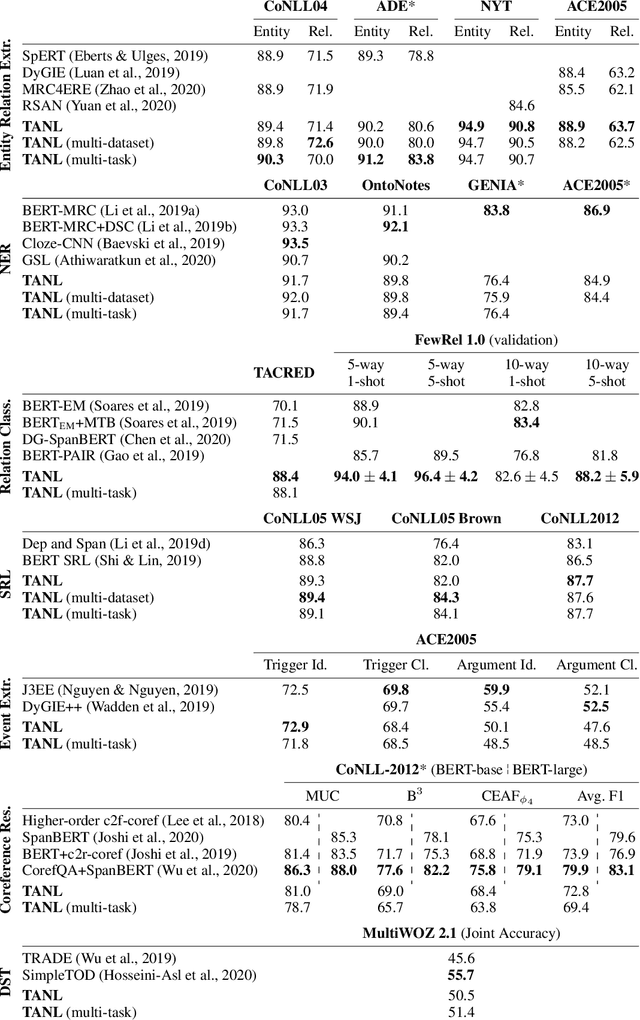
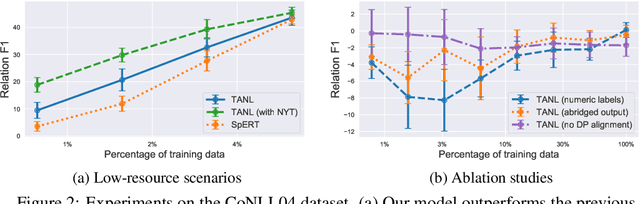
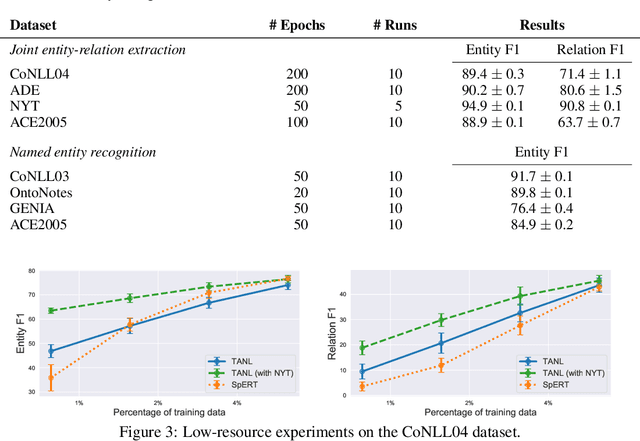
We propose a new framework, Translation between Augmented Natural Languages (TANL), to solve many structured prediction language tasks including joint entity and relation extraction, nested named entity recognition, relation classification, semantic role labeling, event extraction, coreference resolution, and dialogue state tracking. Instead of tackling the problem by training task-specific discriminative classifiers, we frame it as a translation task between augmented natural languages, from which the task-relevant information can be easily extracted. Our approach can match or outperform task-specific models on all tasks, and in particular, achieves new state-of-the-art results on joint entity and relation extraction (CoNLL04, ADE, NYT, and ACE2005 datasets), relation classification (FewRel and TACRED), and semantic role labeling (CoNLL-2005 and CoNLL-2012). We accomplish this while using the same architecture and hyperparameters for all tasks and even when training a single model to solve all tasks at the same time (multi-task learning). Finally, we show that our framework can also significantly improve the performance in a low-resource regime, thanks to better use of label semantics.
Estimating informativeness of samples with Smooth Unique Information
Jan 17, 2021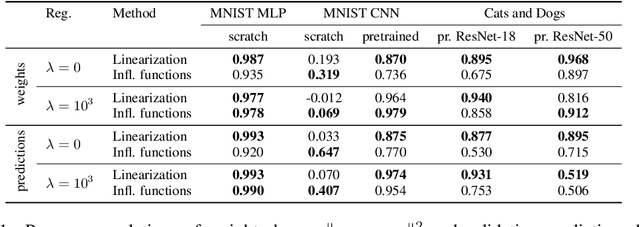

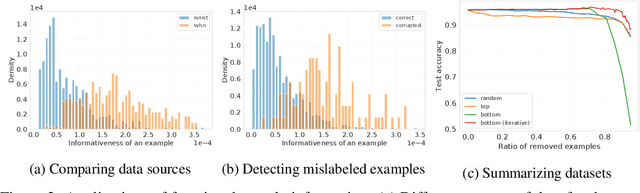
We define a notion of information that an individual sample provides to the training of a neural network, and we specialize it to measure both how much a sample informs the final weights and how much it informs the function computed by the weights. Though related, we show that these quantities have a qualitatively different behavior. We give efficient approximations of these quantities using a linearized network and demonstrate empirically that the approximation is accurate for real-world architectures, such as pre-trained ResNets. We apply these measures to several problems, such as dataset summarization, analysis of under-sampled classes, comparison of informativeness of different data sources, and detection of adversarial and corrupted examples. Our work generalizes existing frameworks but enjoys better computational properties for heavily over-parametrized models, which makes it possible to apply it to real-world networks.