 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Scaling of Diffusion Transformers for Text-to-Image Generation
Dec 16, 2024



We empirically study the scaling properties of various Diffusion Transformers (DiTs) for text-to-image generation by performing extensive and rigorous ablations, including training scaled DiTs ranging from 0.3B upto 8B parameters on datasets up to 600M images. We find that U-ViT, a pure self-attention based DiT model provides a simpler design and scales more effectively in comparison with cross-attention based DiT variants, which allows straightforward expansion for extra conditions and other modalities. We identify a 2.3B U-ViT model can get better performance than SDXL UNet and other DiT variants in controlled setting. On the data scaling side, we investigate how increasing dataset size and enhanced long caption improve the text-image alignment performance and the learning efficiency.
On the Scalability of Diffusion-based Text-to-Image Generation
Apr 03, 2024Scaling up model and data size has been quite successful for the evolution of LLMs. However, the scaling law for the diffusion based text-to-image (T2I) models is not fully explored. It is also unclear how to efficiently scale the model for better performance at reduced cost. The different training settings and expensive training cost make a fair model comparison extremely difficult. In this work, we empirically study the scaling properties of diffusion based T2I models by performing extensive and rigours ablations on scaling both denoising backbones and training set, including training scaled UNet and Transformer variants ranging from 0.4B to 4B parameters on datasets upto 600M images. For model scaling, we find the location and amount of cross attention distinguishes the performance of existing UNet designs. And increasing the transformer blocks is more parameter-efficient for improving text-image alignment than increasing channel numbers. We then identify an efficient UNet variant, which is 45% smaller and 28% faster than SDXL's UNet. On the data scaling side, we show the quality and diversity of the training set matters more than simply dataset size. Increasing caption density and diversity improves text-image alignment performance and the learning efficiency. Finally, we provide scaling functions to predict the text-image alignment performance as functions of the scale of model size, compute and dataset size.
Revisiting Contrastive Learning for Few-Shot Classification
Jan 26, 2021
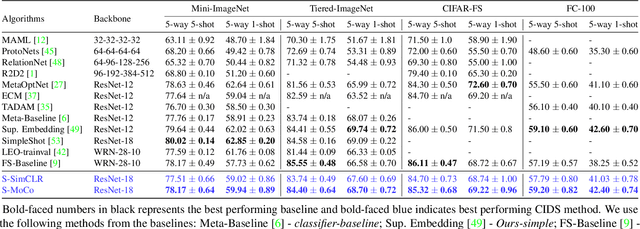
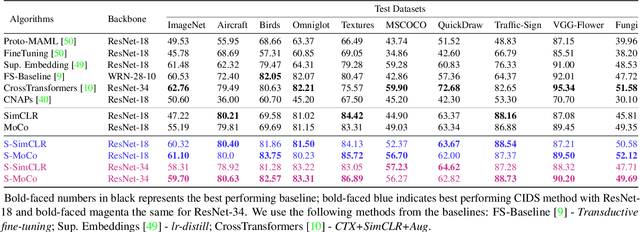
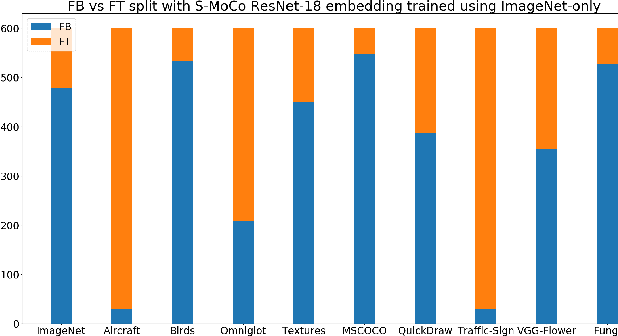
Instance discrimination based contrastive learning has emerged as a leading approach for self-supervised learning of visual representations. Yet, its generalization to novel tasks remains elusive when compared to representations learned with supervision, especially in the few-shot setting. We demonstrate how one can incorporate supervision in the instance discrimination based contrastive self-supervised learning framework to learn representations that generalize better to novel tasks. We call our approach CIDS (Contrastive Instance Discrimination with Supervision). CIDS performs favorably compared to existing algorithms on popular few-shot benchmarks like Mini-ImageNet or Tiered-ImageNet. We also propose a novel model selection algorithm that can be used in conjunction with a universal embedding trained using CIDS to outperform state-of-the-art algorithms on the challenging Meta-Dataset benchmark.
Estimating informativeness of samples with Smooth Unique Information
Jan 17, 2021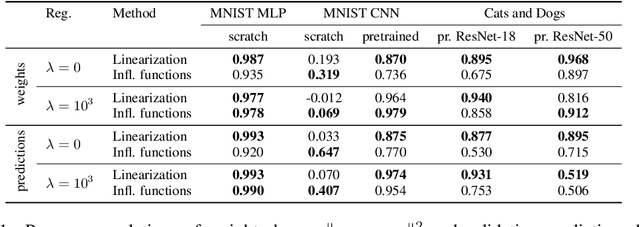

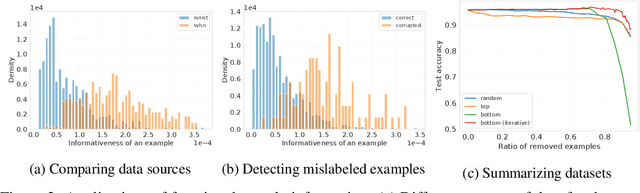
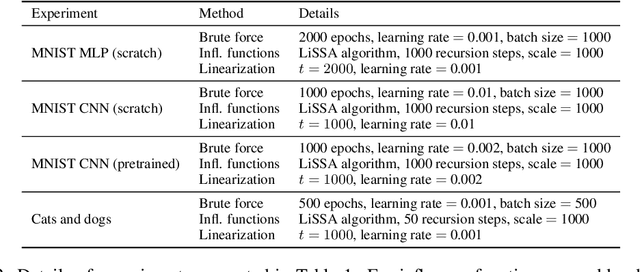
We define a notion of information that an individual sample provides to the training of a neural network, and we specialize it to measure both how much a sample informs the final weights and how much it informs the function computed by the weights. Though related, we show that these quantities have a qualitatively different behavior. We give efficient approximations of these quantities using a linearized network and demonstrate empirically that the approximation is accurate for real-world architectures, such as pre-trained ResNets. We apply these measures to several problems, such as dataset summarization, analysis of under-sampled classes, comparison of informativeness of different data sources, and detection of adversarial and corrupted examples. Our work generalizes existing frameworks but enjoys better computational properties for heavily over-parametrized models, which makes it possible to apply it to real-world networks.
Incremental Learning for Metric-Based Meta-Learners
Feb 11, 2020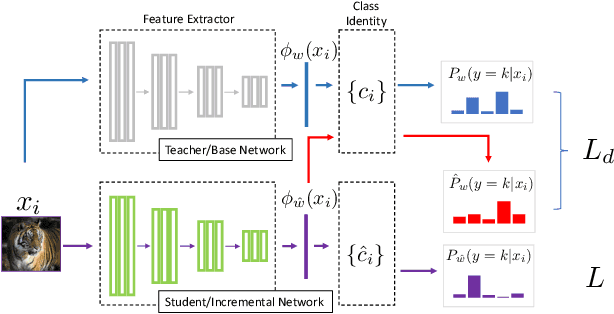
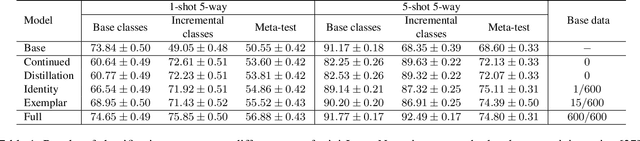
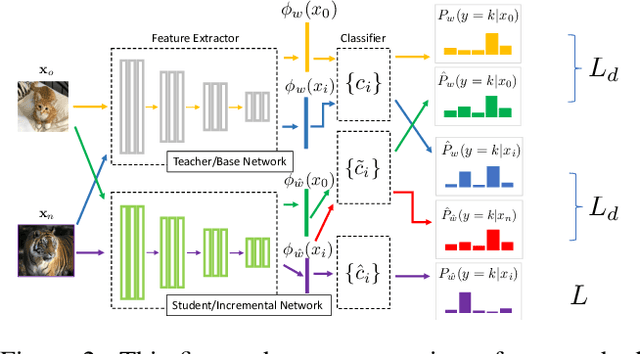

Majority of the modern meta-learning methods for few-shot classification tasks operate in two phases: a meta-training phase where the meta-learner learns a generic representation by solving multiple few-shot tasks sampled from a large dataset and a testing phase, where the meta-learner leverages its learnt internal representation for a specific few-shot task involving classes which were not seen during the meta-training phase. To the best of our knowledge, all such meta-learning methods use a single base dataset for meta-training to sample tasks from and do not adapt the algorithm after meta-training. This strategy may not scale to real-world use-cases where the meta-learner does not potentially have access to the full meta-training dataset from the very beginning and we need to update the meta-learner in an incremental fashion when additional training data becomes available. Through our experimental setup, we develop a notion of incremental learning during the meta-training phase of meta-learning and propose a method which can be used with multiple existing metric-based meta-learning algorithms. Experimental results on benchmark dataset show that our approach performs favorably at test time as compared to training a model with the full meta-training set and incurs negligible amount of catastrophic forgetting
FineText: Text Classification via Attention-based Language Model Fine-tuning
Oct 25, 2019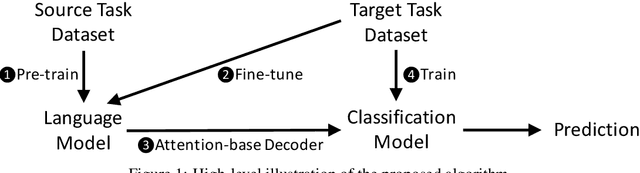
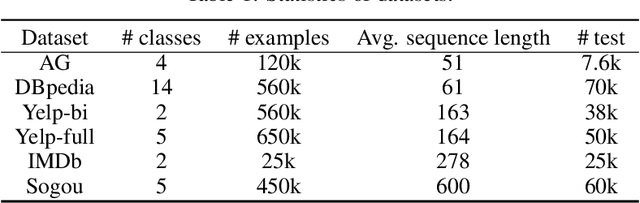

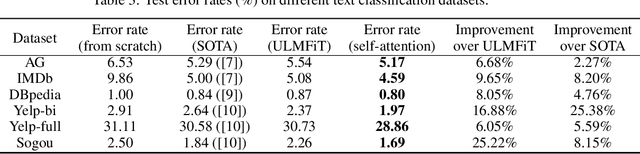
Training deep neural networks from scratch on natural language processing (NLP) tasks requires significant amount of manually labeled text corpus and substantial time to converge, which usually cannot be satisfied by the customers. In this paper, we aim to develop an effective transfer learning algorithm by fine-tuning a pre-trained language model. The goal is to provide expressive and convenient-to-use feature extractors for downstream NLP tasks, and achieve improvement in terms of accuracy, data efficiency, and generalization to new domains. Therefore, we propose an attention-based fine-tuning algorithm that automatically selects relevant contextualized features from the pre-trained language model and uses those features on downstream text classification tasks. We test our methods on six widely-used benchmarking datasets, and achieve new state-of-the-art performance on all of them. Moreover, we then introduce an alternative multi-task learning approach, which is an end-to-end algorithm given the pre-trained model. By doing multi-task learning, one can largely reduce the total training time by trading off some classification accuracy.
Scheduling the Learning Rate via Hypergradients: New Insights and a New Algorithm
Oct 18, 2019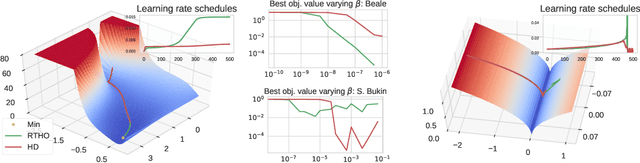
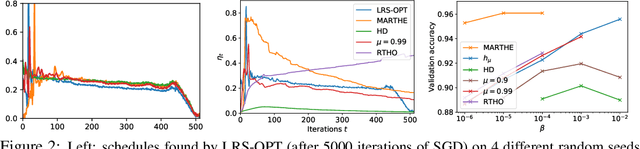
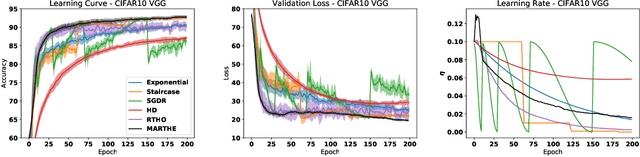
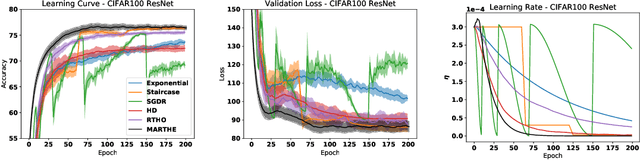
We study the problem of fitting task-specific learning rate schedules from the perspective of hyperparameter optimization. This allows us to explicitly search for schedules that achieve good generalization. We describe the structure of the gradient of a validation error w.r.t. the learning rate, the hypergradient, and based on this we introduce a novel online algorithm. Our method adaptively interpolates between the recently proposed techniques of Franceschi et al. (2017) and Baydin et al. (2017), featuring increased stability and faster convergence. We show empirically that the proposed method compares favourably with baselines and related methods in terms of final test accuracy.
$d$-SNE: Domain Adaptation using Stochastic Neighborhood Embedding
May 29, 2019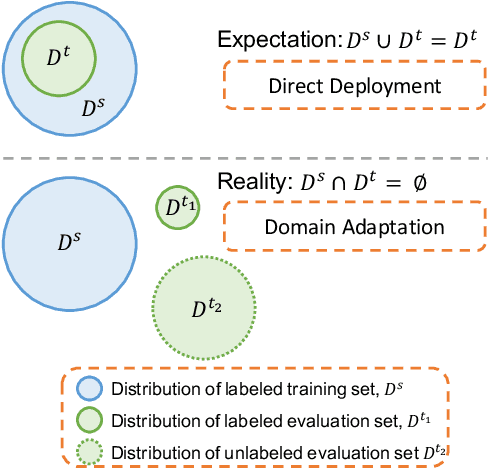
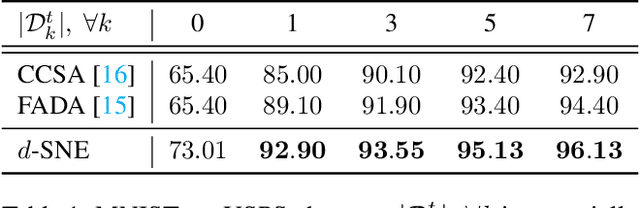
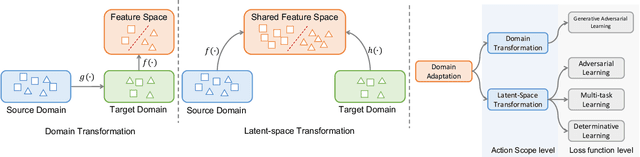
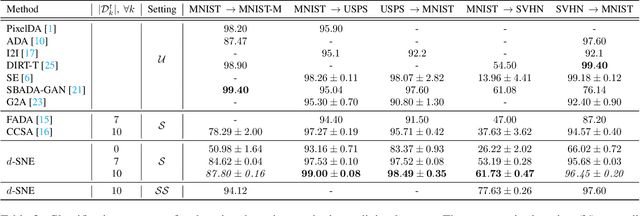
Deep neural networks often require copious amount of labeled-data to train their scads of parameters. Training larger and deeper networks is hard without appropriate regularization, particularly while using a small dataset. Laterally, collecting well-annotated data is expensive, time-consuming and often infeasible. A popular way to regularize these networks is to simply train the network with more data from an alternate representative dataset. This can lead to adverse effects if the statistics of the representative dataset are dissimilar to our target. This predicament is due to the problem of domain shift. Data from a shifted domain might not produce bespoke features when a feature extractor from the representative domain is used. In this paper, we propose a new technique ($d$-SNE) of domain adaptation that cleverly uses stochastic neighborhood embedding techniques and a novel modified-Hausdorff distance. The proposed technique is learnable end-to-end and is therefore, ideally suited to train neural networks. Extensive experiments demonstrate that $d$-SNE outperforms the current states-of-the-art and is robust to the variances in different datasets, even in the one-shot and semi-supervised learning settings. $d$-SNE also demonstrates the ability to generalize to multiple domains concurrently.