 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimization in Machine Learning
Oct 30, 2024



Hyperparameters are configuration variables controlling the behavior of machine learning algorithms. They are ubiquitous in machine learning and artificial intelligence and the choice of their values determine the effectiveness of systems based on these technologies. Manual hyperparameter search is often unsatisfactory and becomes unfeasible when the number of hyperparameters is large. Automating the search is an important step towards automating machine learning, freeing researchers and practitioners alike from the burden of finding a good set of hyperparameters by trial and error. In this survey, we present a unified treatment of hyperparameter optimization, providing the reader with examples and insights into the state-of-the-art. We cover the main families of techniques to automate hyperparameter search, often referred to as hyperparameter optimization or tuning, including random and quasi-random search, bandit-, model- and gradient- based approaches. We further discuss extensions, including online, constrained, and multi-objective formulations, touch upon connections with other fields such as meta-learning and neural architecture search, and conclude with open questions and future research directions.
Learning Aggregation Functions
Dec 15, 2020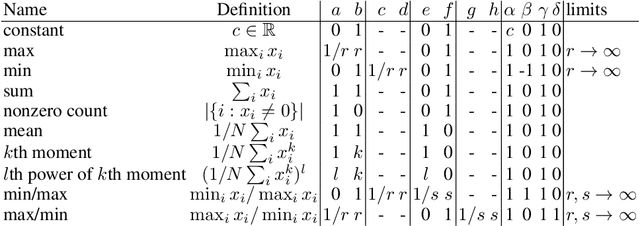
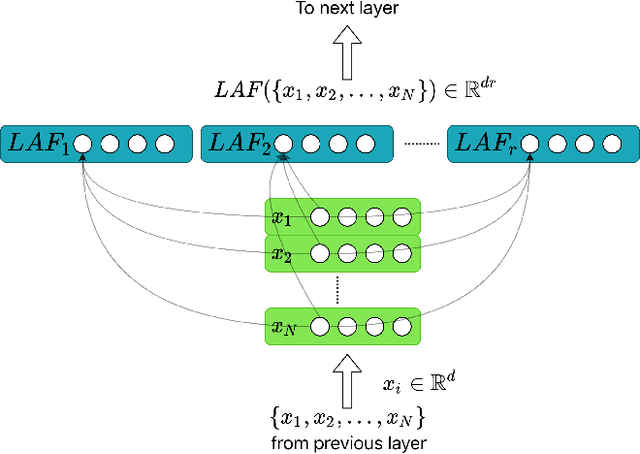

Learning on sets is increasingly gaining attention in the machine learning community, due to its widespread applicability. Typically, representations over sets are computed by using fixed aggregation functions such as sum or maximum. However, recent results showed that universal function representation by sum- (or max-) decomposition requires either highly discontinuous (and thus poorly learnable) mappings, or a latent dimension equal to the maximum number of elements in the set. To mitigate this problem, we introduce LAF (Learning Aggregation Functions), a learnable aggregator for sets of arbitrary cardinality. LAF can approximate several extensively used aggregators (such as average, sum, maximum) as well as more complex functions (e.g. variance and skewness). We report experiments on semi-synthetic and real data showing that LAF outperforms state-of-the-art sum- (max-) decomposition architectures such as DeepSets and library-based architectures like Principal Neighborhood Aggregation.
Classification of cancer pathology reports: a large-scale comparative study
Jun 29, 2020
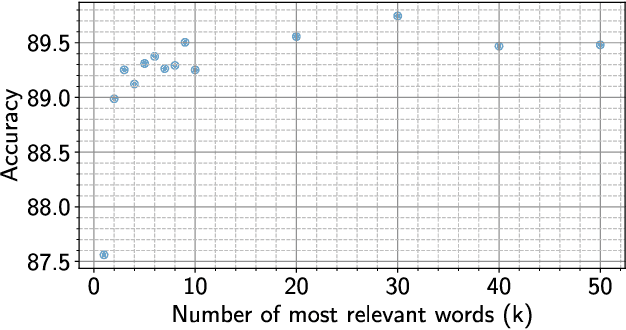
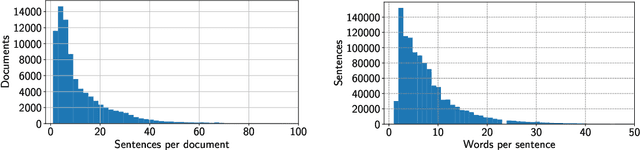
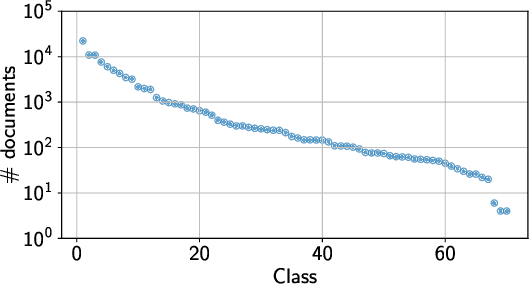
We report about the application of state-of-the-art deep learning techniques to the automatic and interpretable assignment of ICD-O3 topography and morphology codes to free-text cancer reports. We present results on a large dataset (more than 80 000 labeled and 1 500 000 unlabeled anonymized reports written in Italian and collected from hospitals in Tuscany over more than a decade) and with a large number of classes (134 morphological classes and 61 topographical classes). We compare alternative architectures in terms of prediction accuracy and interpretability and show that our best model achieves a multiclass accuracy of 90.3% on topography site assignment and 84.8% on morphology type assignment. We found that in this context hierarchical models are not better than flat models and that an element-wise maximum aggregator is slightly better than attentive models on site classification. Moreover, the maximum aggregator offers a way to interpret the classification process.
Scheduling the Learning Rate via Hypergradients: New Insights and a New Algorithm
Oct 18, 2019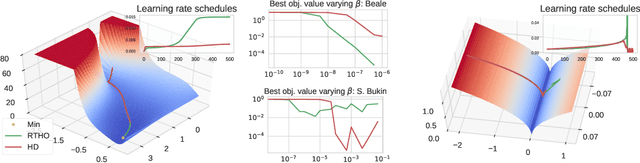
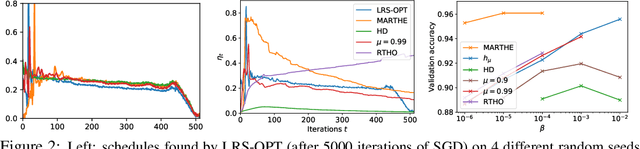
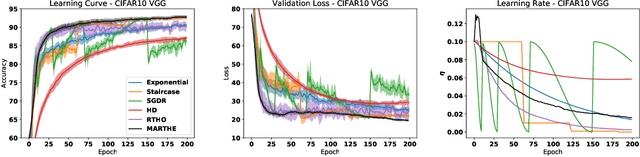
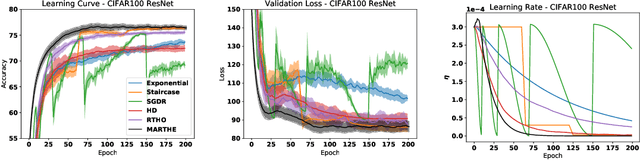
We study the problem of fitting task-specific learning rate schedules from the perspective of hyperparameter optimization. This allows us to explicitly search for schedules that achieve good generalization. We describe the structure of the gradient of a validation error w.r.t. the learning rate, the hypergradient, and based on this we introduce a novel online algorithm. Our method adaptively interpolates between the recently proposed techniques of Franceschi et al. (2017) and Baydin et al. (2017), featuring increased stability and faster convergence. We show empirically that the proposed method compares favourably with baselines and related methods in terms of final test accuracy.
Learning and Interpreting Multi-Multi-Instance Learning Networks
Oct 26, 2018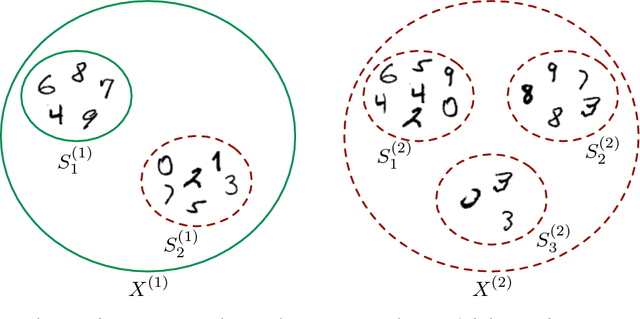
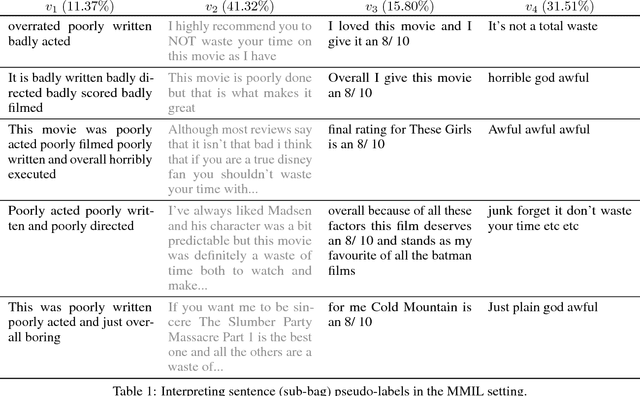
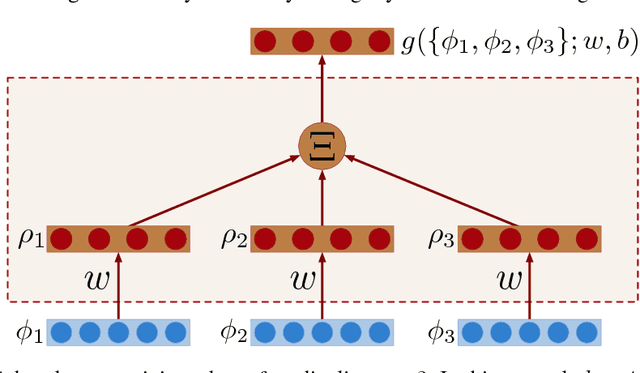
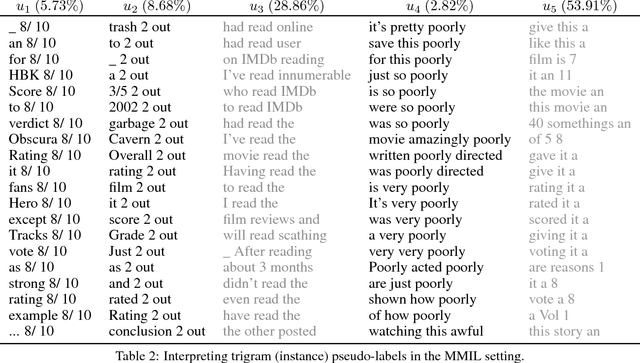
We introduce an extension of the multi-instance learning problem where examples are organized as nested bags of instances (e.g., a document could be represented as a bag of sentences, which in turn are bags of words). This framework can be useful in various scenarios, such as text and image classification, but also supervised learning over graphs. As a further advantage, multi-multi instance learning enables a particular way of interpreting predictions and the decision function. Our approach is based on a special neural network layer, called bag-layer, whose units aggregate bags of inputs of arbitrary size. We prove theoretically that the associated class of functions contains all Boolean functions over sets of sets of instances and we provide empirical evidence that functions of this kind can be actually learned on semi-synthetic datasets. We finally present experiments on text classification and on citation graphs and social graph data, showing that our model obtains competitive results with respect to other approaches such as convolutional networks on graphs.
Bilevel Programming for Hyperparameter Optimization and Meta-Learning
Jul 03, 2018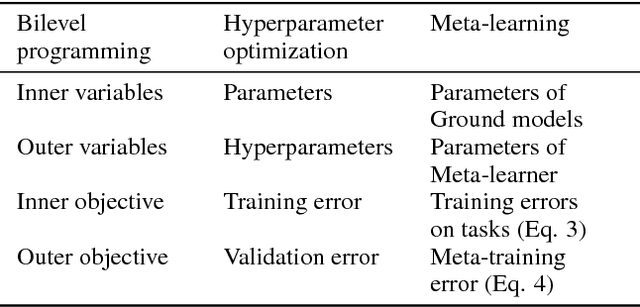
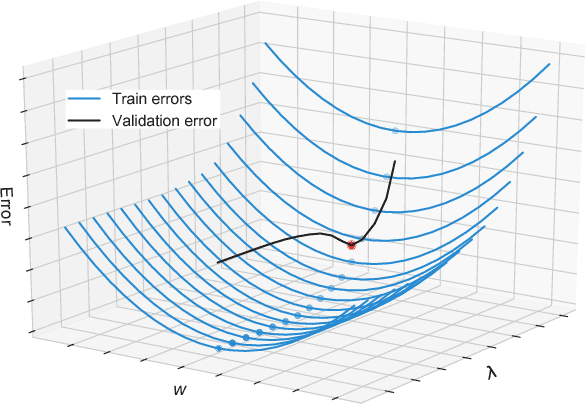
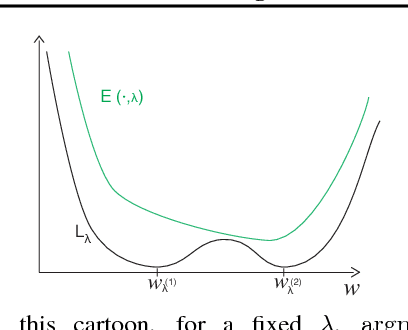
We introduce a framework based on bilevel programming that unifies gradient-based hyperparameter optimization and meta-learning. We show that an approximate version of the bilevel problem can be solved by taking into explicit account the optimization dynamics for the inner objective. Depending on the specific setting, the outer variables take either the meaning of hyperparameters in a supervised learning problem or parameters of a meta-learner. We provide sufficient conditions under which solutions of the approximate problem converge to those of the exact problem. We instantiate our approach for meta-learning in the case of deep learning where representation layers are treated as hyperparameters shared across a set of training episodes. In experiments, we confirm our theoretical findings, present encouraging results for few-shot learning and contrast the bilevel approach against classical approaches for learning-to-learn.
Far-HO: A Bilevel Programming Package for Hyperparameter Optimization and Meta-Learning
Jun 13, 2018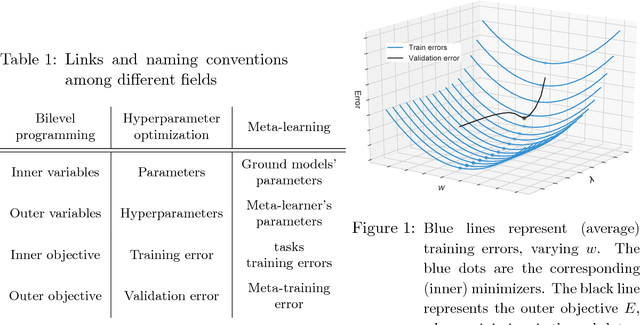
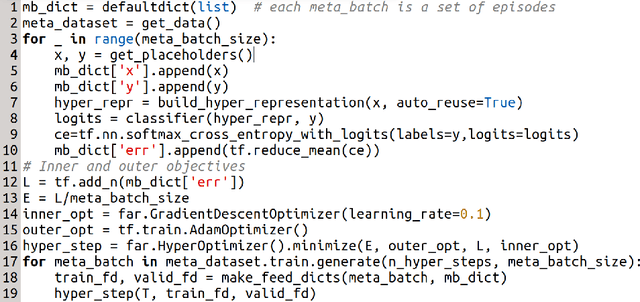
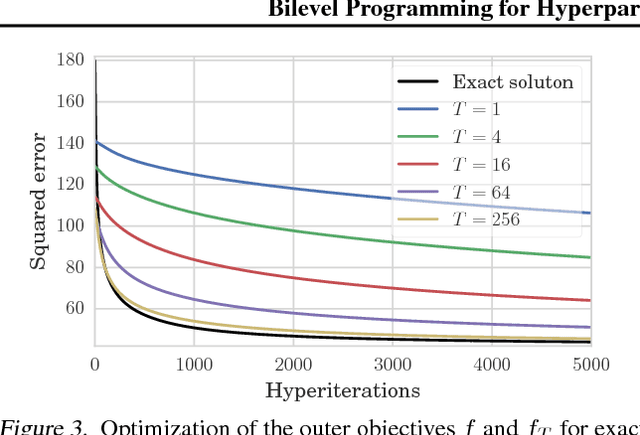
In (Franceschi et al., 2018) we proposed a unified mathematical framework, grounded on bilevel programming, that encompasses gradient-based hyperparameter optimization and meta-learning. We formulated an approximate version of the problem where the inner objective is solved iteratively, and gave sufficient conditions ensuring convergence to the exact problem. In this work we show how to optimize learning rates, automatically weight the loss of single examples and learn hyper-representations with Far-HO, a software package based on the popular deep learning framework TensorFlow that allows to seamlessly tackle both HO and ML problems.
Off the Beaten Track: Using Deep Learning to Interpolate Between Music Genres
May 02, 2018
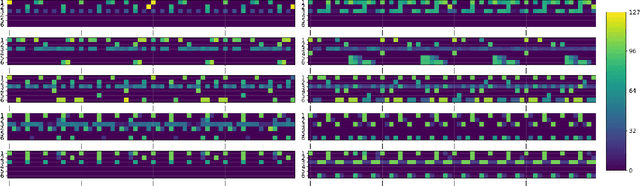
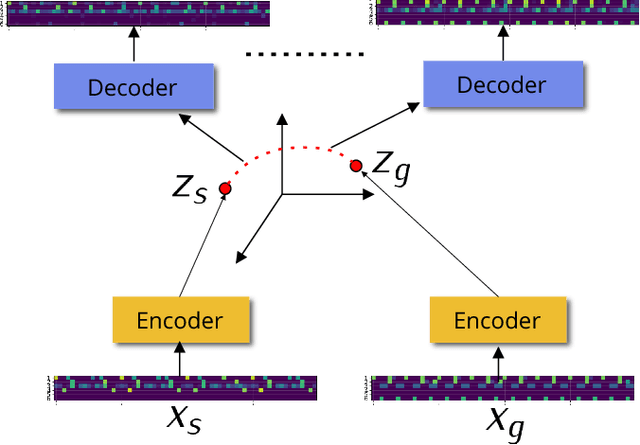
We describe a system based on deep learning that generates drum patterns in the electronic dance music domain. Experimental results reveal that generated patterns can be employed to produce musically sound and creative transitions between different genres, and that the process of generation is of interest to practitioners in the field.
A Bridge Between Hyperparameter Optimization and Larning-to-learn
Feb 04, 2018
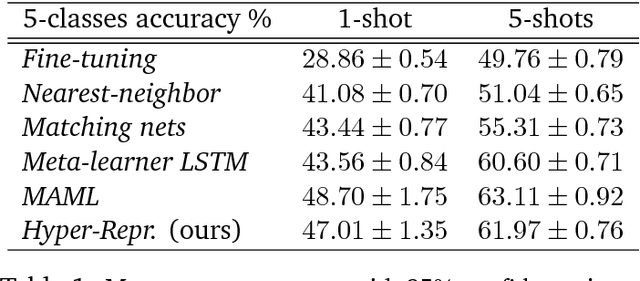
We consider a class of a nested optimization problems involving inner and outer objectives. We observe that by taking into explicit account the optimization dynamics for the inner objective it is possible to derive a general framework that unifies gradient-based hyperparameter optimization and meta-learning (or learning-to-learn). Depending on the specific setting, the variables of the outer objective take either the meaning of hyperparameters in a supervised learning problem or parameters of a meta-learner. We show that some recently proposed methods in the latter setting can be instantiated in our framework and tackled with the same gradient-based algorithms. Finally, we discuss possible design patterns for learning-to-learn and present encouraging preliminary experiments for few-shot learning.
Forward and Reverse Gradient-Based Hyperparameter Optimization
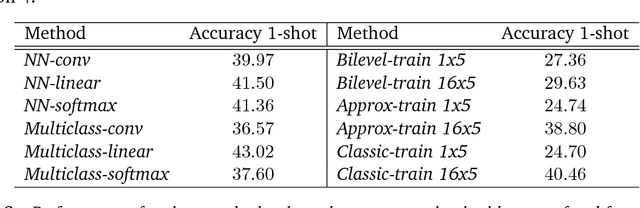
Dec 12, 2017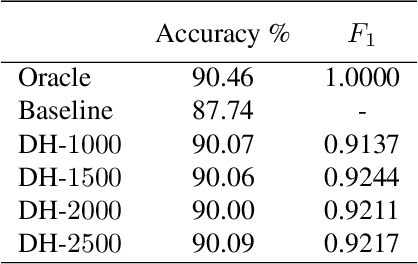
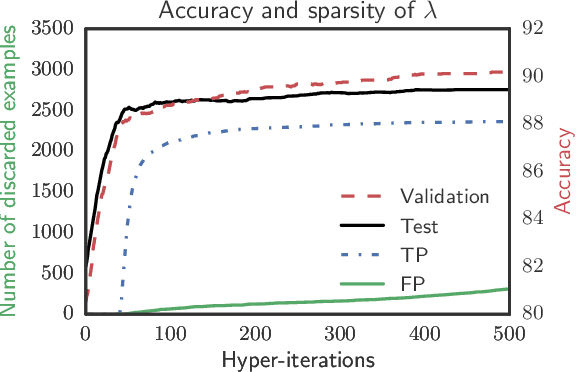
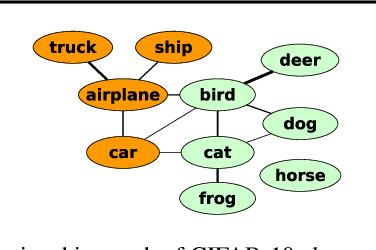
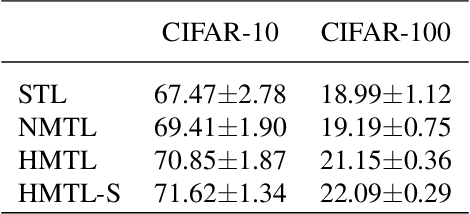
We study two procedures (reverse-mode and forward-mode) for computing the gradient of the validation error with respect to the hyperparameters of any iterative learning algorithm such as stochastic gradient descent. These procedures mirror two methods of computing gradients for recurrent neural networks and have different trade-offs in terms of running time and space requirements. Our formulation of the reverse-mode procedure is linked to previous work by Maclaurin et al. [2015] but does not require reversible dynamics. The forward-mode procedure is suitable for real-time hyperparameter updates, which may significantly speed up hyperparameter optimization on large datasets. We present experiments on data cleaning and on learning task interactions. We also present one large-scale experiment where the use of previous gradient-based methods would be prohibitive.
* - Posted the ICML Camera Ready version. - Added a link to a newer package implementation of the algorithms