 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of Batch Greenkhorn for Regularized Multimarginal Optimal Transport
Dec 03, 2021In this work we propose a batch version of the Greenkhorn algorithm for multimarginal regularized optimal transport problems. Our framework is general enough to cover, as particular cases, some existing algorithms like Sinkhorn and Greenkhorn algorithm for the bi-marginal setting, and (greedy) MultiSinkhorn for multimarginal optimal transport. We provide a complete convergence analysis, which is based on the properties of the iterative Bregman projections (IBP) method with greedy control. Global linear rate of convergence and explicit bound on the iteration complexity are obtained. When specialized to above mentioned algorithms, our results give new insights and/or improve existing ones.
Bilevel Programming for Hyperparameter Optimization and Meta-Learning
Jul 03, 2018
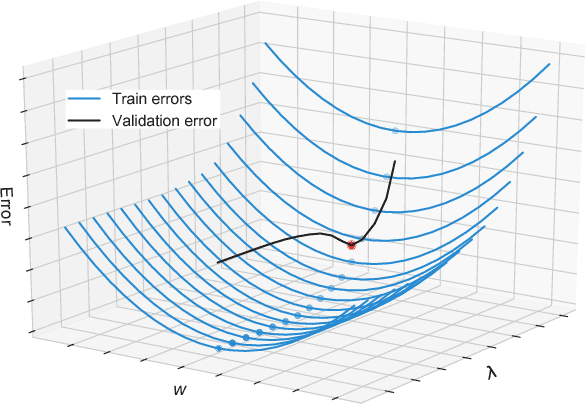
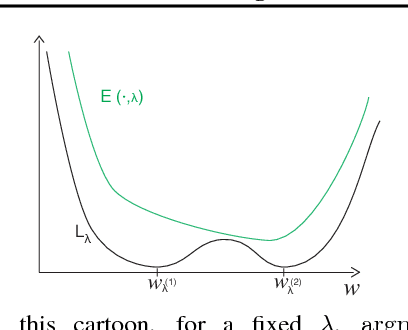
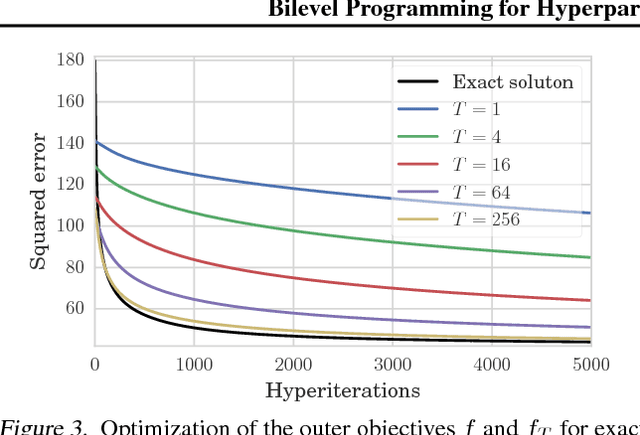
We introduce a framework based on bilevel programming that unifies gradient-based hyperparameter optimization and meta-learning. We show that an approximate version of the bilevel problem can be solved by taking into explicit account the optimization dynamics for the inner objective. Depending on the specific setting, the outer variables take either the meaning of hyperparameters in a supervised learning problem or parameters of a meta-learner. We provide sufficient conditions under which solutions of the approximate problem converge to those of the exact problem. We instantiate our approach for meta-learning in the case of deep learning where representation layers are treated as hyperparameters shared across a set of training episodes. In experiments, we confirm our theoretical findings, present encouraging results for few-shot learning and contrast the bilevel approach against classical approaches for learning-to-learn.
Conditional mean embeddings as regressors - supplementary
Jul 24, 2012
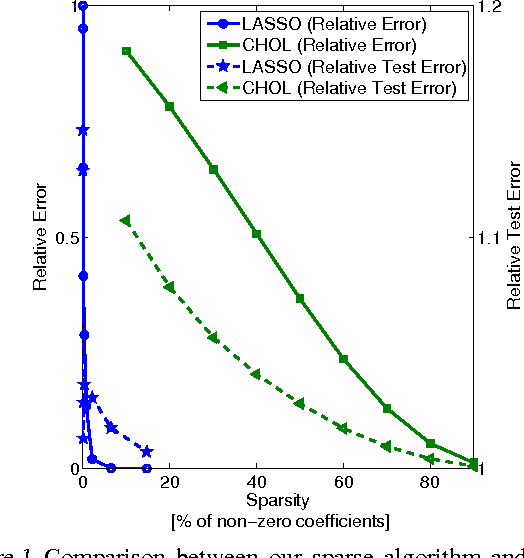
We demonstrate an equivalence between reproducing kernel Hilbert space (RKHS) embeddings of conditional distributions and vector-valued regressors. This connection introduces a natural regularized loss function which the RKHS embeddings minimise, providing an intuitive understanding of the embeddings and a justification for their use. Furthermore, the equivalence allows the application of vector-valued regression methods and results to the problem of learning conditional distributions. Using this link we derive a sparse version of the embedding by considering alternative formulations. Further, by applying convergence results for vector-valued regression to the embedding problem we derive minimax convergence rates which are O(\log(n)/n) -- compared to current state of the art rates of O(n^{-1/4}) -- and are valid under milder and more intuitive assumptions. These minimax upper rates coincide with lower rates up to a logarithmic factor, showing that the embedding method achieves nearly optimal rates. We study our sparse embedding algorithm in a reinforcement learning task where the algorithm shows significant improvement in sparsity over an incomplete Cholesky decomposition.