 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupport Collapse of Deep Gaussian Processes with Polynomial Kernels for a Wide Regime of Hyperparameters
Mar 15, 2025We analyze the prior that a Deep Gaussian Process with polynomial kernels induces. We observe that, even for relatively small depths, averaging effects occur within such a Deep Gaussian Process and that the prior can be analyzed and approximated effectively by means of the Berry-Esseen Theorem. One of the key findings of this analysis is that, in the absence of careful hyper-parameter tuning, the prior of a Deep Gaussian Process either collapses rapidly towards zero as the depth increases or places negligible mass on low norm functions. This aligns well with experimental findings and mirrors known results for convolution based Deep Gaussian Processes.
Estimating the Mixing Coefficients of Geometrically Ergodic Markov Processes
Feb 11, 2024We propose methods to estimate the individual $\beta$-mixing coefficients of a real-valued geometrically ergodic Markov process from a single sample-path $X_0,X_1, \dots,X_n$. Under standard smoothness conditions on the densities, namely, that the joint density of the pair $(X_0,X_m)$ for each $m$ lies in a Besov space $B^s_{1,\infty}(\mathbb R^2)$ for some known $s>0$, we obtain a rate of convergence of order $\mathcal{O}(\log(n) n^{-[s]/(2[s]+2)})$ for the expected error of our estimator in this case\footnote{We use $[s]$ to denote the integer part of the decomposition $s=[s]+\{s\}$ of $s \in (0,\infty)$ into an integer term and a {\em strictly positive} remainder term $\{s\} \in (0,1]$.}. We complement this result with a high-probability bound on the estimation error, and further obtain analogues of these bounds in the case where the state-space is finite. Naturally no density assumptions are required in this setting; the expected error rate is shown to be of order $\mathcal O(\log(n) n^{-1/2})$.
Compressed Empirical Measures (in finite dimensions)
Apr 19, 2022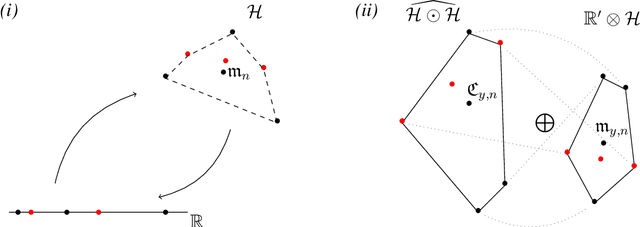
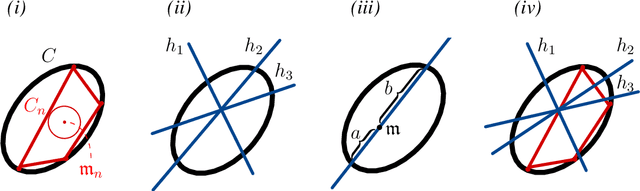
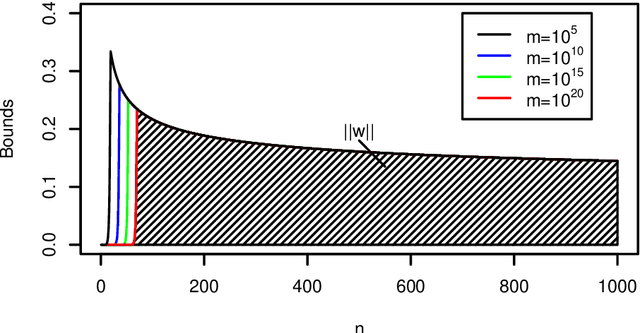
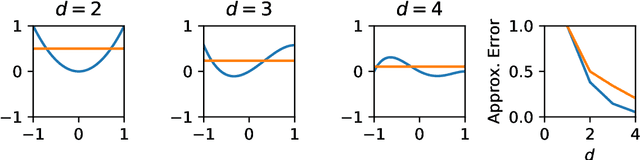
We study approaches for compressing the empirical measure in the context of finite dimensional reproducing kernel Hilbert spaces (RKHSs).In this context, the empirical measure is contained within a natural convex set and can be approximated using convex optimization methods. Such an approximation gives under certain conditions rise to a coreset of data points. A key quantity that controls how large such a coreset has to be is the size of the largest ball around the empirical measure that is contained within the empirical convex set. The bulk of our work is concerned with deriving high probability lower bounds on the size of such a ball under various conditions. We complement this derivation of the lower bound by developing techniques that allow us to apply the compression approach to concrete inference problems such as kernel ridge regression. We conclude with a construction of an infinite dimensional RKHS for which the compression is poor, highlighting some of the difficulties one faces when trying to move to infinite dimensional RKHSs.
Oblivious Data for Fairness with Kernels
Feb 07, 2020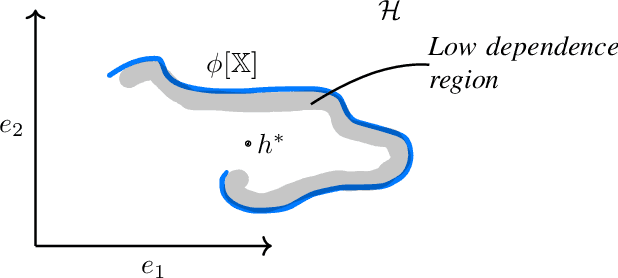
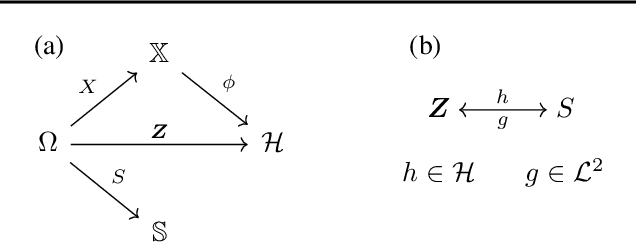
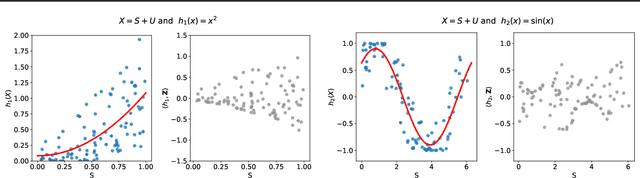
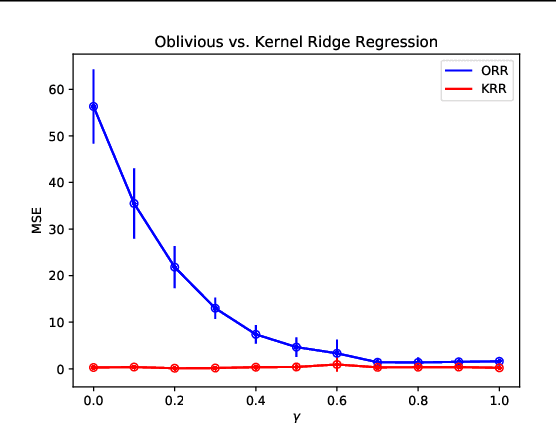
We investigate the problem of algorithmic fairness in the case where sensitive and non-sensitive features are available and one aims to generate new, `oblivious', features that closely approximate the non-sensitive features, and are only minimally dependent on the sensitive ones. We study this question in the context of kernel methods. We analyze a relaxed version of the Maximum Mean Discrepancy criterion which does not guarantee full independence but makes the optimization problem tractable. We derive a closed-form solution for this relaxed optimization problem and complement the result with a study of the dependencies between the newly generated features and the sensitive ones. Our key ingredient for generating such oblivious features is a Hilbert-space-valued conditional expectation, which needs to be estimated from data. We propose a plug-in approach and demonstrate how the estimation errors can be controlled. Our theoretical results are accompanied by experimental evaluations.
Recovering Bandits
Oct 31, 2019
We study the recovering bandits problem, a variant of the stochastic multi-armed bandit problem where the expected reward of each arm varies according to some unknown function of the time since the arm was last played. While being a natural extension of the classical bandit problem that arises in many real-world settings, this variation is accompanied by significant difficulties. In particular, methods need to plan ahead and estimate many more quantities than in the classical bandit setting. In this work, we explore the use of Gaussian processes to tackle the estimation and planing problem. We also discuss different regret definitions that let us quantify the performance of the methods. To improve computational efficiency of the methods, we provide an optimistic planning approximation. We complement these discussions with regret bounds and empirical studies.
Modeling transition dynamics in MDPs with RKHS embeddings of conditional distributions
Oct 18, 2012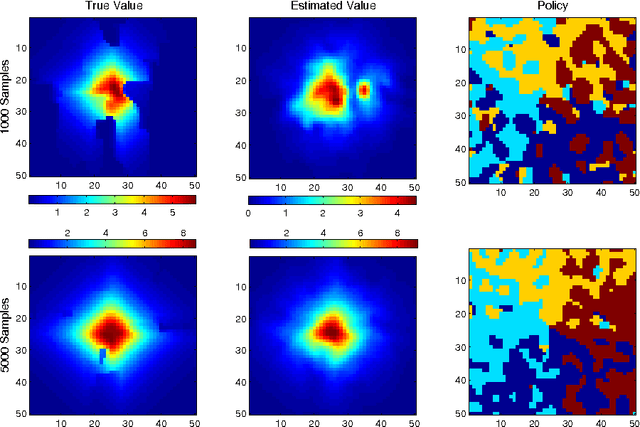
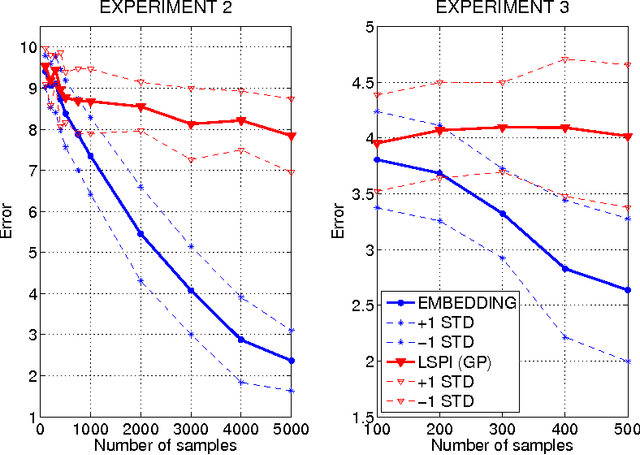
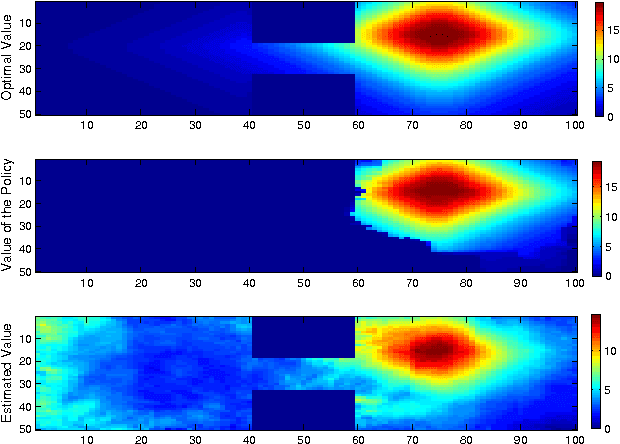
We propose a new, nonparametric approach to estimating the value function in reinforcement learning. This approach makes use of a recently developed representation of conditional distributions as functions in a reproducing kernel Hilbert space. Such representations bypass the need for estimating transition probabilities, and apply to any domain on which kernels can be defined. Our approach avoids the need to approximate intractable integrals since expectations are represented as RKHS inner products whose computation has linear complexity in the sample size. Thus, we can efficiently perform value function estimation in a wide variety of settings, including finite state spaces, continuous states spaces, and partially observable tasks where only sensor measurements are available. A second advantage of the approach is that we learn the conditional distribution representation from a training sample, and do not require an exhaustive exploration of the state space. We prove convergence of our approach either to the optimal policy, or to the closest projection of the optimal policy in our model class, under reasonable assumptions. In experiments, we demonstrate the performance of our algorithm on a learning task in a continuous state space (the under-actuated pendulum), and on a navigation problem where only images from a sensor are observed. We compare with least-squares policy iteration where a Gaussian process is used for value function estimation. Our algorithm achieves better performance in both tasks.
Conditional mean embeddings as regressors - supplementary
Jul 24, 2012
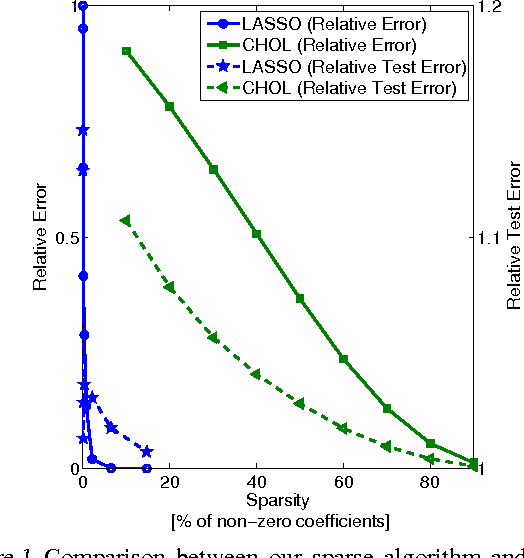
We demonstrate an equivalence between reproducing kernel Hilbert space (RKHS) embeddings of conditional distributions and vector-valued regressors. This connection introduces a natural regularized loss function which the RKHS embeddings minimise, providing an intuitive understanding of the embeddings and a justification for their use. Furthermore, the equivalence allows the application of vector-valued regression methods and results to the problem of learning conditional distributions. Using this link we derive a sparse version of the embedding by considering alternative formulations. Further, by applying convergence results for vector-valued regression to the embedding problem we derive minimax convergence rates which are O(\log(n)/n) -- compared to current state of the art rates of O(n^{-1/4}) -- and are valid under milder and more intuitive assumptions. These minimax upper rates coincide with lower rates up to a logarithmic factor, showing that the embedding method achieves nearly optimal rates. We study our sparse embedding algorithm in a reinforcement learning task where the algorithm shows significant improvement in sparsity over an incomplete Cholesky decomposition.
The Optimal Unbiased Value Estimator and its Relation to LSTD, TD and MC
Aug 24, 2009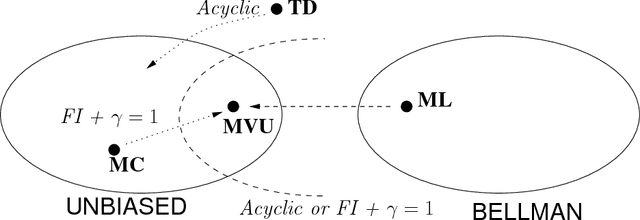
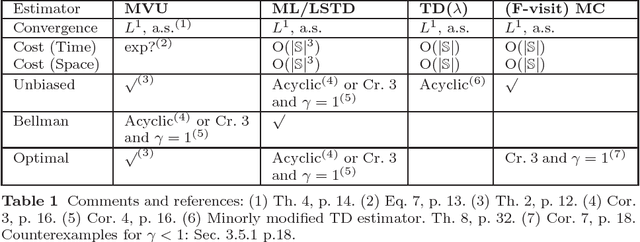
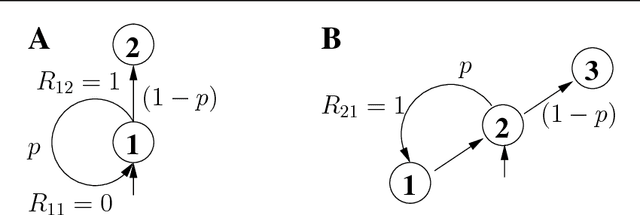

In this analytical study we derive the optimal unbiased value estimator (MVU) and compare its statistical risk to three well known value estimators: Temporal Difference learning (TD), Monte Carlo estimation (MC) and Least-Squares Temporal Difference Learning (LSTD). We demonstrate that LSTD is equivalent to the MVU if the Markov Reward Process (MRP) is acyclic and show that both differ for most cyclic MRPs as LSTD is then typically biased. More generally, we show that estimators that fulfill the Bellman equation can only be unbiased for special cyclic MRPs. The main reason being the probability measures with which the expectations are taken. These measure vary from state to state and due to the strong coupling by the Bellman equation it is typically not possible for a set of value estimators to be unbiased with respect to each of these measures. Furthermore, we derive relations of the MVU to MC and TD. The most important one being the equivalence of MC to the MVU and to LSTD for undiscounted MRPs in which MC has the same amount of information. In the discounted case this equivalence does not hold anymore. For TD we show that it is essentially unbiased for acyclic MRPs and biased for cyclic MRPs. We also order estimators according to their risk and present counter-examples to show that no general ordering exists between the MVU and LSTD, between MC and LSTD and between TD and MC. Theoretical results are supported by examples and an empirical evaluation.