 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Optimal Unbiased Value Estimator and its Relation to LSTD, TD and MC
Paper and Code
Aug 24, 2009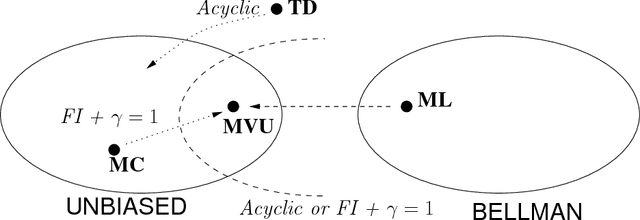
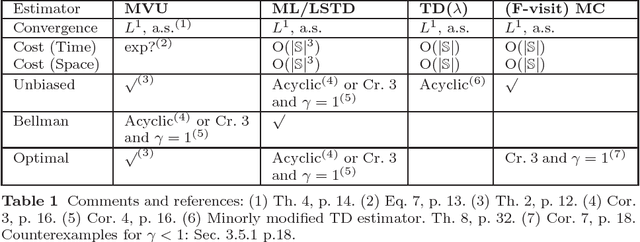
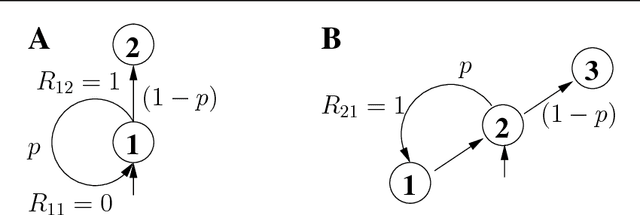

In this analytical study we derive the optimal unbiased value estimator (MVU) and compare its statistical risk to three well known value estimators: Temporal Difference learning (TD), Monte Carlo estimation (MC) and Least-Squares Temporal Difference Learning (LSTD). We demonstrate that LSTD is equivalent to the MVU if the Markov Reward Process (MRP) is acyclic and show that both differ for most cyclic MRPs as LSTD is then typically biased. More generally, we show that estimators that fulfill the Bellman equation can only be unbiased for special cyclic MRPs. The main reason being the probability measures with which the expectations are taken. These measure vary from state to state and due to the strong coupling by the Bellman equation it is typically not possible for a set of value estimators to be unbiased with respect to each of these measures. Furthermore, we derive relations of the MVU to MC and TD. The most important one being the equivalence of MC to the MVU and to LSTD for undiscounted MRPs in which MC has the same amount of information. In the discounted case this equivalence does not hold anymore. For TD we show that it is essentially unbiased for acyclic MRPs and biased for cyclic MRPs. We also order estimators according to their risk and present counter-examples to show that no general ordering exists between the MVU and LSTD, between MC and LSTD and between TD and MC. Theoretical results are supported by examples and an empirical evaluation.