 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalience-SGG: Enhancing Unbiased Scene Graph Generation with Iterative Salience Estimation
Jan 13, 2026Scene Graph Generation (SGG) suffers from a long-tailed distribution, where a few predicate classes dominate while many others are underrepresented, leading to biased models that underperform on rare relations. Unbiased-SGG methods address this issue by implementing debiasing strategies, but often at the cost of spatial understanding, resulting in an over-reliance on semantic priors. We introduce Salience-SGG, a novel framework featuring an Iterative Salience Decoder (ISD) that emphasizes triplets with salient spatial structures. To support this, we propose semantic-agnostic salience labels guiding ISD. Evaluations on Visual Genome, Open Images V6, and GQA-200 show that Salience-SGG achieves state-of-the-art performance and improves existing Unbiased-SGG methods in their spatial understanding as demonstrated by the Pairwise Localization Average Precision
Neural Proxies for Sound Synthesizers: Learning Perceptually Informed Preset Representations
Sep 09, 2025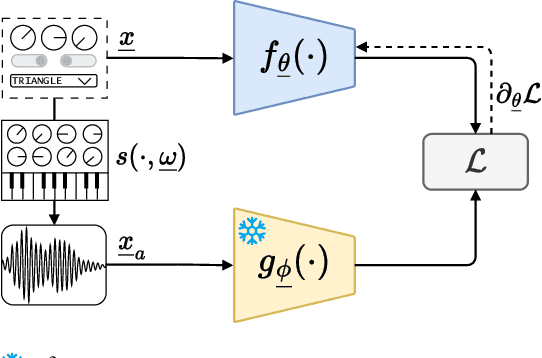
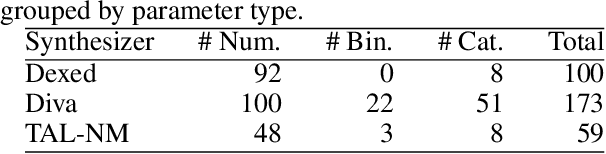


Deep learning appears as an appealing solution for Automatic Synthesizer Programming (ASP), which aims to assist musicians and sound designers in programming sound synthesizers. However, integrating software synthesizers into training pipelines is challenging due to their potential non-differentiability. This work tackles this challenge by introducing a method to approximate arbitrary synthesizers. Specifically, we train a neural network to map synthesizer presets onto an audio embedding space derived from a pretrained model. This facilitates the definition of a neural proxy that produces compact yet effective representations, thereby enabling the integration of audio embedding loss into neural-based ASP systems for black-box synthesizers. We evaluate the representations derived by various pretrained audio models in the context of neural-based nASP and assess the effectiveness of several neural network architectures, including feedforward, recurrent, and transformer-based models, in defining neural proxies. We evaluate the proposed method using both synthetic and hand-crafted presets from three popular software synthesizers and assess its performance in a synthesizer sound matching downstream task. While the benefits of the learned representation are nuanced by resource requirements, encouraging results were obtained for all synthesizers, paving the way for future research into the application of synthesizer proxies for neural-based ASP systems.
* 17 pages, 4 figures, published in the Journal of the Audio Engineering Society
A Robotics-Inspired Scanpath Model Reveals the Importance of Uncertainty and Semantic Object Cues for Gaze Guidance in Dynamic Scenes
Aug 02, 2024



How we perceive objects around us depends on what we actively attend to, yet our eye movements depend on the perceived objects. Still, object segmentation and gaze behavior are typically treated as two independent processes. Drawing on an information processing pattern from robotics, we present a mechanistic model that simulates these processes for dynamic real-world scenes. Our image-computable model uses the current scene segmentation for object-based saccadic decision-making while using the foveated object to refine its scene segmentation recursively. To model this refinement, we use a Bayesian filter, which also provides an uncertainty estimate for the segmentation that we use to guide active scene exploration. We demonstrate that this model closely resembles observers' free viewing behavior, measured by scanpath statistics, including foveation duration and saccade amplitude distributions used for parameter fitting and higher-level statistics not used for fitting. These include how object detections, inspections, and returns are balanced and a delay of returning saccades without an explicit implementation of such temporal inhibition of return. Extensive simulations and ablation studies show that uncertainty promotes balanced exploration and that semantic object cues are crucial to form the perceptual units used in object-based attention. Moreover, we show how our model's modular design allows for extensions, such as incorporating saccadic momentum or pre-saccadic attention, to further align its output with human scanpaths.
Transfer Learning for Segmentation Problems: Choose the Right Encoder and Skip the Decoder
Jul 29, 2022



It is common practice to reuse models initially trained on different data to increase downstream task performance. Especially in the computer vision domain, ImageNet-pretrained weights have been successfully used for various tasks. In this work, we investigate the impact of transfer learning for segmentation problems, being pixel-wise classification problems that can be tackled with encoder-decoder architectures. We find that transfer learning the decoder does not help downstream segmentation tasks, while transfer learning the encoder is truly beneficial. We demonstrate that pretrained weights for a decoder may yield faster convergence, but they do not improve the overall model performance as one can obtain equivalent results with randomly initialized decoders. However, we show that it is more effective to reuse encoder weights trained on a segmentation or reconstruction task than reusing encoder weights trained on classification tasks. This finding implicates that using ImageNet-pretrained encoders for downstream segmentation problems is suboptimal. We also propose a contrastive self-supervised approach with multiple self-reconstruction tasks, which provides encoders that are suitable for transfer learning in segmentation problems in the absence of segmentation labels.
Similarity of Pre-trained and Fine-tuned Representations
Jul 19, 2022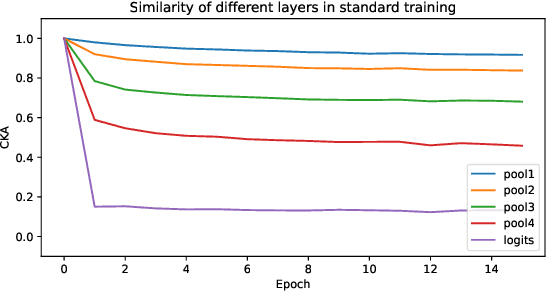
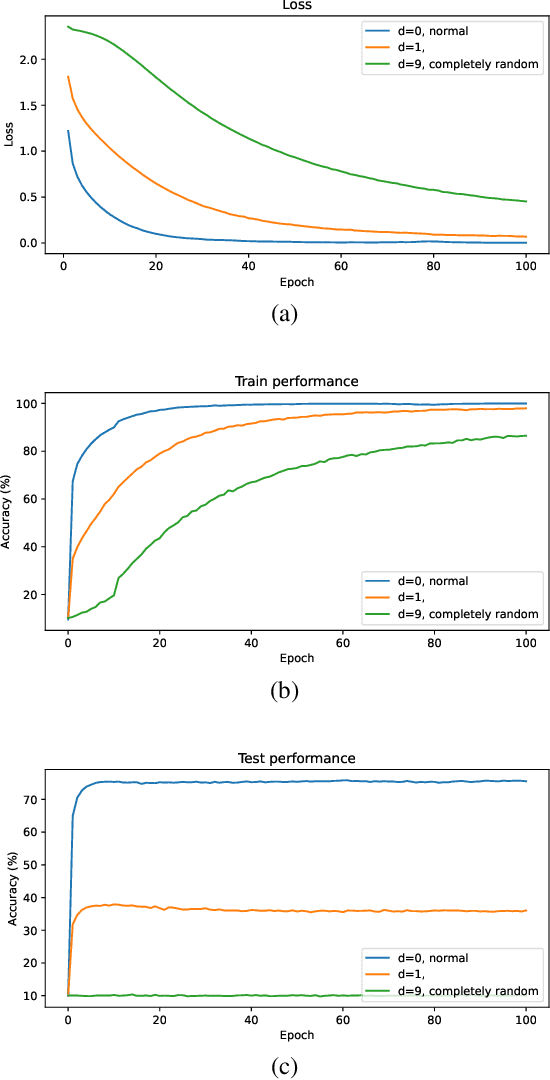


In transfer learning, only the last part of the networks - the so-called head - is often fine-tuned. Representation similarity analysis shows that the most significant change still occurs in the head even if all weights are updatable. However, recent results from few-shot learning have shown that representation change in the early layers, which are mostly convolutional, is beneficial, especially in the case of cross-domain adaption. In our paper, we find out whether that also holds true for transfer learning. In addition, we analyze the change of representation in transfer learning, both during pre-training and fine-tuning, and find out that pre-trained structure is unlearned if not usable.
A modular framework for object-based saccadic decisions in dynamic scenes
Jun 10, 2021

Visually exploring the world around us is not a passive process. Instead, we actively explore the world and acquire visual information over time. Here, we present a new model for simulating human eye-movement behavior in dynamic real-world scenes. We model this active scene exploration as a sequential decision making process. We adapt the popular drift-diffusion model (DDM) for perceptual decision making and extend it towards multiple options, defined by objects present in the scene. For each possible choice, the model integrates evidence over time and a decision (saccadic eye movement) is triggered as soon as evidence crosses a decision threshold. Drawing this explicit connection between decision making and object-based scene perception is highly relevant in the context of active viewing, where decisions are made continuously while interacting with an external environment. We validate our model with a carefully designed ablation study and explore influences of our model parameters. A comparison on the VidCom dataset supports the plausibility of the proposed approach.
Exploring the Similarity of Representations in Model-Agnostic Meta-Learning
May 12, 2021

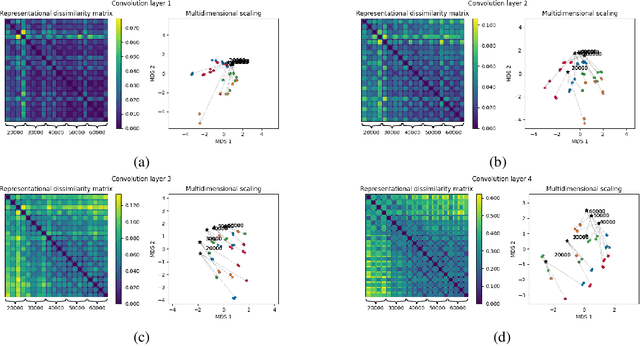
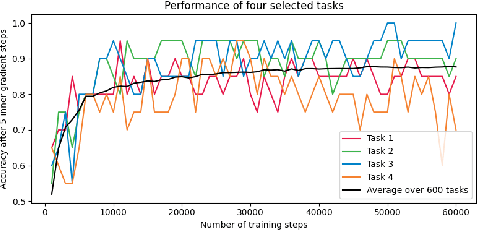
In past years model-agnostic meta-learning (MAML) has been one of the most promising approaches in meta-learning. It can be applied to different kinds of problems, e.g., reinforcement learning, but also shows good results on few-shot learning tasks. Besides their tremendous success in these tasks, it has still not been fully revealed yet, why it works so well. Recent work proposes that MAML rather reuses features than rapidly learns. In this paper, we want to inspire a deeper understanding of this question by analyzing MAML's representation. We apply representation similarity analysis (RSA), a well-established method in neuroscience, to the few-shot learning instantiation of MAML. Although some part of our analysis supports their general results that feature reuse is predominant, we also reveal arguments against their conclusion. The similarity-increase of layers closer to the input layers arises from the learning task itself and not from the model. In addition, the representations after inner gradient steps make a broader change to the representation than the changes during meta-training.
Training Generative Networks with general Optimal Transport distances
Oct 01, 2019



We propose a new algorithm that uses an auxiliary Neural Network to calculate the transport distance between two data distributions and export an optimal transport map. In the sequel we use the aforementioned map to train Generative Networks. Unlike WGANs, where the Euclidean distance is implicitly used, this new method allows to use any transportation cost function that can be chosen to match the problem at hand. More specifically, it allows to use the squared distance as a transportation cost function, giving rise to the Wasserstein-2 metric for probability distributions, which has rich geometric properties that result in fast and stable gradients descends. It also allows to use image centered distances, like the Structure Similarity index, with notable differences in the results.
The NIGENS General Sound Events Database
Apr 03, 2019
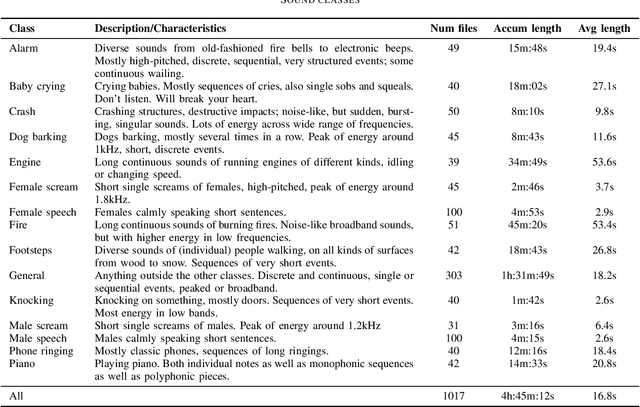
Computational auditory scene analysis is gaining interest in the last years. Trailing behind the more mature field of speech recognition, it is particularly general sound event detection that is attracting increasing attention. Crucial for training and testing reasonable models is having available enough suitable data -- until recently, general sound event databases were hardly found. We release and present a database with 714 wav files containing isolated high quality sound events of 14 different types, plus 303 `general' wav files of anything else but these 14 types. All sound events are strongly labeled with perceptual on- and offset times, paying attention to omitting in-between silences. The amount of isolated sound events, the quality of annotations, and the particular general sound class distinguish NIGENS from other databases.
Non-Deterministic Policy Improvement Stabilizes Approximated Reinforcement Learning
Dec 22, 2016
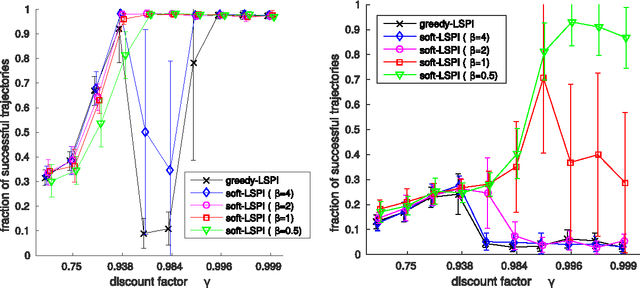
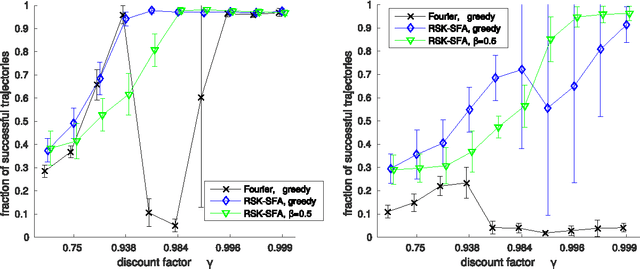
This paper investigates a type of instability that is linked to the greedy policy improvement in approximated reinforcement learning. We show empirically that non-deterministic policy improvement can stabilize methods like LSPI by controlling the improvements' stochasticity. Additionally we show that a suitable representation of the value function also stabilizes the solution to some degree. The presented approach is simple and should also be easily transferable to more sophisticated algorithms like deep reinforcement learning.