 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Event Alignment for Monocular Distance Estimation
Oct 29, 2024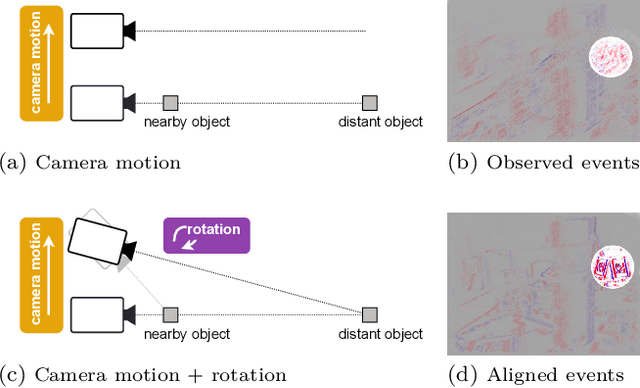

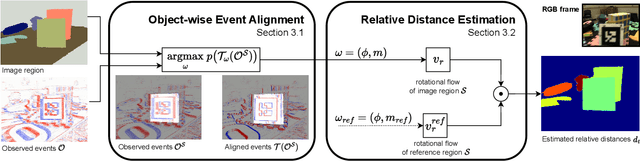
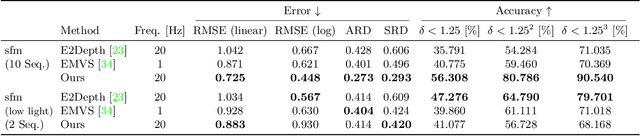
Event cameras provide a natural and data efficient representation of visual information, motivating novel computational strategies towards extracting visual information. Inspired by the biological vision system, we propose a behavior driven approach for object-wise distance estimation from event camera data. This behavior-driven method mimics how biological systems, like the human eye, stabilize their view based on object distance: distant objects require minimal compensatory rotation to stay in focus, while nearby objects demand greater adjustments to maintain alignment. This adaptive strategy leverages natural stabilization behaviors to estimate relative distances effectively. Unlike traditional vision algorithms that estimate depth across the entire image, our approach targets local depth estimation within a specific region of interest. By aligning events within a small region, we estimate the angular velocity required to stabilize the image motion. We demonstrate that, under certain assumptions, the compensatory rotational flow is inversely proportional to the object's distance. The proposed approach achieves new state-of-the-art accuracy in distance estimation - a performance gain of 16% on EVIMO2. EVIMO2 event sequences comprise complex camera motion and substantial variance in depth of static real world scenes.
How Do You Perceive My Face? Recognizing Facial Expressions in Multi-Modal Context by Modeling Mental Representations
Sep 04, 2024



Facial expression perception in humans inherently relies on prior knowledge and contextual cues, contributing to efficient and flexible processing. For instance, multi-modal emotional context (such as voice color, affective text, body pose, etc.) can prompt people to perceive emotional expressions in objectively neutral faces. Drawing inspiration from this, we introduce a novel approach for facial expression classification that goes beyond simple classification tasks. Our model accurately classifies a perceived face and synthesizes the corresponding mental representation perceived by a human when observing a face in context. With this, our model offers visual insights into its internal decision-making process. We achieve this by learning two independent representations of content and context using a VAE-GAN architecture. Subsequently, we propose a novel attention mechanism for context-dependent feature adaptation. The adapted representation is used for classification and to generate a context-augmented expression. We evaluate synthesized expressions in a human study, showing that our model effectively produces approximations of human mental representations. We achieve State-of-the-Art classification accuracies of 81.01% on the RAVDESS dataset and 79.34% on the MEAD dataset. We make our code publicly available.
Watching Swarm Dynamics from Above: A Framework for Advanced Object Tracking in Drone Videos
Jun 11, 2024



Easily accessible sensors, like drones with diverse onboard sensors, have greatly expanded studying animal behavior in natural environments. Yet, analyzing vast, unlabeled video data, often spanning hours, remains a challenge for machine learning, especially in computer vision. Existing approaches often analyze only a few frames. Our focus is on long-term animal behavior analysis. To address this challenge, we utilize classical probabilistic methods for state estimation, such as particle filtering. By incorporating recent advancements in semantic object segmentation, we enable continuous tracking of rapidly evolving object formations, even in scenarios with limited data availability. Particle filters offer a provably optimal algorithmic structure for recursively adding new incoming information. We propose a novel approach for tracking schools of fish in the open ocean from drone videos. Our framework not only performs classical object tracking in 2D, instead it tracks the position and spatial expansion of the fish school in world coordinates by fusing video data and the drone's on board sensor information (GPS and IMU). The presented framework for the first time allows researchers to study collective behavior of fish schools in its natural social and environmental context in a non-invasive and scalable way.
Multi-Task Multi-Modal Self-Supervised Learning for Facial Expression Recognition
Apr 16, 2024
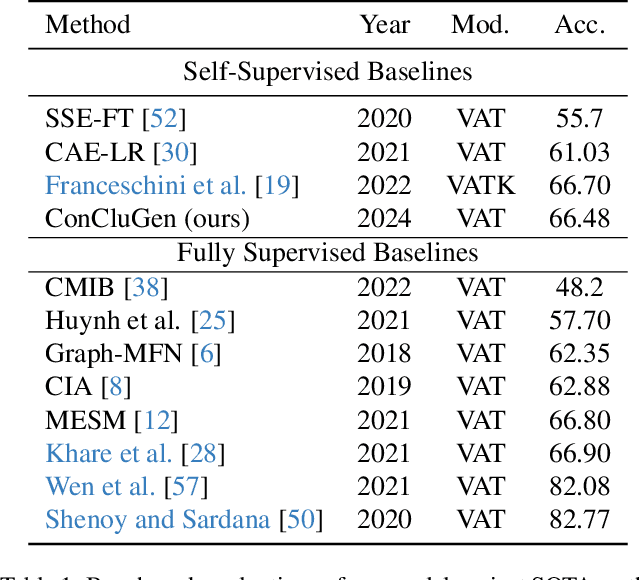
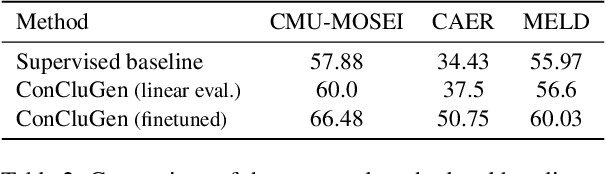

Human communication is multi-modal; e.g., face-to-face interaction involves auditory signals (speech) and visual signals (face movements and hand gestures). Hence, it is essential to exploit multiple modalities when designing machine learning-based facial expression recognition systems. In addition, given the ever-growing quantities of video data that capture human facial expressions, such systems should utilize raw unlabeled videos without requiring expensive annotations. Therefore, in this work, we employ a multitask multi-modal self-supervised learning method for facial expression recognition from in-the-wild video data. Our model combines three self-supervised objective functions: First, a multi-modal contrastive loss, that pulls diverse data modalities of the same video together in the representation space. Second, a multi-modal clustering loss that preserves the semantic structure of input data in the representation space. Finally, a multi-modal data reconstruction loss. We conduct a comprehensive study on this multimodal multi-task self-supervised learning method on three facial expression recognition benchmarks. To that end, we examine the performance of learning through different combinations of self-supervised tasks on the facial expression recognition downstream task. Our model ConCluGen outperforms several multi-modal self-supervised and fully supervised baselines on the CMU-MOSEI dataset. Our results generally show that multi-modal self-supervision tasks offer large performance gains for challenging tasks such as facial expression recognition, while also reducing the amount of manual annotations required. We release our pre-trained models as well as source code publicly
Action-based Contrastive Learning for Trajectory Prediction
Jul 18, 2022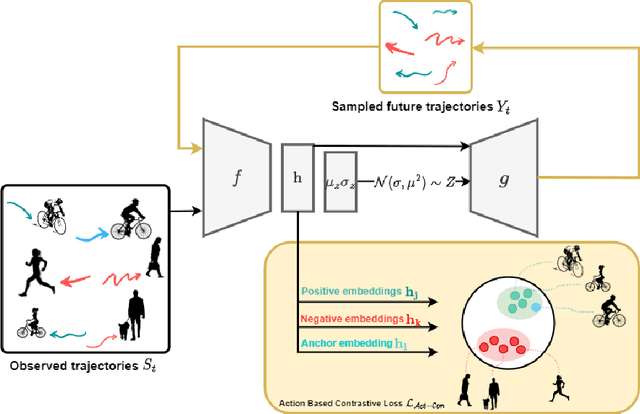
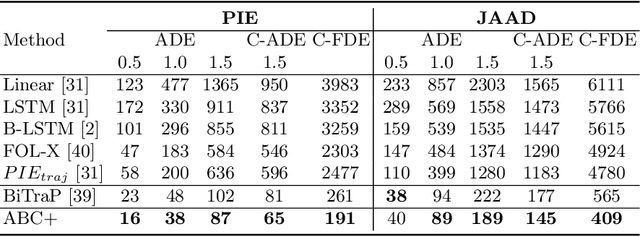

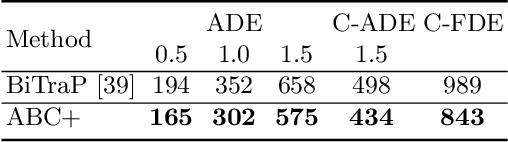
Trajectory prediction is an essential task for successful human robot interaction, such as in autonomous driving. In this work, we address the problem of predicting future pedestrian trajectories in a first person view setting with a moving camera. To that end, we propose a novel action-based contrastive learning loss, that utilizes pedestrian action information to improve the learned trajectory embeddings. The fundamental idea behind this new loss is that trajectories of pedestrians performing the same action should be closer to each other in the feature space than the trajectories of pedestrians with significantly different actions. In other words, we argue that behavioral information about pedestrian action influences their future trajectory. Furthermore, we introduce a novel sampling strategy for trajectories that is able to effectively increase negative and positive contrastive samples. Additional synthetic trajectory samples are generated using a trained Conditional Variational Autoencoder (CVAE), which is at the core of several models developed for trajectory prediction. Results show that our proposed contrastive framework employs contextual information about pedestrian behavior, i.e. action, effectively, and it learns a better trajectory representation. Thus, integrating the proposed contrastive framework within a trajectory prediction model improves its results and outperforms state-of-the-art methods on three trajectory prediction benchmarks [31, 32, 26].
The Right Spin: Learning Object Motion from Rotation-Compensated Flow Fields
Feb 28, 2022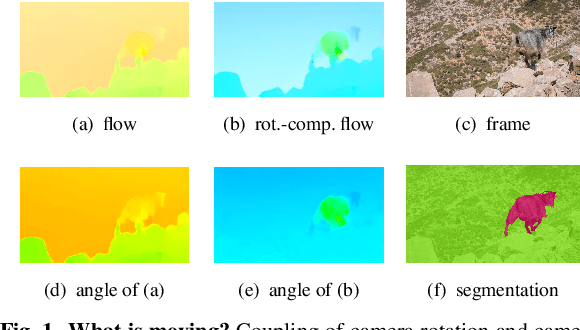
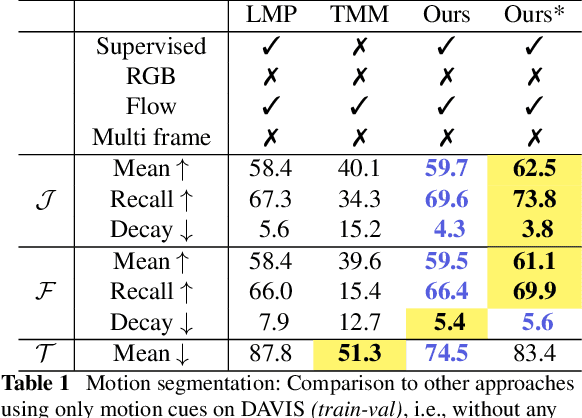
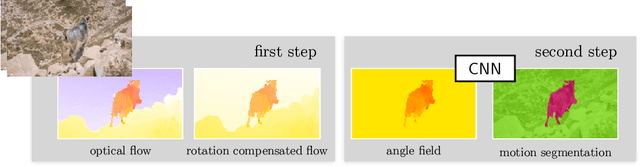
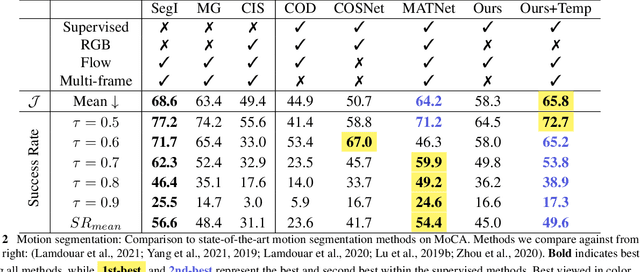
Both a good understanding of geometrical concepts and a broad familiarity with objects lead to our excellent perception of moving objects. The human ability to detect and segment moving objects works in the presence of multiple objects, complex background geometry, motion of the observer and even camouflage. How humans perceive moving objects so reliably is a longstanding research question in computer vision and borrows findings from related areas such as psychology, cognitive science and physics. One approach to the problem is to teach a deep network to model all of these effects. This contrasts with the strategy used by human vision, where cognitive processes and body design are tightly coupled and each is responsible for certain aspects of correctly identifying moving objects. Similarly from the computer vision perspective, there is evidence that classical, geometry-based techniques are better suited to the "motion-based" parts of the problem, while deep networks are more suitable for modeling appearance. In this work, we argue that the coupling of camera rotation and camera translation can create complex motion fields that are difficult for a deep network to untangle directly. We present a novel probabilistic model to estimate the camera's rotation given the motion field. We then rectify the flow field to obtain a rotation-compensated motion field for subsequent segmentation. This strategy of first estimating camera motion, and then allowing a network to learn the remaining parts of the problem, yields improved results on the widely used DAVIS benchmark as well as the recently published motion segmentation data set MoCA (Moving Camouflaged Animals).
The Spatio-Temporal Poisson Point Process: A Simple Model for the Alignment of Event Camera Data
Jun 13, 2021
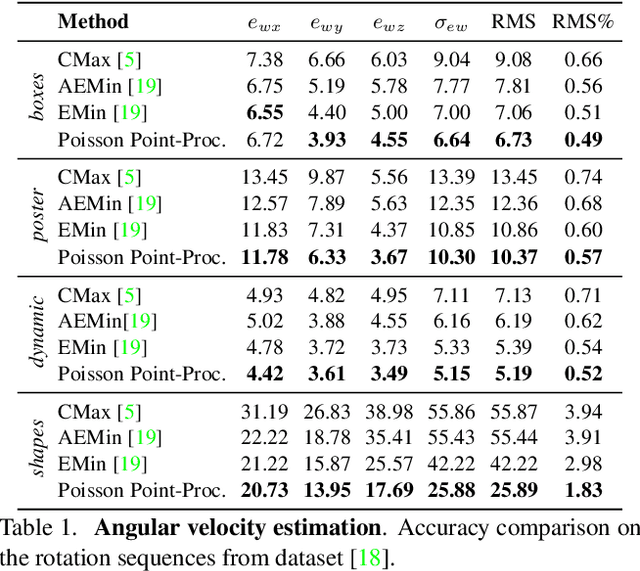
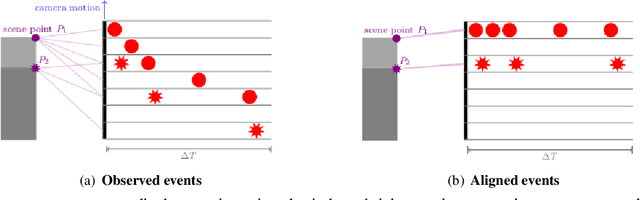
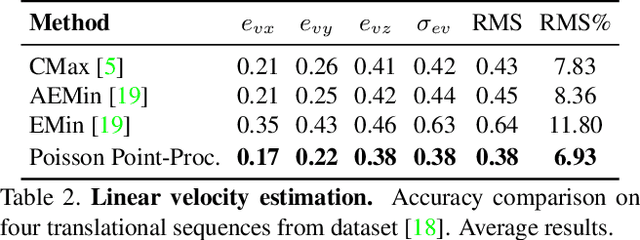
Event cameras, inspired by biological vision systems, provide a natural and data efficient representation of visual information. Visual information is acquired in the form of events that are triggered by local brightness changes. Each pixel location of the camera's sensor records events asynchronously and independently with very high temporal resolution. However, because most brightness changes are triggered by relative motion of the camera and the scene, the events recorded at a single sensor location seldom correspond to the same world point. To extract meaningful information from event cameras, it is helpful to register events that were triggered by the same underlying world point. In this work we propose a new model of event data that captures its natural spatio-temporal structure. We start by developing a model for aligned event data. That is, we develop a model for the data as though it has been perfectly registered already. In particular, we model the aligned data as a spatio-temporal Poisson point process. Based on this model, we develop a maximum likelihood approach to registering events that are not yet aligned. That is, we find transformations of the observed events that make them as likely as possible under our model. In particular we extract the camera rotation that leads to the best event alignment. We show new state of the art accuracy for rotational velocity estimation on the DAVIS 240C dataset. In addition, our method is also faster and has lower computational complexity than several competing methods.
A modular framework for object-based saccadic decisions in dynamic scenes
Jun 10, 2021

Visually exploring the world around us is not a passive process. Instead, we actively explore the world and acquire visual information over time. Here, we present a new model for simulating human eye-movement behavior in dynamic real-world scenes. We model this active scene exploration as a sequential decision making process. We adapt the popular drift-diffusion model (DDM) for perceptual decision making and extend it towards multiple options, defined by objects present in the scene. For each possible choice, the model integrates evidence over time and a decision (saccadic eye movement) is triggered as soon as evidence crosses a decision threshold. Drawing this explicit connection between decision making and object-based scene perception is highly relevant in the context of active viewing, where decisions are made continuously while interacting with an external environment. We validate our model with a carefully designed ablation study and explore influences of our model parameters. A comparison on the VidCom dataset supports the plausibility of the proposed approach.
A Detailed Rubric for Motion Segmentation
Oct 31, 2016



Motion segmentation is currently an active area of research in computer Vision. The task of comparing different methods of motion segmentation is complicated by the fact that researchers may use subtly different definitions of the problem. Questions such as "Which objects are moving?", "What is background?", and "How can we use motion of the camera to segment objects, whether they are static or moving?" are clearly related to each other, but lead to different algorithms, and imply different versions of the ground truth. This report has two goals. The first is to offer a precise definition of motion segmentation so that the intent of an algorithm is as well-defined as possible. The second is to report on new versions of three previously existing data sets that are compatible with this definition. We hope that this more detailed definition, and the three data sets that go with it, will allow more meaningful comparisons of certain motion segmentation methods.
It's Moving! A Probabilistic Model for Causal Motion Segmentation in Moving Camera Videos
Apr 01, 2016
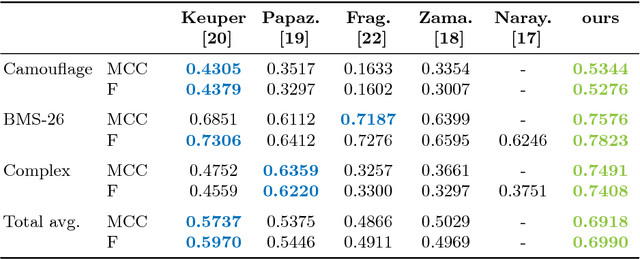

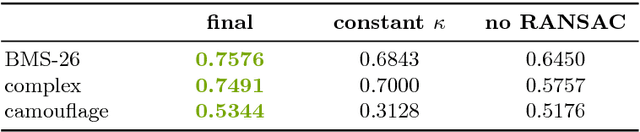
The human ability to detect and segment moving objects works in the presence of multiple objects, complex background geometry, motion of the observer, and even camouflage. In addition to all of this, the ability to detect motion is nearly instantaneous. While there has been much recent progress in motion segmentation, it still appears we are far from human capabilities. In this work, we derive from first principles a new likelihood function for assessing the probability of an optical flow vector given the 3D motion direction of an object. This likelihood uses a novel combination of the angle and magnitude of the optical flow to maximize the information about the true motions of objects. Using this new likelihood and several innovations in initialization, we develop a motion segmentation algorithm that beats current state-of-the-art methods by a large margin. We compare to five state-of-the-art methods on two established benchmarks, and a third new data set of camouflaged animals, which we introduce to push motion segmentation to the next level.