 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical FP4 Training for Large-Scale MoE Models on Hopper GPUs
Mar 03, 2026Training large-scale Mixture-of-Experts (MoE) models is bottlenecked by activation memory and expert-parallel communication, yet FP4 training remains impractical on Hopper-class GPUs without native MXFP4 or NVFP4 support. In this work, we present a training recipe that enables MXFP4 efficiency for MoE models on Hopper architectures without native 4-bit computation support. A central challenge is to integrate FP4 into an existing BF16/FP8 hybrid training pipeline without incurring costly precision round-trips (e.g., FP4 $\leftrightarrow$ BF16 $\leftrightarrow$ FP8). We address this challenge by introducing direct FP8-to-FP4 quantization and de-quantization, together with scaling-aware FP4 row-wise to column-wise conversion, enabling FP4 activations and expert-parallel communication with minimal overhead. Core MoE computations are executed in FP8, while activations and expert-parallel communication are compressed using MXFP4, achieving substantial memory and bandwidth savings without degrading convergence. At the 671B parameter scale, our method achieves end-to-end training performance comparable to strong FP8 baselines, while reducing peak activation memory by 14.8\% (11.8 GB) and improving training throughput by 12.5\%, from 1157 to 1302 tokens per GPU per second. These results show that FP4 efficiency can be practically realized for large-scale MoE training through careful software-hardware co-design, even without native FP4 Tensor Core support.
The Spatio-Temporal Poisson Point Process: A Simple Model for the Alignment of Event Camera Data
Jun 13, 2021
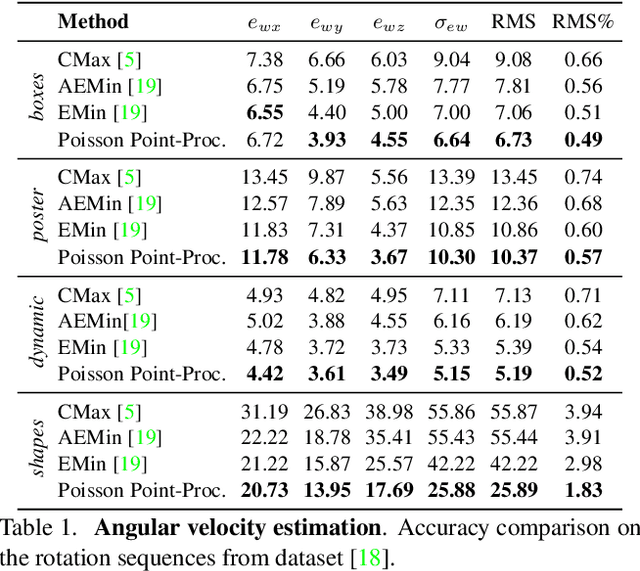
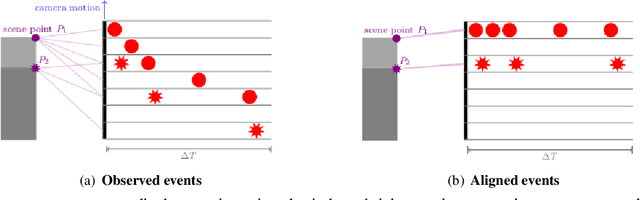
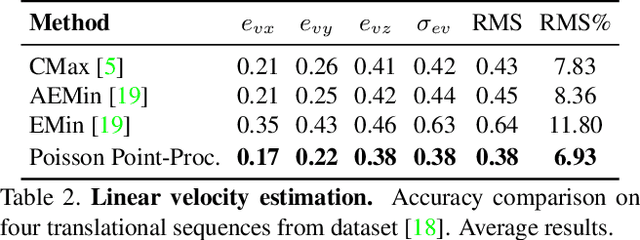
Event cameras, inspired by biological vision systems, provide a natural and data efficient representation of visual information. Visual information is acquired in the form of events that are triggered by local brightness changes. Each pixel location of the camera's sensor records events asynchronously and independently with very high temporal resolution. However, because most brightness changes are triggered by relative motion of the camera and the scene, the events recorded at a single sensor location seldom correspond to the same world point. To extract meaningful information from event cameras, it is helpful to register events that were triggered by the same underlying world point. In this work we propose a new model of event data that captures its natural spatio-temporal structure. We start by developing a model for aligned event data. That is, we develop a model for the data as though it has been perfectly registered already. In particular, we model the aligned data as a spatio-temporal Poisson point process. Based on this model, we develop a maximum likelihood approach to registering events that are not yet aligned. That is, we find transformations of the observed events that make them as likely as possible under our model. In particular we extract the camera rotation that leads to the best event alignment. We show new state of the art accuracy for rotational velocity estimation on the DAVIS 240C dataset. In addition, our method is also faster and has lower computational complexity than several competing methods.
Complementing Representation Deficiency in Few-shot Image Classification: A Meta-Learning Approach
Jul 21, 2020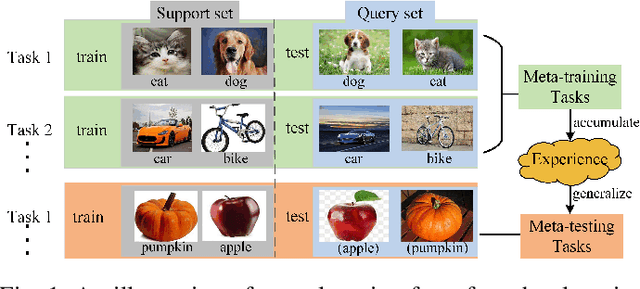
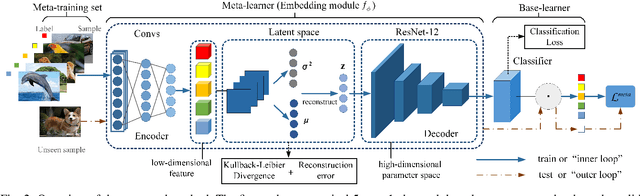
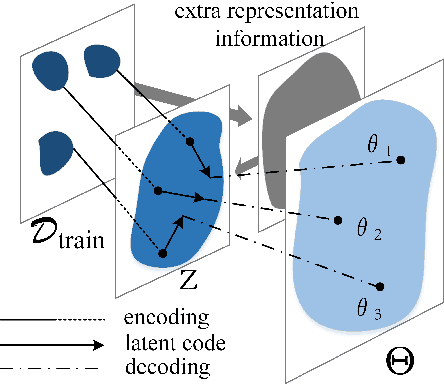
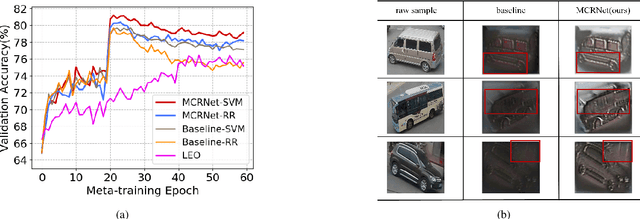
Few-shot learning is a challenging problem that has attracted more and more attention recently since abundant training samples are difficult to obtain in practical applications. Meta-learning has been proposed to address this issue, which focuses on quickly adapting a predictor as a base-learner to new tasks, given limited labeled samples. However, a critical challenge for meta-learning is the representation deficiency since it is hard to discover common information from a small number of training samples or even one, as is the representation of key features from such little information. As a result, a meta-learner cannot be trained well in a high-dimensional parameter space to generalize to new tasks. Existing methods mostly resort to extracting less expressive features so as to avoid the representation deficiency. Aiming at learning better representations, we propose a meta-learning approach with complemented representations network (MCRNet) for few-shot image classification. In particular, we embed a latent space, where latent codes are reconstructed with extra representation information to complement the representation deficiency. Furthermore, the latent space is established with variational inference, collaborating well with different base-learners, and can be extended to other models. Finally, our end-to-end framework achieves the state-of-the-art performance in image classification on three standard few-shot learning datasets.