 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDrive: An LLM-Choreographed Multi-Agent World Model with Unified Latent Co-Compression for Multi-View Driving Video Generation
Jun 16, 2026Generative world models for autonomous driving face two unresolved tensions: heterogeneous control injection, where free-form language, HD-maps, trajectories, and camera poses reside in incompatible representational spaces, and post-hoc cross-view fusion, where per-camera latents fail to encode global 3-D geometry. We trace both to a single root cause: the absence of a shared symbolic interlingua aligning language, geometry, and pixels at the latent-token level. We present DRIVE-CHOREO, an LLM-choreographed multi-agent world model that recasts controllable multi-view video generation as latent choreography. Three Qwen2.5-VL agents - a Director parsing user intent into a structured WorldScript, a Cartographer grounding it into spatially-anchored layout tokens, and an Auditor feeding cross-view critiques back as auxiliary supervision - jointly author a single position-aware token sequence. This sequence is co-compressed with the multi-view video via a view-time permutation that enforces inter-camera geometry within the convolutional receptive field of a 3-D VAE. On nuScenes, DRIVE-CHOREO sets new state-of-the-art multi-view consistency and BEV mAP (21.6) with competitive FVD (45.7); a detector trained purely on our synthetic data gains +2.4 NDS on the real validation split, validating downstream utility.
A Subabdominal MRI Image Segmentation Algorithm Based on Multi-Scale Feature Pyramid Network and Dual Attention Mechanism
May 19, 2023This study aimed to solve the semantic gap and misalignment issue between encoding and decoding because of multiple convolutional and pooling operations in U-Net when segmenting subabdominal MRI images during rectal cancer treatment. A MRI Image Segmentation is proposed based on a multi-scale feature pyramid network and dual attention mechanism. Our innovation is the design of two modules: 1) a dilated convolution and multi-scale feature pyramid network are used in the encoding to avoid the semantic gap. 2) a dual attention mechanism is designed to maintain spatial information of U-Net and reduce misalignment. Experiments on a subabdominal MRI image dataset show the proposed method achieves better performance than others methods. In conclusion, a multi-scale feature pyramid network can reduce the semantic gap, and the dual attention mechanism can make an alignment of features between encoding and decoding.
Refined Semantic Enhancement towards Frequency Diffusion for Video Captioning
Dec 18, 2022



Video captioning aims to generate natural language sentences that describe the given video accurately. Existing methods obtain favorable generation by exploring richer visual representations in encode phase or improving the decoding ability. However, the long-tailed problem hinders these attempts at low-frequency tokens, which rarely occur but carry critical semantics, playing a vital role in the detailed generation. In this paper, we introduce a novel Refined Semantic enhancement method towards Frequency Diffusion (RSFD), a captioning model that constantly perceives the linguistic representation of the infrequent tokens. Concretely, a Frequency-Aware Diffusion (FAD) module is proposed to comprehend the semantics of low-frequency tokens to break through generation limitations. In this way, the caption is refined by promoting the absorption of tokens with insufficient occurrence. Based on FAD, we design a Divergent Semantic Supervisor (DSS) module to compensate for the information loss of high-frequency tokens brought by the diffusion process, where the semantics of low-frequency tokens is further emphasized to alleviate the long-tailed problem. Extensive experiments indicate that RSFD outperforms the state-of-the-art methods on two benchmark datasets, i.e., MSR-VTT and MSVD, demonstrate that the enhancement of low-frequency tokens semantics can obtain a competitive generation effect. Code is available at https://github.com/lzp870/RSFD.
Visual-aware Attention Dual-stream Decoder for Video Captioning
Oct 16, 2021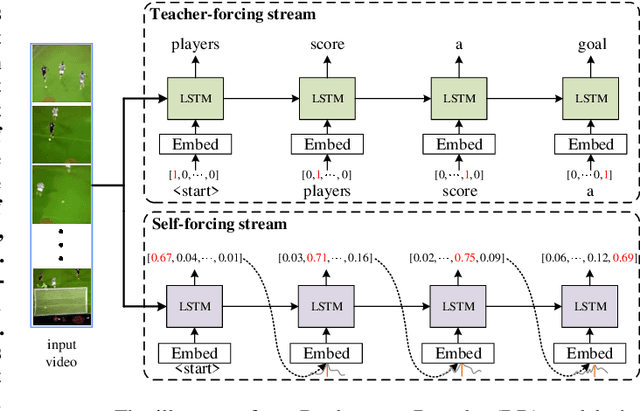
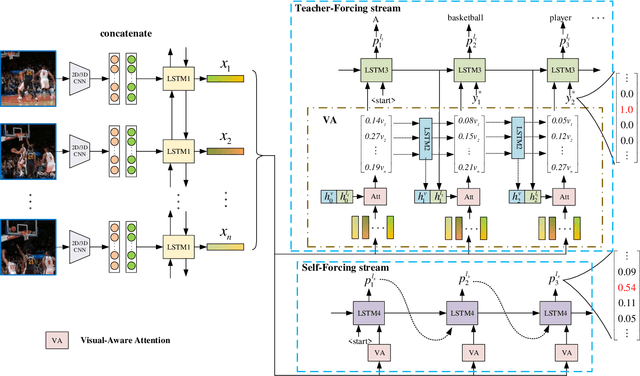
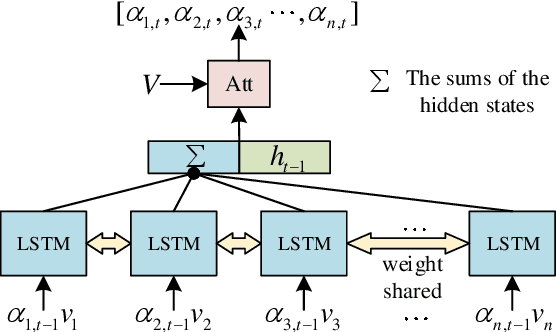
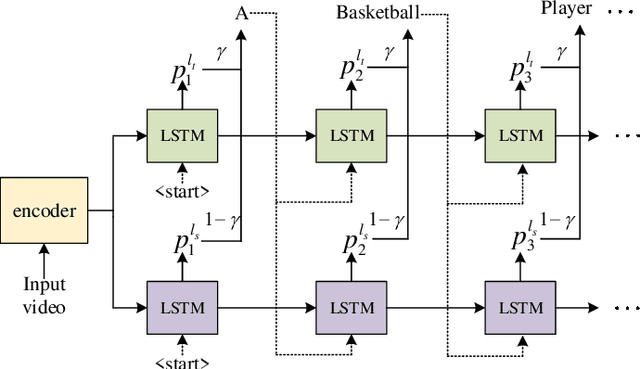
Video captioning is a challenging task that captures different visual parts and describes them in sentences, for it requires visual and linguistic coherence. The attention mechanism in the current video captioning method learns to assign weight to each frame, promoting the decoder dynamically. This may not explicitly model the correlation and the temporal coherence of the visual features extracted in the sequence frames.To generate semantically coherent sentences, we propose a new Visual-aware Attention (VA) model, which concatenates dynamic changes of temporal sequence frames with the words at the previous moment, as the input of attention mechanism to extract sequence features.In addition, the prevalent approaches widely use the teacher-forcing (TF) learning during training, where the next token is generated conditioned on the previous ground-truth tokens. The semantic information in the previously generated tokens is lost. Therefore, we design a self-forcing (SF) stream that takes the semantic information in the probability distribution of the previous token as input to enhance the current token.The Dual-stream Decoder (DD) architecture unifies the TF and SF streams, generating sentences to promote the annotated captioning for both streams.Meanwhile, with the Dual-stream Decoder utilized, the exposure bias problem is alleviated, caused by the discrepancy between the training and testing in the TF learning.The effectiveness of the proposed Visual-aware Attention Dual-stream Decoder (VADD) is demonstrated through the result of experimental studies on Microsoft video description (MSVD) corpus and MSR-Video to text (MSR-VTT) datasets.
Complementing Representation Deficiency in Few-shot Image Classification: A Meta-Learning Approach
Jul 21, 2020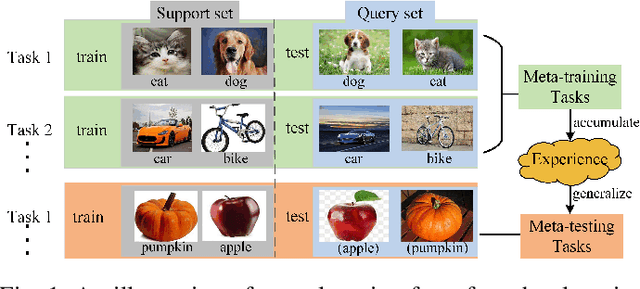
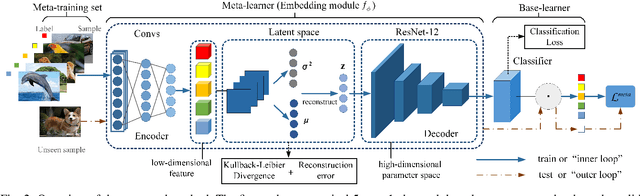
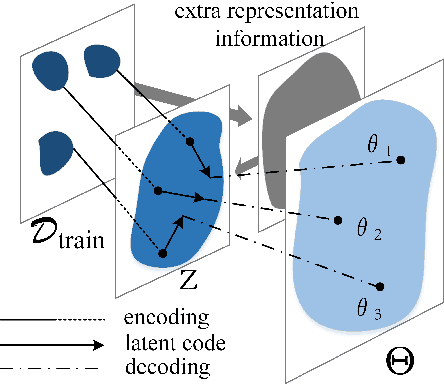
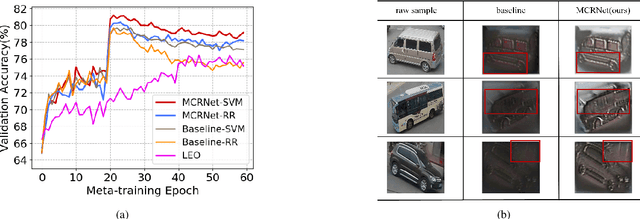
Few-shot learning is a challenging problem that has attracted more and more attention recently since abundant training samples are difficult to obtain in practical applications. Meta-learning has been proposed to address this issue, which focuses on quickly adapting a predictor as a base-learner to new tasks, given limited labeled samples. However, a critical challenge for meta-learning is the representation deficiency since it is hard to discover common information from a small number of training samples or even one, as is the representation of key features from such little information. As a result, a meta-learner cannot be trained well in a high-dimensional parameter space to generalize to new tasks. Existing methods mostly resort to extracting less expressive features so as to avoid the representation deficiency. Aiming at learning better representations, we propose a meta-learning approach with complemented representations network (MCRNet) for few-shot image classification. In particular, we embed a latent space, where latent codes are reconstructed with extra representation information to complement the representation deficiency. Furthermore, the latent space is established with variational inference, collaborating well with different base-learners, and can be extended to other models. Finally, our end-to-end framework achieves the state-of-the-art performance in image classification on three standard few-shot learning datasets.