 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Structured Pruning Algorithm for Model-based Deep Learning
Nov 03, 2023



There is a growing interest in model-based deep learning (MBDL) for solving imaging inverse problems. MBDL networks can be seen as iterative algorithms that estimate the desired image using a physical measurement model and a learned image prior specified using a convolutional neural net (CNNs). The iterative nature of MBDL networks increases the test-time computational complexity, which limits their applicability in certain large-scale applications. We address this issue by presenting structured pruning algorithm for model-based deep learning (SPADE) as the first structured pruning algorithm for MBDL networks. SPADE reduces the computational complexity of CNNs used within MBDL networks by pruning its non-essential weights. We propose three distinct strategies to fine-tune the pruned MBDL networks to minimize the performance loss. Each fine-tuning strategy has a unique benefit that depends on the presence of a pre-trained model and a high-quality ground truth. We validate SPADE on two distinct inverse problems, namely compressed sensing MRI and image super-resolution. Our results highlight that MBDL models pruned by SPADE can achieve substantial speed up in testing time while maintaining competitive performance.
A Plug-and-Play Image Registration Network
Oct 06, 2023



Deformable image registration (DIR) is an active research topic in biomedical imaging. There is a growing interest in developing DIR methods based on deep learning (DL). A traditional DL approach to DIR is based on training a convolutional neural network (CNN) to estimate the registration field between two input images. While conceptually simple, this approach comes with a limitation that it exclusively relies on a pre-trained CNN without explicitly enforcing fidelity between the registered image and the reference. We present plug-and-play image registration network (PIRATE) as a new DIR method that addresses this issue by integrating an explicit data-fidelity penalty and a CNN prior. PIRATE pre-trains a CNN denoiser on the registration field and "plugs" it into an iterative method as a regularizer. We additionally present PIRATE+ that fine-tunes the CNN prior in PIRATE using deep equilibrium models (DEQ). PIRATE+ interprets the fixed-point iteration of PIRATE as a network with effectively infinite layers and then trains the resulting network end-to-end, enabling it to learn more task-specific information and boosting its performance. Our numerical results on OASIS and CANDI datasets show that our methods achieve state-of-the-art performance on DIR.
Robustness of Deep Equilibrium Architectures to Changes in the Measurement Model
Nov 01, 2022



Deep model-based architectures (DMBAs) are widely used in imaging inverse problems to integrate physical measurement models and learned image priors. Plug-and-play priors (PnP) and deep equilibrium models (DEQ) are two DMBA frameworks that have received significant attention. The key difference between the two is that the image prior in DEQ is trained by using a specific measurement model, while that in PnP is trained as a general image denoiser. This difference is behind a common assumption that PnP is more robust to changes in the measurement models compared to DEQ. This paper investigates the robustness of DEQ priors to changes in the measurement models. Our results on two imaging inverse problems suggest that DEQ priors trained under mismatched measurement models outperform image denoisers.
SINCO: A Novel structural regularizer for image compression using implicit neural representations
Oct 26, 2022Implicit neural representations (INR) have been recently proposed as deep learning (DL) based solutions for image compression. An image can be compressed by training an INR model with fewer weights than the number of image pixels to map the coordinates of the image to corresponding pixel values. While traditional training approaches for INRs are based on enforcing pixel-wise image consistency, we propose to further improve image quality by using a new structural regularizer. We present structural regularization for INR compression (SINCO) as a novel INR method for image compression. SINCO imposes structural consistency of the compressed images to the groundtruth by using a segmentation network to penalize the discrepancy of segmentation masks predicted from compressed images. We validate SINCO on brain MRI images by showing that it can achieve better performance than some recent INR methods.
Visual-aware Attention Dual-stream Decoder for Video Captioning
Oct 16, 2021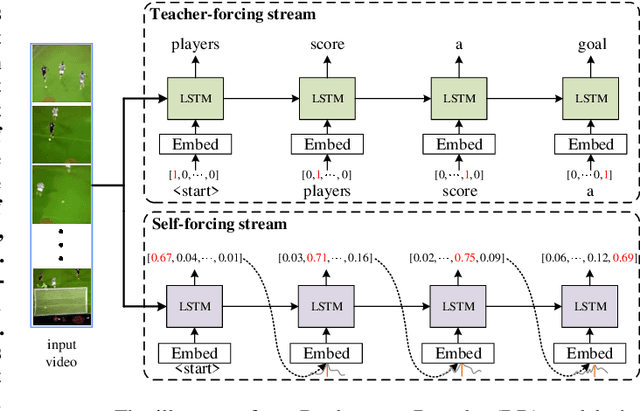
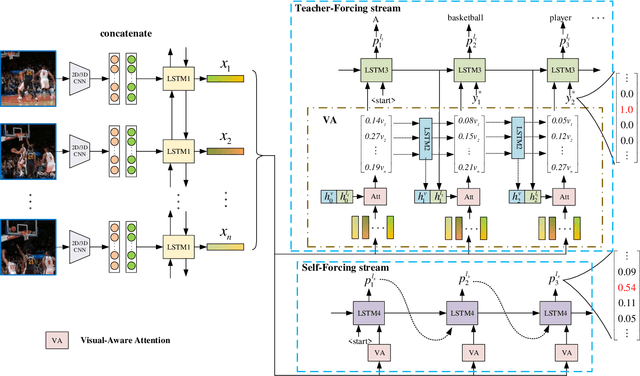
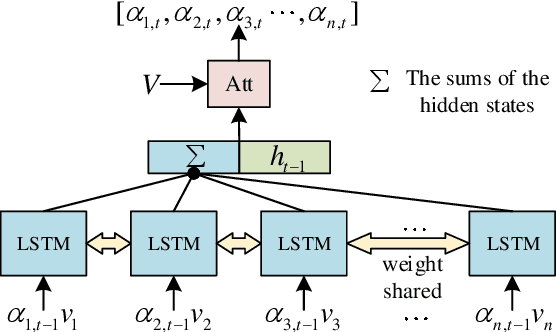
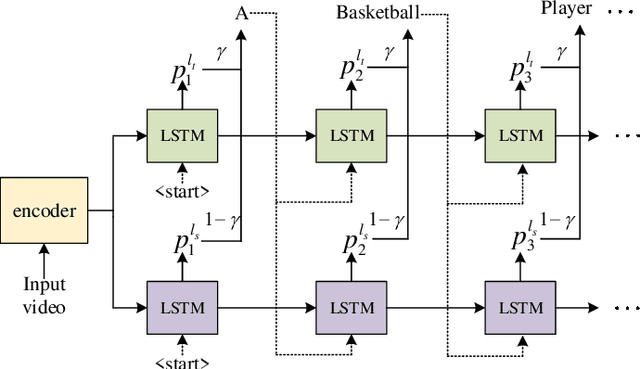
Video captioning is a challenging task that captures different visual parts and describes them in sentences, for it requires visual and linguistic coherence. The attention mechanism in the current video captioning method learns to assign weight to each frame, promoting the decoder dynamically. This may not explicitly model the correlation and the temporal coherence of the visual features extracted in the sequence frames.To generate semantically coherent sentences, we propose a new Visual-aware Attention (VA) model, which concatenates dynamic changes of temporal sequence frames with the words at the previous moment, as the input of attention mechanism to extract sequence features.In addition, the prevalent approaches widely use the teacher-forcing (TF) learning during training, where the next token is generated conditioned on the previous ground-truth tokens. The semantic information in the previously generated tokens is lost. Therefore, we design a self-forcing (SF) stream that takes the semantic information in the probability distribution of the previous token as input to enhance the current token.The Dual-stream Decoder (DD) architecture unifies the TF and SF streams, generating sentences to promote the annotated captioning for both streams.Meanwhile, with the Dual-stream Decoder utilized, the exposure bias problem is alleviated, caused by the discrepancy between the training and testing in the TF learning.The effectiveness of the proposed Visual-aware Attention Dual-stream Decoder (VADD) is demonstrated through the result of experimental studies on Microsoft video description (MSVD) corpus and MSR-Video to text (MSR-VTT) datasets.
VERAM: View-Enhanced Recurrent Attention Model for 3D Shape Classification
Aug 20, 2018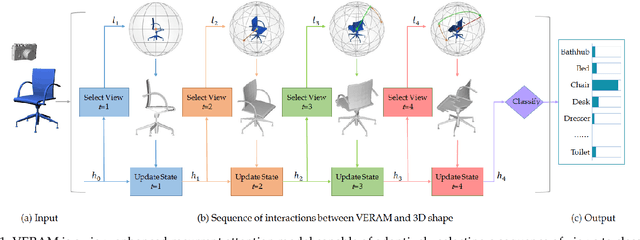
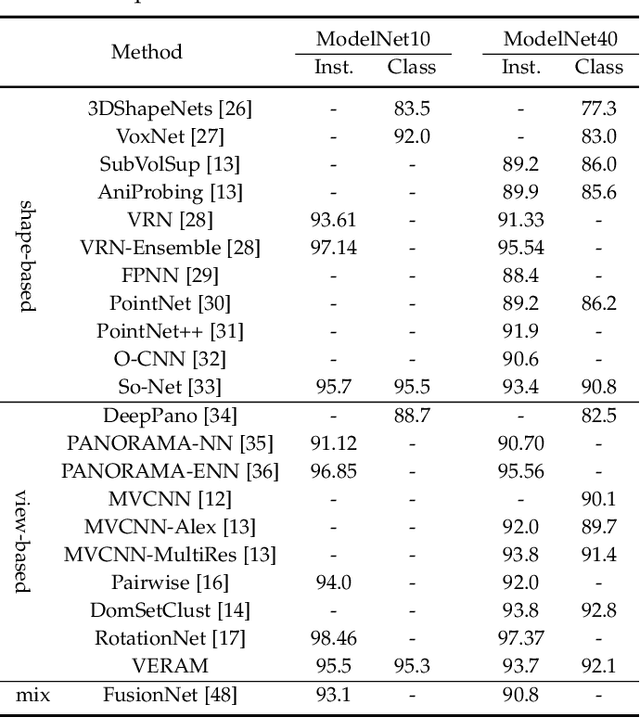
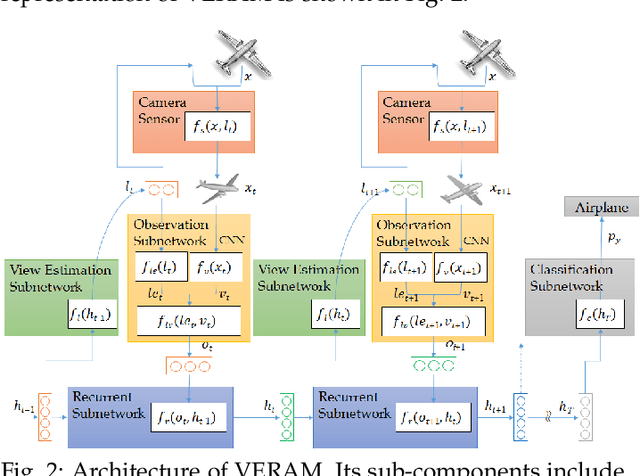
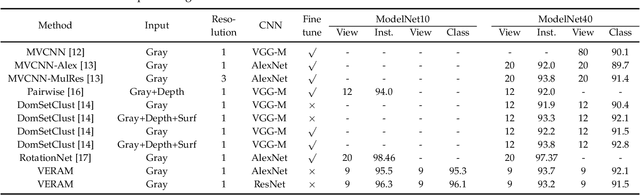
Multi-view deep neural network is perhaps the most successful approach in 3D shape classification. However, the fusion of multi-view features based on max or average pooling lacks a view selection mechanism, limiting its application in, e.g., multi-view active object recognition by a robot. This paper presents VERAM, a recurrent attention model capable of actively selecting a sequence of views for highly accurate 3D shape classification. VERAM addresses an important issue commonly found in existing attention-based models, i.e., the unbalanced training of the subnetworks corresponding to next view estimation and shape classification. The classification subnetwork is easily overfitted while the view estimation one is usually poorly trained, leading to a suboptimal classification performance. This is surmounted by three essential view-enhancement strategies: 1) enhancing the information flow of gradient backpropagation for the view estimation subnetwork, 2) devising a highly informative reward function for the reinforcement training of view estimation and 3) formulating a novel loss function that explicitly circumvents view duplication. Taking grayscale image as input and AlexNet as CNN architecture, VERAM with 9 views achieves instance-level and class-level accuracy of 95:5% and 95:3% on ModelNet10, 93:7% and 92:1% on ModelNet40, both are the state-of-the-art performance under the same number of views.
* Accepted by IEEE Transactions on Visualization and Computer Graphics. Corresponding Author: Kai Xu (kevin.kai.xu@gmail.com)
Tracking Deformable Parts via Dynamic Conditional Random Fields
Oct 30, 2013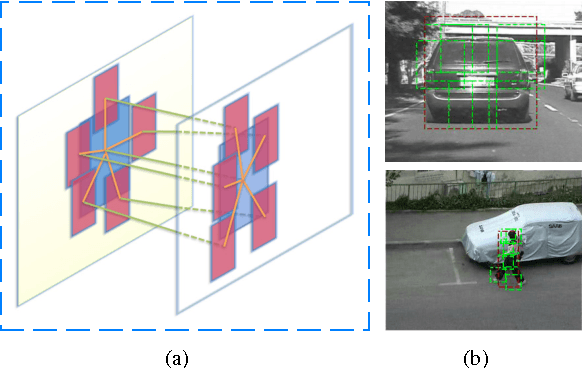

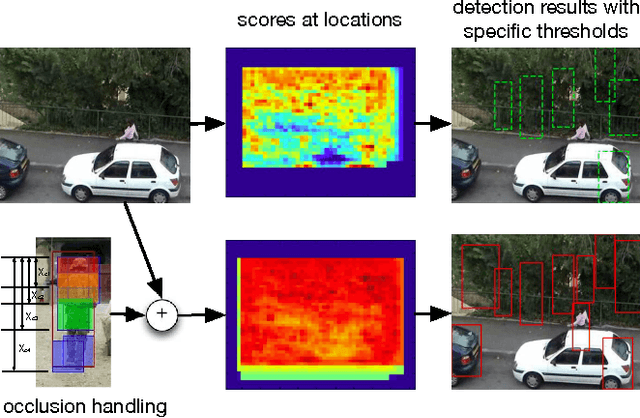
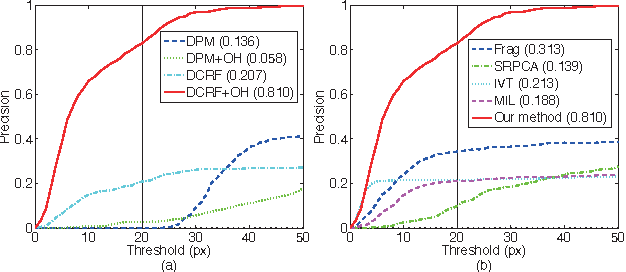
Despite the success of many advanced tracking methods in this area, tracking targets with drastic variation of appearance such as deformation, view change and partial occlusion in video sequences is still a challenge in practical applications. In this letter, we take these serious tracking problems into account simultaneously, proposing a dynamic graph based model to track object and its deformable parts at multiple resolutions. The method introduces well learned structural object detection models into object tracking applications as prior knowledge to deal with deformation and view change. Meanwhile, it explicitly formulates partial occlusion by integrating spatial potentials and temporal potentials with an unparameterized occlusion handling mechanism in the dynamic conditional random field framework. Empirical results demonstrate that the method outperforms state-of-the-art trackers on different challenging video sequences.