 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Instance-Aware Correspondences for Robust Multi-Instance Point Cloud Registration in Cluttered Scenes
Apr 06, 2024Multi-instance point cloud registration estimates the poses of multiple instances of a model point cloud in a scene point cloud. Extracting accurate point correspondence is to the center of the problem. Existing approaches usually treat the scene point cloud as a whole, overlooking the separation of instances. Therefore, point features could be easily polluted by other points from the background or different instances, leading to inaccurate correspondences oblivious to separate instances, especially in cluttered scenes. In this work, we propose MIRETR, Multi-Instance REgistration TRansformer, a coarse-to-fine approach to the extraction of instance-aware correspondences. At the coarse level, it jointly learns instance-aware superpoint features and predicts per-instance masks. With instance masks, the influence from outside of the instance being concerned is minimized, such that highly reliable superpoint correspondences can be extracted. The superpoint correspondences are then extended to instance candidates at the fine level according to the instance masks. At last, an efficient candidate selection and refinement algorithm is devised to obtain the final registrations. Extensive experiments on three public benchmarks demonstrate the efficacy of our approach. In particular, MIRETR outperforms the state of the arts by 16.6 points on F1 score on the challenging ROBI benchmark. Code and models are available at https://github.com/zhiyuanYU134/MIRETR.
6DOF Pose Estimation of a 3D Rigid Object based on Edge-enhanced Point Pair Features
Sep 17, 2022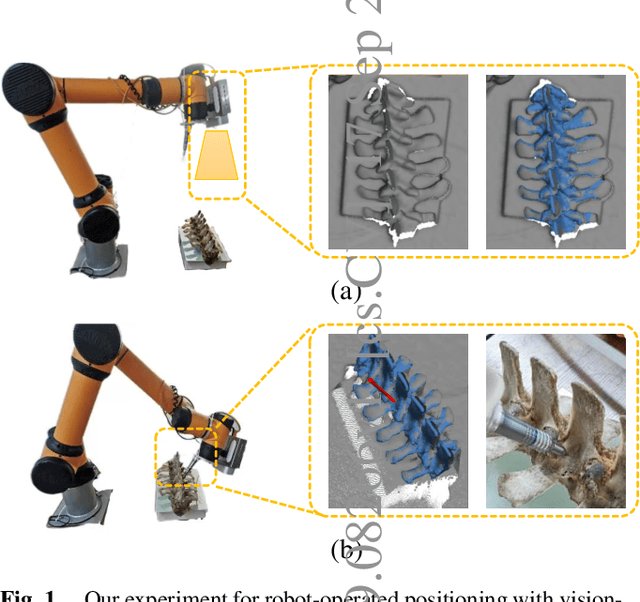
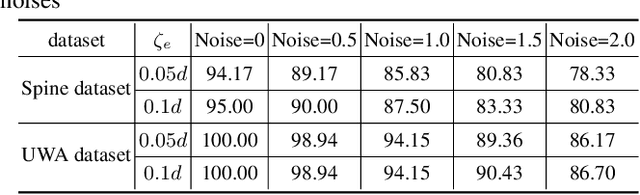
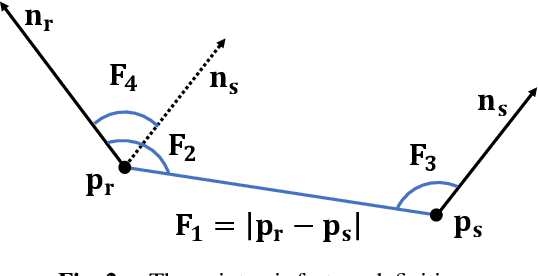
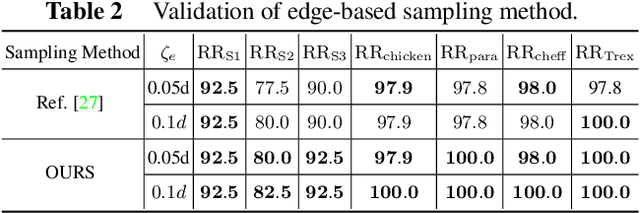
The point pair feature (PPF) is widely used for 6D pose estimation. In this paper, we propose an efficient 6D pose estimation method based on the PPF framework. We introduce a well-targeted down-sampling strategy that focuses more on edge area for efficient feature extraction of complex geometry. A pose hypothesis validation approach is proposed to resolve the symmetric ambiguity by calculating edge matching degree. We perform evaluations on two challenging datasets and one real-world collected dataset, demonstrating the superiority of our method on pose estimation of geometrically complex, occluded, symmetrical objects. We further validate our method by applying it to simulated punctures.
ROSEFusion: Random Optimization for Online Dense Reconstruction under Fast Camera Motion
May 12, 2021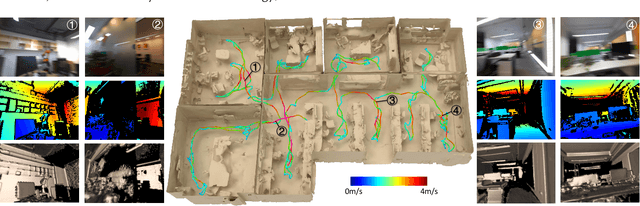
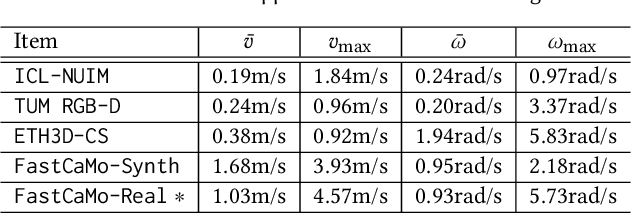
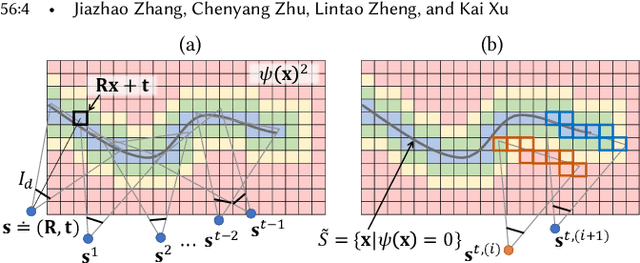
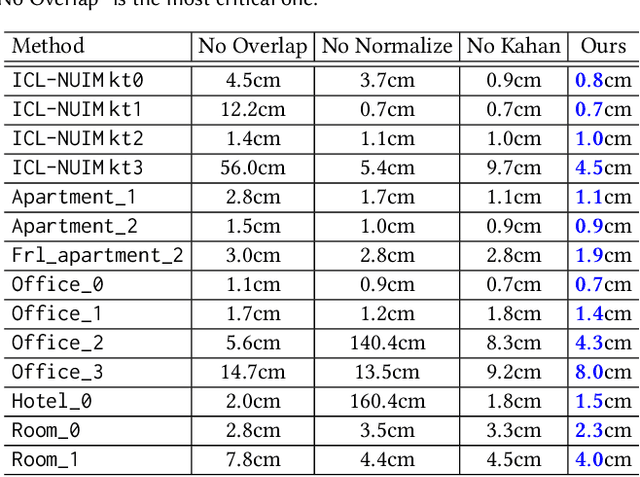
Online reconstruction based on RGB-D sequences has thus far been restrained to relatively slow camera motions (<1m/s). Under very fast camera motion (e.g., 3m/s), the reconstruction can easily crumble even for the state-of-the-art methods. Fast motion brings two challenges to depth fusion: 1) the high nonlinearity of camera pose optimization due to large inter-frame rotations and 2) the lack of reliably trackable features due to motion blur. We propose to tackle the difficulties of fast-motion camera tracking in the absence of inertial measurements using random optimization, in particular, the Particle Filter Optimization (PFO). To surmount the computation-intensive particle sampling and update in standard PFO, we propose to accelerate the randomized search via updating a particle swarm template (PST). PST is a set of particles pre-sampled uniformly within the unit sphere in the 6D space of camera pose. Through moving and rescaling the pre-sampled PST guided by swarm intelligence, our method is able to drive tens of thousands of particles to locate and cover a good local optimum extremely fast and robustly. The particles, representing candidate poses, are evaluated with a fitness function defined based on depth-model conformance. Therefore, our method, being depth-only and correspondence-free, mitigates the motion blur impediment as ToF-based depths are often resilient to motion blur. Thanks to the efficient template-based particle set evolution and the effective fitness function, our method attains good quality pose tracking under fast camera motion (up to 4m/s) in a realtime framerate without including loop closure or global pose optimization. Through extensive evaluations on public datasets of RGB-D sequences, especially on a newly proposed benchmark of fast camera motion, we demonstrate the significant advantage of our method over the state of the arts.
Fusion-Aware Point Convolution for Online Semantic 3D Scene Segmentation
Mar 17, 2020

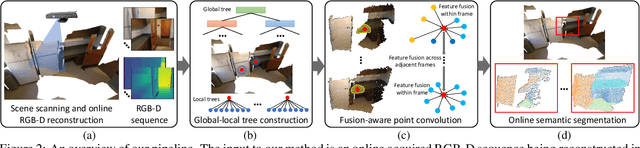
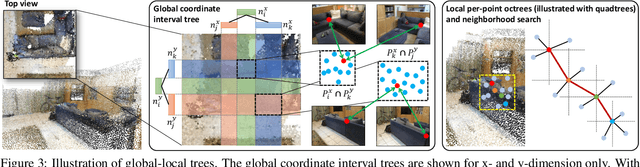
Online semantic 3D segmentation in company with real-time RGB-D reconstruction poses special challenges such as how to perform 3D convolution directly over the progressively fused 3D geometric data, and how to smartly fuse information from frame to frame. We propose a novel fusion-aware 3D point convolution which operates directly on the geometric surface being reconstructed and exploits effectively the inter-frame correlation for high quality 3D feature learning. This is enabled by a dedicated dynamic data structure which organizes the online acquired point cloud with global-local trees. Globally, we compile the online reconstructed 3D points into an incrementally growing coordinate interval tree, enabling fast point insertion and neighborhood query. Locally, we maintain the neighborhood information for each point using an octree whose construction benefits from the fast query of the global tree.Both levels of trees update dynamically and help the 3D convolution effectively exploits the temporal coherence for effective information fusion across RGB-D frames.
Active Scene Understanding via Online Semantic Reconstruction
Jun 18, 2019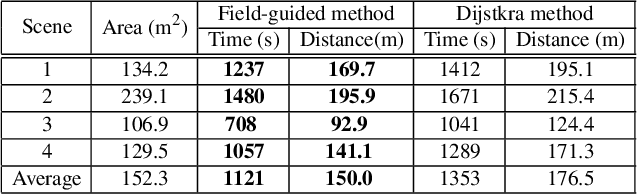

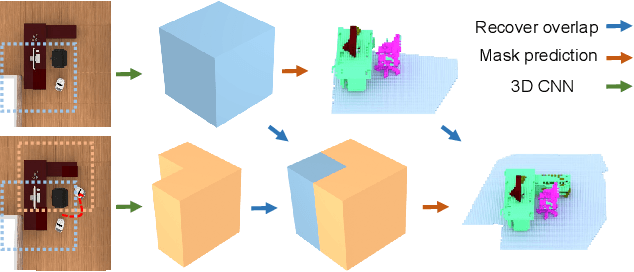
We propose a novel approach to robot-operated active understanding of unknown indoor scenes, based on online RGBD reconstruction with semantic segmentation. In our method, the exploratory robot scanning is both driven by and targeting at the recognition and segmentation of semantic objects from the scene. Our algorithm is built on top of the volumetric depth fusion framework (e.g., KinectFusion) and performs real-time voxel-based semantic labeling over the online reconstructed volume. The robot is guided by an online estimated discrete viewing score field (VSF) parameterized over the 3D space of 2D location and azimuth rotation. VSF stores for each grid the score of the corresponding view, which measures how much it reduces the uncertainty (entropy) of both geometric reconstruction and semantic labeling. Based on VSF, we select the next best views (NBV) as the target for each time step. We then jointly optimize the traverse path and camera trajectory between two adjacent NBVs, through maximizing the integral viewing score (information gain) along path and trajectory. Through extensive evaluation, we show that our method achieves efficient and accurate online scene parsing during exploratory scanning.
Shortest Paths in HSI Space for Color Texture Classification
Apr 16, 2019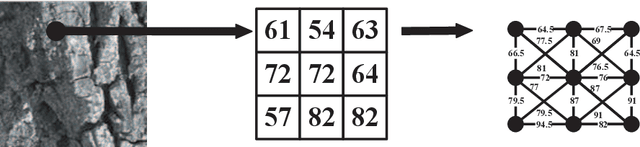

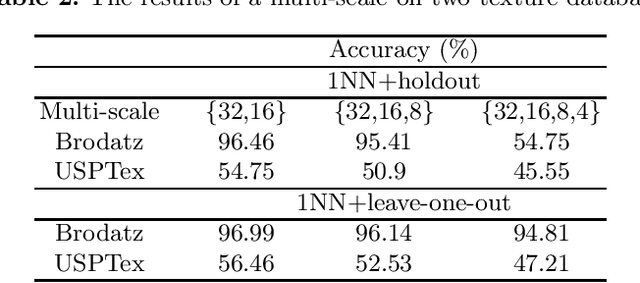

Color texture representation is an important step in the task of texture classification. Shortest paths was used to extract color texture features from RGB and HSV color spaces. In this paper, we propose to use shortest paths in the HSI space to build a texture representation for classification. In particular, two undirected graphs are used to model the H channel and the S and I channels respectively in order to represent a color texture image. Moreover, the shortest paths is constructed by using four pairs of pixels according to different scales and directions of the texture image. Experimental results on colored Brodatz and USPTex databases reveal that our proposed method is effective, and the highest classification accuracy rate is 96.93% in the Brodatz database.
VERAM: View-Enhanced Recurrent Attention Model for 3D Shape Classification
Aug 20, 2018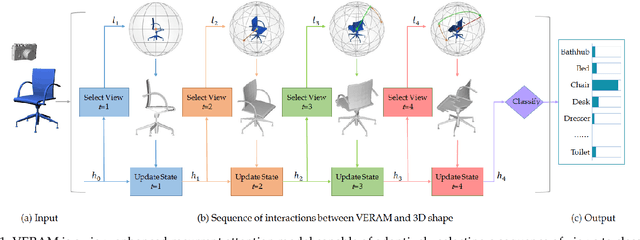
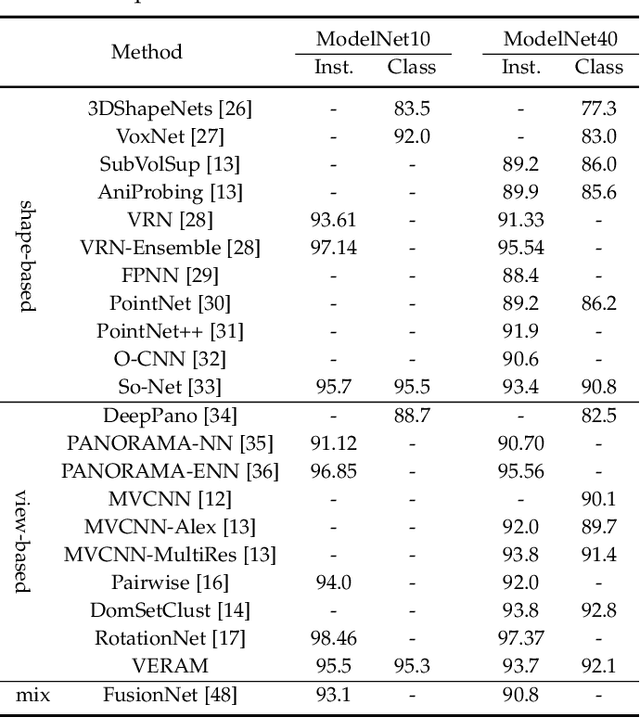
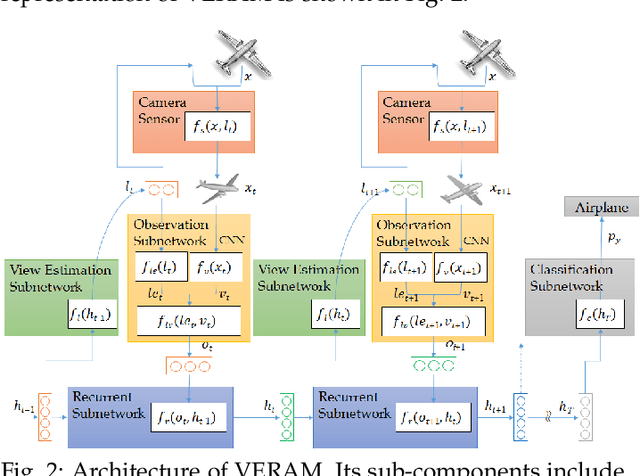
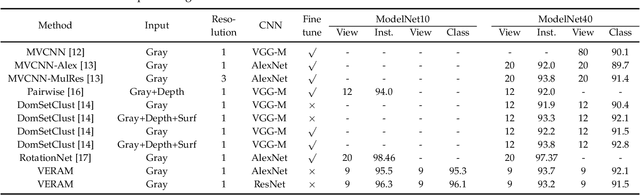
Multi-view deep neural network is perhaps the most successful approach in 3D shape classification. However, the fusion of multi-view features based on max or average pooling lacks a view selection mechanism, limiting its application in, e.g., multi-view active object recognition by a robot. This paper presents VERAM, a recurrent attention model capable of actively selecting a sequence of views for highly accurate 3D shape classification. VERAM addresses an important issue commonly found in existing attention-based models, i.e., the unbalanced training of the subnetworks corresponding to next view estimation and shape classification. The classification subnetwork is easily overfitted while the view estimation one is usually poorly trained, leading to a suboptimal classification performance. This is surmounted by three essential view-enhancement strategies: 1) enhancing the information flow of gradient backpropagation for the view estimation subnetwork, 2) devising a highly informative reward function for the reinforcement training of view estimation and 3) formulating a novel loss function that explicitly circumvents view duplication. Taking grayscale image as input and AlexNet as CNN architecture, VERAM with 9 views achieves instance-level and class-level accuracy of 95:5% and 95:3% on ModelNet10, 93:7% and 92:1% on ModelNet40, both are the state-of-the-art performance under the same number of views.
* Accepted by IEEE Transactions on Visualization and Computer Graphics. Corresponding Author: Kai Xu (kevin.kai.xu@gmail.com)
Recurrent 3D Attentional Networks for End-to-End Active Object Recognition in Cluttered Scenes
Oct 14, 2016



Active vision is inherently attention-driven: The agent selects views of observation to best approach the vision task while improving its internal representation of the scene being observed. Inspired by the recent success of attention-based models in 2D vision tasks based on single RGB images, we propose to address the multi-view depth-based active object recognition using attention mechanism, through developing an end-to-end recurrent 3D attentional network. The architecture comprises of a recurrent neural network (RNN), storing and updating an internal representation, and two levels of spatial transformer units, guiding two-level attentions. Our model, trained with a 3D shape database, is able to iteratively attend to the best views targeting an object of interest for recognizing it, and focus on the object in each view for removing the background clutter. To realize 3D view selection, we derive a 3D spatial transformer network which is differentiable for training with back-propagation, achieving must faster convergence than the reinforcement learning employed by most existing attention-based models. Experiments show that our method outperforms state-of-the-art methods in cluttered scenes.