 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBecomingLit: Relightable Gaussian Avatars with Hybrid Neural Shading
Jun 06, 2025We introduce BecomingLit, a novel method for reconstructing relightable, high-resolution head avatars that can be rendered from novel viewpoints at interactive rates. Therefore, we propose a new low-cost light stage capture setup, tailored specifically towards capturing faces. Using this setup, we collect a novel dataset consisting of diverse multi-view sequences of numerous subjects under varying illumination conditions and facial expressions. By leveraging our new dataset, we introduce a new relightable avatar representation based on 3D Gaussian primitives that we animate with a parametric head model and an expression-dependent dynamics module. We propose a new hybrid neural shading approach, combining a neural diffuse BRDF with an analytical specular term. Our method reconstructs disentangled materials from our dynamic light stage recordings and enables all-frequency relighting of our avatars with both point lights and environment maps. In addition, our avatars can easily be animated and controlled from monocular videos. We validate our approach in extensive experiments on our dataset, where we consistently outperform existing state-of-the-art methods in relighting and reenactment by a significant margin.
GeomHair: Reconstruction of Hair Strands from Colorless 3D Scans
May 08, 2025We propose a novel method that reconstructs hair strands directly from colorless 3D scans by leveraging multi-modal hair orientation extraction. Hair strand reconstruction is a fundamental problem in computer vision and graphics that can be used for high-fidelity digital avatar synthesis, animation, and AR/VR applications. However, accurately recovering hair strands from raw scan data remains challenging due to human hair's complex and fine-grained structure. Existing methods typically rely on RGB captures, which can be sensitive to the environment and can be a challenging domain for extracting the orientation of guiding strands, especially in the case of challenging hairstyles. To reconstruct the hair purely from the observed geometry, our method finds sharp surface features directly on the scan and estimates strand orientation through a neural 2D line detector applied to the renderings of scan shading. Additionally, we incorporate a diffusion prior trained on a diverse set of synthetic hair scans, refined with an improved noise schedule, and adapted to the reconstructed contents via a scan-specific text prompt. We demonstrate that this combination of supervision signals enables accurate reconstruction of both simple and intricate hairstyles without relying on color information. To facilitate further research, we introduce Strands400, the largest publicly available dataset of hair strands with detailed surface geometry extracted from real-world data, which contains reconstructed hair strands from the scans of 400 subjects.
GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion
Dec 13, 2024



We propose a novel approach for reconstructing animatable 3D Gaussian avatars from monocular videos captured by commodity devices like smartphones. Photorealistic 3D head avatar reconstruction from such recordings is challenging due to limited observations, which leaves unobserved regions under-constrained and can lead to artifacts in novel views. To address this problem, we introduce a multi-view head diffusion model, leveraging its priors to fill in missing regions and ensure view consistency in Gaussian splatting renderings. To enable precise viewpoint control, we use normal maps rendered from FLAME-based head reconstruction, which provides pixel-aligned inductive biases. We also condition the diffusion model on VAE features extracted from the input image to preserve details of facial identity and appearance. For Gaussian avatar reconstruction, we distill multi-view diffusion priors by using iteratively denoised images as pseudo-ground truths, effectively mitigating over-saturation issues. To further improve photorealism, we apply latent upsampling to refine the denoised latent before decoding it into an image. We evaluate our method on the NeRSemble dataset, showing that GAF outperforms the previous state-of-the-art methods in novel view synthesis by a 5.34\% higher SSIM score. Furthermore, we demonstrate higher-fidelity avatar reconstructions from monocular videos captured on commodity devices.
HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs
Dec 21, 2023Current advances in human head modeling allow to generate plausible-looking 3D head models via neural representations. Nevertheless, constructing complete high-fidelity head models with explicitly controlled animation remains an issue. Furthermore, completing the head geometry based on a partial observation, e.g. coming from a depth sensor, while preserving details is often problematic for the existing methods. We introduce a generative model for detailed 3D head meshes on top of an articulated 3DMM which allows explicit animation and high-detail preservation at the same time. Our method is trained in two stages. First, we register a parametric head model with vertex displacements to each mesh of the recently introduced NPHM dataset of accurate 3D head scans. The estimated displacements are baked into a hand-crafted UV layout. Second, we train a StyleGAN model in order to generalize over the UV maps of displacements. The decomposition of the parametric model and high-quality vertex displacements allows us to animate the model and modify it semantically. We demonstrate the results of unconditional generation and fitting to the full or partial observation. The project page is available at https://seva100.github.io/headcraft.
DPHMs: Diffusion Parametric Head Models for Depth-based Tracking
Dec 02, 2023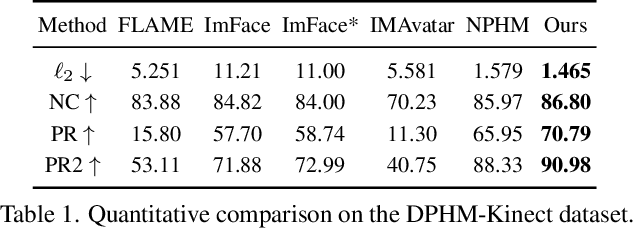
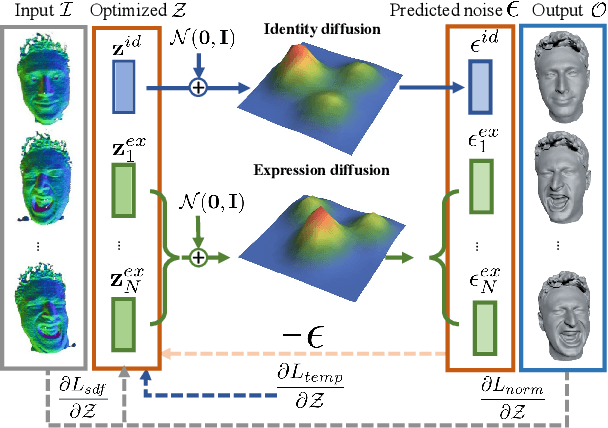
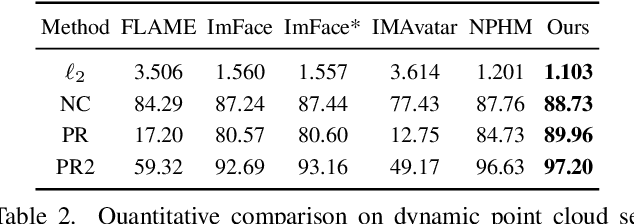

We introduce Diffusion Parametric Head Models (DPHMs), a generative model that enables robust volumetric head reconstruction and tracking from monocular depth sequences. While recent volumetric head models, such as NPHMs, can now excel in representing high-fidelity head geometries, tracking and reconstruction heads from real-world single-view depth sequences remains very challenging, as the fitting to partial and noisy observations is underconstrained. To tackle these challenges, we propose a latent diffusion-based prior to regularize volumetric head reconstruction and tracking. This prior-based regularizer effectively constrains the identity and expression codes to lie on the underlying latent manifold which represents plausible head shapes. To evaluate the effectiveness of the diffusion-based prior, we collect a dataset of monocular Kinect sequences consisting of various complex facial expression motions and rapid transitions. We compare our method to state-of-the-art tracking methods, and demonstrate improved head identity reconstruction as well as robust expression tracking.
Generating Context-Aware Natural Answers for Questions in 3D Scenes
Oct 30, 2023



3D question answering is a young field in 3D vision-language that is yet to be explored. Previous methods are limited to a pre-defined answer space and cannot generate answers naturally. In this work, we pivot the question answering task to a sequence generation task to generate free-form natural answers for questions in 3D scenes (Gen3DQA). To this end, we optimize our model directly on the language rewards to secure the global sentence semantics. Here, we also adapt a pragmatic language understanding reward to further improve the sentence quality. Our method sets a new SOTA on the ScanQA benchmark (CIDEr score 72.22/66.57 on the test sets).
3DShape2VecSet: A 3D Shape Representation for Neural Fields and Generative Diffusion Models
Feb 01, 2023We introduce 3DShape2VecSet, a novel shape representation for neural fields designed for generative diffusion models. Our shape representation can encode 3D shapes given as surface models or point clouds, and represents them as neural fields. The concept of neural fields has previously been combined with a global latent vector, a regular grid of latent vectors, or an irregular grid of latent vectors. Our new representation encodes neural fields on top of a set of vectors. We draw from multiple concepts, such as the radial basis function representation and the cross attention and self-attention function, to design a learnable representation that is especially suitable for processing with transformers. Our results show improved performance in 3D shape encoding and 3D shape generative modeling tasks. We demonstrate a wide variety of generative applications: unconditioned generation, category-conditioned generation, text-conditioned generation, point-cloud completion, and image-conditioned generation.
On the Exploitation of Deepfake Model Recognition
Apr 09, 2022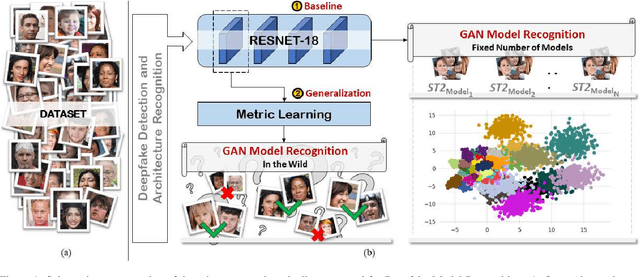


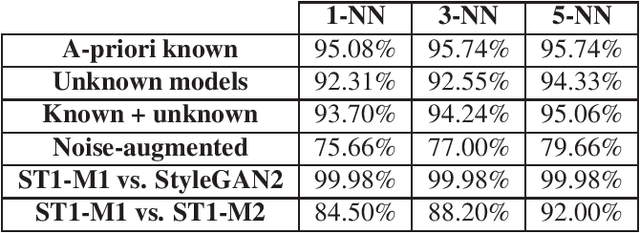
Despite recent advances in Generative Adversarial Networks (GANs), with special focus to the Deepfake phenomenon there is no a clear understanding neither in terms of explainability nor of recognition of the involved models. In particular, the recognition of a specific GAN model that generated the deepfake image compared to many other possible models created by the same generative architecture (e.g. StyleGAN) is a task not yet completely addressed in the state-of-the-art. In this work, a robust processing pipeline to evaluate the possibility to point-out analytic fingerprints for Deepfake model recognition is presented. After exploiting the latent space of 50 slightly different models through an in-depth analysis on the generated images, a proper encoder was trained to discriminate among these models obtaining a classification accuracy of over 96%. Once demonstrated the possibility to discriminate extremely similar images, a dedicated metric exploiting the insights discovered in the latent space was introduced. By achieving a final accuracy of more than 94% for the Model Recognition task on images generated by models not employed in the training phase, this study takes an important step in countering the Deepfake phenomenon introducing a sort of signature in some sense similar to those employed in the multimedia forensics field (e.g. for camera source identification task, image ballistics task, etc).
TAFIM: Targeted Adversarial Attacks against Facial Image Manipulations
Dec 16, 2021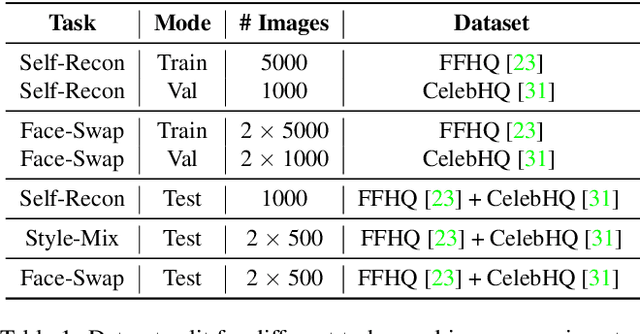
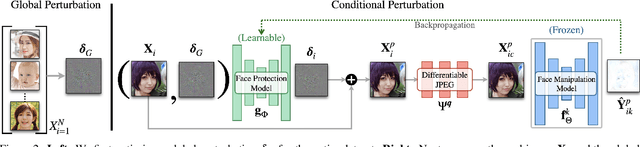
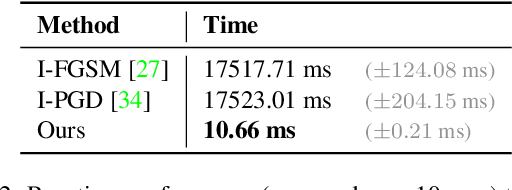
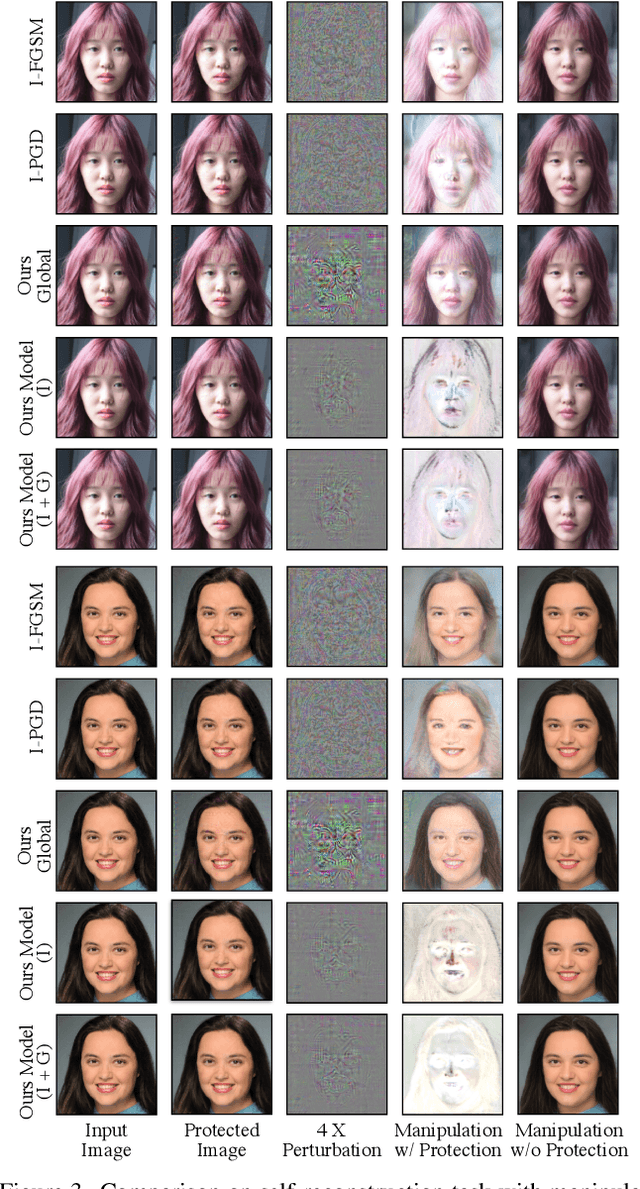
Face image manipulation methods, despite having many beneficial applications in computer graphics, can also raise concerns by affecting an individual's privacy or spreading disinformation. In this work, we propose a proactive defense to prevent face manipulation from happening in the first place. To this end, we introduce a novel data-driven approach that produces image-specific perturbations which are embedded in the original images. The key idea is that these protected images prevent face manipulation by causing the manipulation model to produce a predefined manipulation target (uniformly colored output image in our case) instead of the actual manipulation. Compared to traditional adversarial attacks that optimize noise patterns for each image individually, our generalized model only needs a single forward pass, thus running orders of magnitude faster and allowing for easy integration in image processing stacks, even on resource-constrained devices like smartphones. In addition, we propose to leverage a differentiable compression approximation, hence making generated perturbations robust to common image compression. We further show that a generated perturbation can simultaneously prevent against multiple manipulation methods.
Advances in Neural Rendering
Nov 10, 2021Synthesizing photo-realistic images and videos is at the heart of computer graphics and has been the focus of decades of research. Traditionally, synthetic images of a scene are generated using rendering algorithms such as rasterization or ray tracing, which take specifically defined representations of geometry and material properties as input. Collectively, these inputs define the actual scene and what is rendered, and are referred to as the scene representation (where a scene consists of one or more objects). Example scene representations are triangle meshes with accompanied textures (e.g., created by an artist), point clouds (e.g., from a depth sensor), volumetric grids (e.g., from a CT scan), or implicit surface functions (e.g., truncated signed distance fields). The reconstruction of such a scene representation from observations using differentiable rendering losses is known as inverse graphics or inverse rendering. Neural rendering is closely related, and combines ideas from classical computer graphics and machine learning to create algorithms for synthesizing images from real-world observations. Neural rendering is a leap forward towards the goal of synthesizing photo-realistic image and video content. In recent years, we have seen immense progress in this field through hundreds of publications that show different ways to inject learnable components into the rendering pipeline. This state-of-the-art report on advances in neural rendering focuses on methods that combine classical rendering principles with learned 3D scene representations, often now referred to as neural scene representations. A key advantage of these methods is that they are 3D-consistent by design, enabling applications such as novel viewpoint synthesis of a captured scene. In addition to methods that handle static scenes, we cover neural scene representations for modeling non-rigidly deforming objects...