 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Innovative Tool for Uploading/Scraping Large Image Datasets on Social Networks
Nov 01, 2023Nowadays, people can retrieve and share digital information in an increasingly easy and fast fashion through the well-known digital platforms, including sensitive data, inappropriate or illegal content, and, in general, information that might serve as probative evidence in court. Consequently, to assess forensics issues, we need to figure out how to trace back to the posting chain of a digital evidence (e.g., a picture, an audio) throughout the involved platforms -- this is what Digital (also Forensics) Ballistics basically deals with. With the entry of Machine Learning as a tool of the trade in many research areas, the need for vast amounts of data has been dramatically increasing over the last few years. However, collecting or simply find the "right" datasets that properly enables data-driven research studies can turn out to be not trivial in some cases, if not extremely challenging, especially when it comes with highly specialized tasks, such as creating datasets analyzed to detect the source media platform of a given digital media. In this paper we propose an automated approach by means of a digital tool that we created on purpose. The tool is capable of automatically uploading an entire image dataset to the desired digital platform and then downloading all the uploaded pictures, thus shortening the overall time required to output the final dataset to be analyzed.
Deep Audio Analyzer: a Framework to Industrialize the Research on Audio Forensics
Oct 29, 2023



Deep Audio Analyzer is an open source speech framework that aims to simplify the research and the development process of neural speech processing pipelines, allowing users to conceive, compare and share results in a fast and reproducible way. This paper describes the core architecture designed to support several tasks of common interest in the audio forensics field, showing possibility of creating new tasks thus customizing the framework. By means of Deep Audio Analyzer, forensics examiners (i.e. from Law Enforcement Agencies) and researchers will be able to visualize audio features, easily evaluate performances on pretrained models, to create, export and share new audio analysis workflows by combining deep neural network models with few clicks. One of the advantages of this tool is to speed up research and practical experimentation, in the field of audio forensics analysis thus also improving experimental reproducibility by exporting and sharing pipelines. All features are developed in modules accessible by the user through a Graphic User Interface. Index Terms: Speech Processing, Deep Learning Audio, Deep Learning Audio Pipeline creation, Audio Forensics.
Not with my name! Inferring artists' names of input strings employed by Diffusion Models
Jul 25, 2023
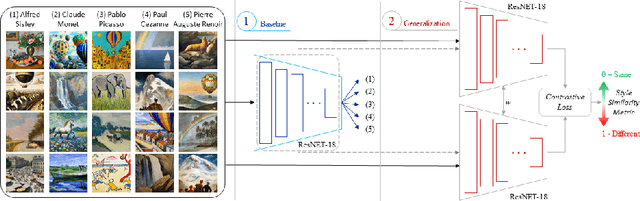
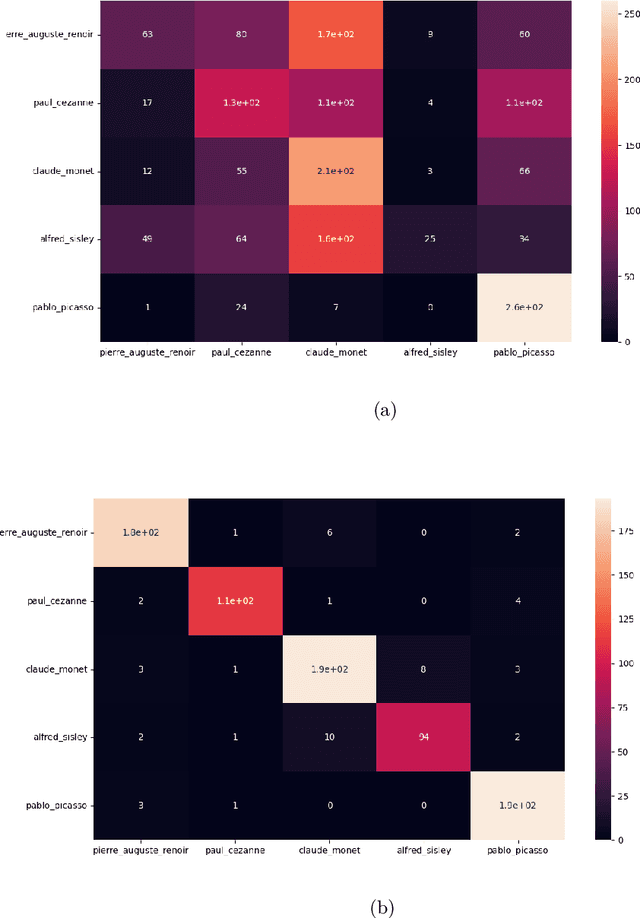
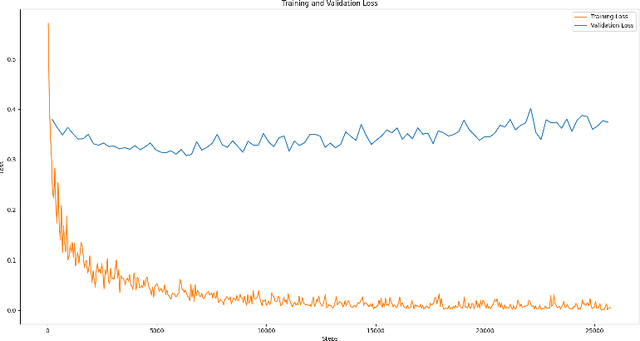
Diffusion Models (DM) are highly effective at generating realistic, high-quality images. However, these models lack creativity and merely compose outputs based on their training data, guided by a textual input provided at creation time. Is it acceptable to generate images reminiscent of an artist, employing his name as input? This imply that if the DM is able to replicate an artist's work then it was trained on some or all of his artworks thus violating copyright. In this paper, a preliminary study to infer the probability of use of an artist's name in the input string of a generated image is presented. To this aim we focused only on images generated by the famous DALL-E 2 and collected images (both original and generated) of five renowned artists. Finally, a dedicated Siamese Neural Network was employed to have a first kind of probability. Experimental results demonstrate that our approach is an optimal starting point and can be employed as a prior for predicting a complete input string of an investigated image. Dataset and code are available at: https://github.com/ictlab-unict/not-with-my-name .
Boosting multiple sclerosis lesion segmentation through attention mechanism
Apr 21, 2023



Magnetic resonance imaging is a fundamental tool to reach a diagnosis of multiple sclerosis and monitoring its progression. Although several attempts have been made to segment multiple sclerosis lesions using artificial intelligence, fully automated analysis is not yet available. State-of-the-art methods rely on slight variations in segmentation architectures (e.g. U-Net, etc.). However, recent research has demonstrated how exploiting temporal-aware features and attention mechanisms can provide a significant boost to traditional architectures. This paper proposes a framework that exploits an augmented U-Net architecture with a convolutional long short-term memory layer and attention mechanism which is able to segment and quantify multiple sclerosis lesions detected in magnetic resonance images. Quantitative and qualitative evaluation on challenging examples demonstrated how the method outperforms previous state-of-the-art approaches, reporting an overall Dice score of 89% and also demonstrating robustness and generalization ability on never seen new test samples of a new dedicated under construction dataset.
Early detection of hip periprosthetic joint infections through CNN on Computed Tomography images
Apr 18, 2023Early detection of an infection prior to prosthesis removal (e.g., hips, knees or other areas) would provide significant benefits to patients. Currently, the detection task is carried out only retrospectively with a limited number of methods relying on biometric or other medical data. The automatic detection of a periprosthetic joint infection from tomography imaging is a task never addressed before. This study introduces a novel method for early detection of the hip prosthesis infections analyzing Computed Tomography images. The proposed solution is based on a novel ResNeSt Convolutional Neural Network architecture trained on samples from more than 100 patients. The solution showed exceptional performance in detecting infections with an experimental high level of accuracy and F-score.
UniCT DMI Solution for 3rd COV19D Competition on COVID-19 Detection through attention-based CNN for CT Scan
Mar 22, 2023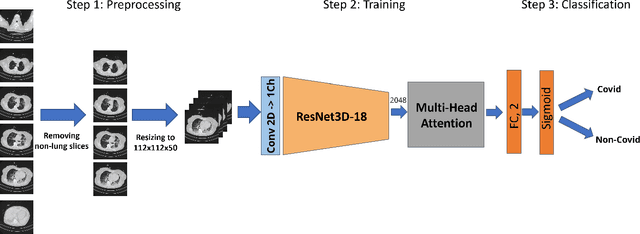
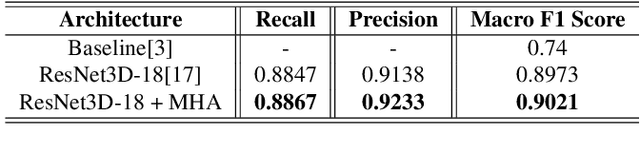
This paper presents our solution for the first challenge of the 3rd Covid-19 competition, which is part of the "AI-enabled Medical Image Analysis Workshop" organized by IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) 2023. Our proposed solution is based on a Resnet as a backbone network with the addition of attention mechanisms. The Resnet provides an effective feature extractor for the classification task, while the attention mechanisms improve the model's ability to focus on important regions of interest within the images. We conducted extensive experiments on the provided dataset and achieved promising results. Our proposed approach has the potential to assist in the accurate diagnosis of Covid-19 from chest computed tomography images, which can aid in the early detection and management of the disease.
Level Up the Deepfake Detection: a Method to Effectively Discriminate Images Generated by GAN Architectures and Diffusion Models
Mar 01, 2023



The image deepfake detection task has been greatly addressed by the scientific community to discriminate real images from those generated by Artificial Intelligence (AI) models: a binary classification task. In this work, the deepfake detection and recognition task was investigated by collecting a dedicated dataset of pristine images and fake ones generated by 9 different Generative Adversarial Network (GAN) architectures and by 4 additional Diffusion Models (DM). A hierarchical multi-level approach was then introduced to solve three different deepfake detection and recognition tasks: (i) Real Vs AI generated; (ii) GANs Vs DMs; (iii) AI specific architecture recognition. Experimental results demonstrated, in each case, more than 97% classification accuracy, outperforming state-of-the-art methods.
On the Exploitation of Deepfake Model Recognition
Apr 09, 2022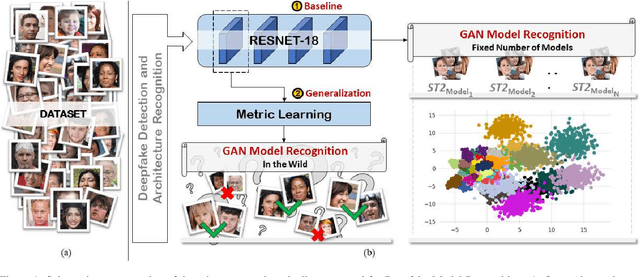


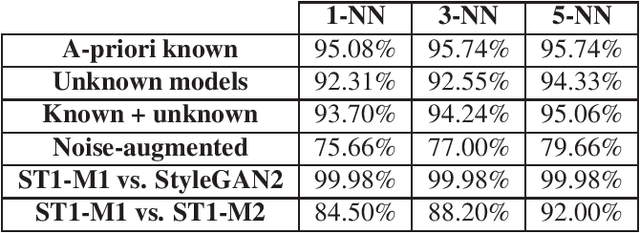
Despite recent advances in Generative Adversarial Networks (GANs), with special focus to the Deepfake phenomenon there is no a clear understanding neither in terms of explainability nor of recognition of the involved models. In particular, the recognition of a specific GAN model that generated the deepfake image compared to many other possible models created by the same generative architecture (e.g. StyleGAN) is a task not yet completely addressed in the state-of-the-art. In this work, a robust processing pipeline to evaluate the possibility to point-out analytic fingerprints for Deepfake model recognition is presented. After exploiting the latent space of 50 slightly different models through an in-depth analysis on the generated images, a proper encoder was trained to discriminate among these models obtaining a classification accuracy of over 96%. Once demonstrated the possibility to discriminate extremely similar images, a dedicated metric exploiting the insights discovered in the latent space was introduced. By achieving a final accuracy of more than 94% for the Model Recognition task on images generated by models not employed in the training phase, this study takes an important step in countering the Deepfake phenomenon introducing a sort of signature in some sense similar to those employed in the multimedia forensics field (e.g. for camera source identification task, image ballistics task, etc).
Deepfake Style Transfer Mixture: a First Forensic Ballistics Study on Synthetic Images
Mar 18, 2022
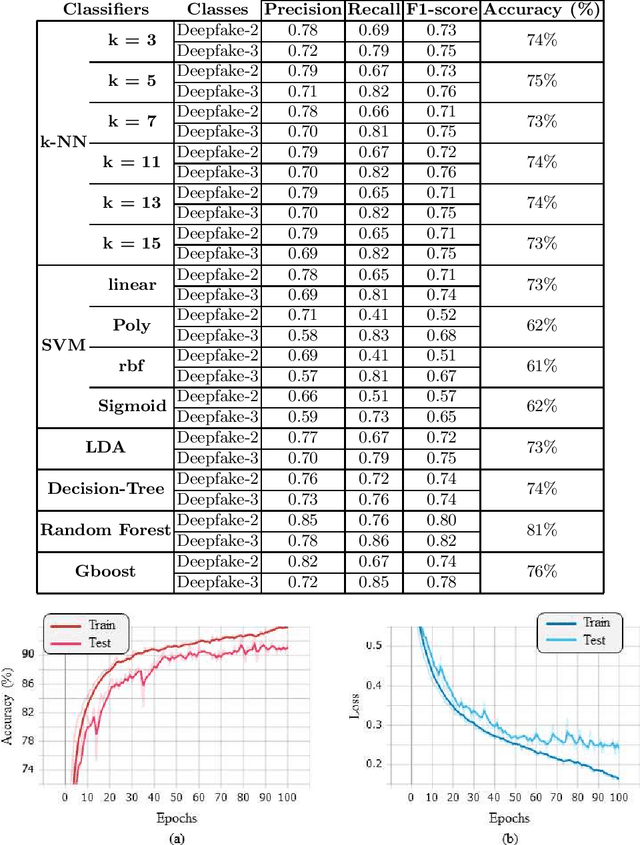

Most recent style-transfer techniques based on generative architectures are able to obtain synthetic multimedia contents, or commonly called deepfakes, with almost no artifacts. Researchers already demonstrated that synthetic images contain patterns that can determine not only if it is a deepfake but also the generative architecture employed to create the image data itself. These traces can be exploited to study problems that have never been addressed in the context of deepfakes. To this aim, in this paper a first approach to investigate the image ballistics on deepfake images subject to style-transfer manipulations is proposed. Specifically, this paper describes a study on detecting how many times a digital image has been processed by a generative architecture for style transfer. Moreover, in order to address and study accurately forensic ballistics on deepfake images, some mathematical properties of style-transfer operations were investigated.
Fighting deepfakes by detecting GAN DCT anomalies
Feb 15, 2021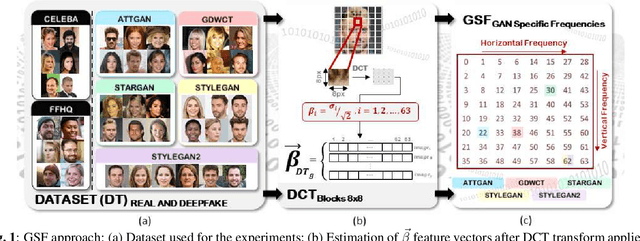


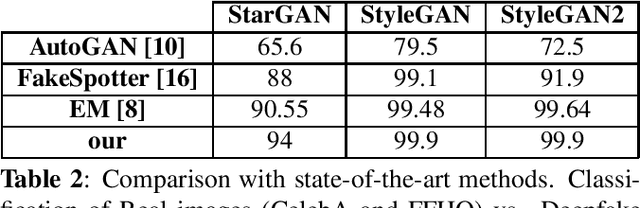
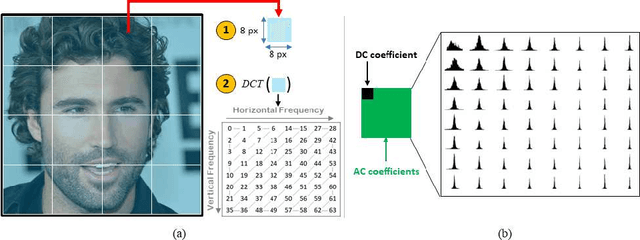
Synthetic multimedia contents created through AI technologies, such as Generative Adversarial Networks (GAN), applied to human faces can have serious social and political consequences. State-of-the-art algorithms employ deep neural networks to detect fake contents but, unfortunately, almost all approaches appear to be neither generalizable nor explainable. In this paper, a new fast detection method able to discriminate Deepfake images with high precision is proposed. By employing Discrete Cosine Transform (DCT), anomalous frequencies in real and Deepfake image datasets were analyzed. The \beta statistics inferred by the distribution of AC coefficients have been the key to recognize GAN-engine generated images. The proposed technique has been validated on pristine high quality images of faces synthesized by different GAN architectures. Experiments carried out show that the method is innovative, exceeds the state-of-the-art and also gives many insights in terms of explainability.