 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePix2NPHM: Learning to Regress NPHM Reconstructions From a Single Image
Dec 19, 2025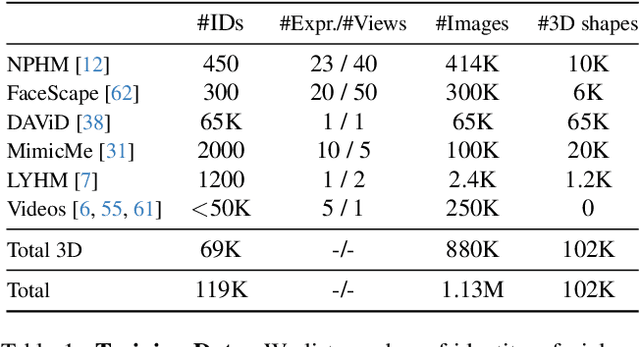

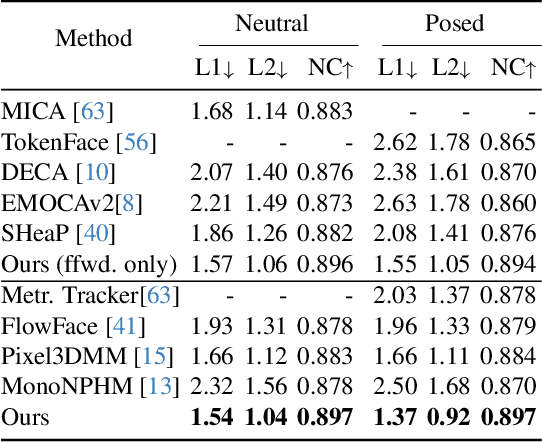
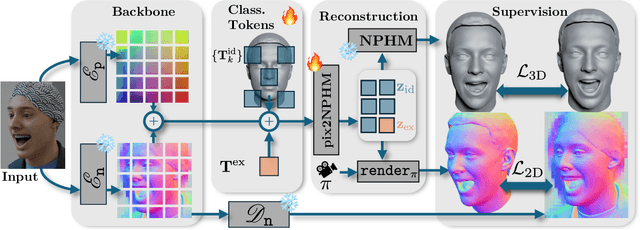
Neural Parametric Head Models (NPHMs) are a recent advancement over mesh-based 3d morphable models (3DMMs) to facilitate high-fidelity geometric detail. However, fitting NPHMs to visual inputs is notoriously challenging due to the expressive nature of their underlying latent space. To this end, we propose Pix2NPHM, a vision transformer (ViT) network that directly regresses NPHM parameters, given a single image as input. Compared to existing approaches, the neural parametric space allows our method to reconstruct more recognizable facial geometry and accurate facial expressions. For broad generalization, we exploit domain-specific ViTs as backbones, which are pretrained on geometric prediction tasks. We train Pix2NPHM on a mixture of 3D data, including a total of over 100K NPHM registrations that enable direct supervision in SDF space, and large-scale 2D video datasets, for which normal estimates serve as pseudo ground truth geometry. Pix2NPHM not only allows for 3D reconstructions at interactive frame rates, it is also possible to improve geometric fidelity by a subsequent inference-time optimization against estimated surface normals and canonical point maps. As a result, we achieve unprecedented face reconstruction quality that can run at scale on in-the-wild data.
FlexAvatar: Learning Complete 3D Head Avatars with Partial Supervision
Dec 17, 2025We introduce FlexAvatar, a method for creating high-quality and complete 3D head avatars from a single image. A core challenge lies in the limited availability of multi-view data and the tendency of monocular training to yield incomplete 3D head reconstructions. We identify the root cause of this issue as the entanglement between driving signal and target viewpoint when learning from monocular videos. To address this, we propose a transformer-based 3D portrait animation model with learnable data source tokens, so-called bias sinks, which enables unified training across monocular and multi-view datasets. This design leverages the strengths of both data sources during inference: strong generalization from monocular data and full 3D completeness from multi-view supervision. Furthermore, our training procedure yields a smooth latent avatar space that facilitates identity interpolation and flexible fitting to an arbitrary number of input observations. In extensive evaluations on single-view, few-shot, and monocular avatar creation tasks, we verify the efficacy of FlexAvatar. Many existing methods struggle with view extrapolation while FlexAvatar generates complete 3D head avatars with realistic facial animations. Website: https://tobias-kirschstein.github.io/flexavatar/
BecomingLit: Relightable Gaussian Avatars with Hybrid Neural Shading
Jun 06, 2025We introduce BecomingLit, a novel method for reconstructing relightable, high-resolution head avatars that can be rendered from novel viewpoints at interactive rates. Therefore, we propose a new low-cost light stage capture setup, tailored specifically towards capturing faces. Using this setup, we collect a novel dataset consisting of diverse multi-view sequences of numerous subjects under varying illumination conditions and facial expressions. By leveraging our new dataset, we introduce a new relightable avatar representation based on 3D Gaussian primitives that we animate with a parametric head model and an expression-dependent dynamics module. We propose a new hybrid neural shading approach, combining a neural diffuse BRDF with an analytical specular term. Our method reconstructs disentangled materials from our dynamic light stage recordings and enables all-frequency relighting of our avatars with both point lights and environment maps. In addition, our avatars can easily be animated and controlled from monocular videos. We validate our approach in extensive experiments on our dataset, where we consistently outperform existing state-of-the-art methods in relighting and reenactment by a significant margin.
Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction
May 01, 2025We address the 3D reconstruction of human faces from a single RGB image. To this end, we propose Pixel3DMM, a set of highly-generalized vision transformers which predict per-pixel geometric cues in order to constrain the optimization of a 3D morphable face model (3DMM). We exploit the latent features of the DINO foundation model, and introduce a tailored surface normal and uv-coordinate prediction head. We train our model by registering three high-quality 3D face datasets against the FLAME mesh topology, which results in a total of over 1,000 identities and 976K images. For 3D face reconstruction, we propose a FLAME fitting opitmization that solves for the 3DMM parameters from the uv-coordinate and normal estimates. To evaluate our method, we introduce a new benchmark for single-image face reconstruction, which features high diversity facial expressions, viewing angles, and ethnicities. Crucially, our benchmark is the first to evaluate both posed and neutral facial geometry. Ultimately, our method outperforms the most competitive baselines by over 15% in terms of geometric accuracy for posed facial expressions.
GGHead: Fast and Generalizable 3D Gaussian Heads
Jun 13, 2024Learning 3D head priors from large 2D image collections is an important step towards high-quality 3D-aware human modeling. A core requirement is an efficient architecture that scales well to large-scale datasets and large image resolutions. Unfortunately, existing 3D GANs struggle to scale to generate samples at high resolutions due to their relatively slow train and render speeds, and typically have to rely on 2D superresolution networks at the expense of global 3D consistency. To address these challenges, we propose Generative Gaussian Heads (GGHead), which adopts the recent 3D Gaussian Splatting representation within a 3D GAN framework. To generate a 3D representation, we employ a powerful 2D CNN generator to predict Gaussian attributes in the UV space of a template head mesh. This way, GGHead exploits the regularity of the template's UV layout, substantially facilitating the challenging task of predicting an unstructured set of 3D Gaussians. We further improve the geometric fidelity of the generated 3D representations with a novel total variation loss on rendered UV coordinates. Intuitively, this regularization encourages that neighboring rendered pixels should stem from neighboring Gaussians in the template's UV space. Taken together, our pipeline can efficiently generate 3D heads trained only from single-view 2D image observations. Our proposed framework matches the quality of existing 3D head GANs on FFHQ while being both substantially faster and fully 3D consistent. As a result, we demonstrate real-time generation and rendering of high-quality 3D-consistent heads at $1024^2$ resolution for the first time.
NPGA: Neural Parametric Gaussian Avatars
May 29, 2024



The creation of high-fidelity, digital versions of human heads is an important stepping stone in the process of further integrating virtual components into our everyday lives. Constructing such avatars is a challenging research problem, due to a high demand for photo-realism and real-time rendering performance. In this work, we propose Neural Parametric Gaussian Avatars (NPGA), a data-driven approach to create high-fidelity, controllable avatars from multi-view video recordings. We build our method around 3D Gaussian Splatting for its highly efficient rendering and to inherit the topological flexibility of point clouds. In contrast to previous work, we condition our avatars' dynamics on the rich expression space of neural parametric head models (NPHM), instead of mesh-based 3DMMs. To this end, we distill the backward deformation field of our underlying NPHM into forward deformations which are compatible with rasterization-based rendering. All remaining fine-scale, expression-dependent details are learned from the multi-view videos. To increase the representational capacity of our avatars, we augment the canonical Gaussian point cloud using per-primitive latent features which govern its dynamic behavior. To regularize this increased dynamic expressivity, we propose Laplacian terms on the latent features and predicted dynamics. We evaluate our method on the public NeRSemble dataset, demonstrating that NPGA significantly outperforms the previous state-of-the-art avatars on the self-reenactment task by 2.6 PSNR. Furthermore, we demonstrate accurate animation capabilities from real-world monocular videos.
HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs
Dec 21, 2023Current advances in human head modeling allow to generate plausible-looking 3D head models via neural representations. Nevertheless, constructing complete high-fidelity head models with explicitly controlled animation remains an issue. Furthermore, completing the head geometry based on a partial observation, e.g. coming from a depth sensor, while preserving details is often problematic for the existing methods. We introduce a generative model for detailed 3D head meshes on top of an articulated 3DMM which allows explicit animation and high-detail preservation at the same time. Our method is trained in two stages. First, we register a parametric head model with vertex displacements to each mesh of the recently introduced NPHM dataset of accurate 3D head scans. The estimated displacements are baked into a hand-crafted UV layout. Second, we train a StyleGAN model in order to generalize over the UV maps of displacements. The decomposition of the parametric model and high-quality vertex displacements allows us to animate the model and modify it semantically. We demonstrate the results of unconditional generation and fitting to the full or partial observation. The project page is available at https://seva100.github.io/headcraft.
MonoNPHM: Dynamic Head Reconstruction from Monocular Videos
Dec 11, 2023



We present Monocular Neural Parametric Head Models (MonoNPHM) for dynamic 3D head reconstructions from monocular RGB videos. To this end, we propose a latent appearance space that parameterizes a texture field on top of a neural parametric model. We constrain predicted color values to be correlated with the underlying geometry such that gradients from RGB effectively influence latent geometry codes during inverse rendering. To increase the representational capacity of our expression space, we augment our backward deformation field with hyper-dimensions, thus improving color and geometry representation in topologically challenging expressions. Using MonoNPHM as a learned prior, we approach the task of 3D head reconstruction using signed distance field based volumetric rendering. By numerically inverting our backward deformation field, we incorporated a landmark loss using facial anchor points that are closely tied to our canonical geometry representation. To evaluate the task of dynamic face reconstruction from monocular RGB videos we record 20 challenging Kinect sequences under casual conditions. MonoNPHM outperforms all baselines with a significant margin, and makes an important step towards easily accessible neural parametric face models through RGB tracking.
GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians
Dec 04, 2023



We introduce GaussianAvatars, a new method to create photorealistic head avatars that are fully controllable in terms of expression, pose, and viewpoint. The core idea is a dynamic 3D representation based on 3D Gaussian splats that are rigged to a parametric morphable face model. This combination facilitates photorealistic rendering while allowing for precise animation control via the underlying parametric model, e.g., through expression transfer from a driving sequence or by manually changing the morphable model parameters. We parameterize each splat by a local coordinate frame of a triangle and optimize for explicit displacement offset to obtain a more accurate geometric representation. During avatar reconstruction, we jointly optimize for the morphable model parameters and Gaussian splat parameters in an end-to-end fashion. We demonstrate the animation capabilities of our photorealistic avatar in several challenging scenarios. For instance, we show reenactments from a driving video, where our method outperforms existing works by a significant margin.
DiffusionAvatars: Deferred Diffusion for High-fidelity 3D Head Avatars
Nov 30, 2023DiffusionAvatars synthesizes a high-fidelity 3D head avatar of a person, offering intuitive control over both pose and expression. We propose a diffusion-based neural renderer that leverages generic 2D priors to produce compelling images of faces. For coarse guidance of the expression and head pose, we render a neural parametric head model (NPHM) from the target viewpoint, which acts as a proxy geometry of the person. Additionally, to enhance the modeling of intricate facial expressions, we condition DiffusionAvatars directly on the expression codes obtained from NPHM via cross-attention. Finally, to synthesize consistent surface details across different viewpoints and expressions, we rig learnable spatial features to the head's surface via TriPlane lookup in NPHM's canonical space. We train DiffusionAvatars on RGB videos and corresponding tracked NPHM meshes of a person and test the obtained avatars in both self-reenactment and animation scenarios. Our experiments demonstrate that DiffusionAvatars generates temporally consistent and visually appealing videos for novel poses and expressions of a person, outperforming existing approaches.