 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeD: Context-Aware Diffusion for Accurate 3D Gaze Estimation
Jan 19, 2026We introduce GazeD, a new 3D gaze estimation method that jointly provides 3D gaze and human pose from a single RGB image. Leveraging the ability of diffusion models to deal with uncertainty, it generates multiple plausible 3D gaze and pose hypotheses based on the 2D context information extracted from the input image. Specifically, we condition the denoising process on the 2D pose, the surroundings of the subject, and the context of the scene. With GazeD we also introduce a novel way of representing the 3D gaze by positioning it as an additional body joint at a fixed distance from the eyes. The rationale is that the gaze is usually closely related to the pose, and thus it can benefit from being jointly denoised during the diffusion process. Evaluations across three benchmark datasets demonstrate that GazeD achieves state-of-the-art performance in 3D gaze estimation, even surpassing methods that rely on temporal information. Project details will be available at https://aimagelab.ing.unimore.it/go/gazed.
Pix2NPHM: Learning to Regress NPHM Reconstructions From a Single Image
Dec 19, 2025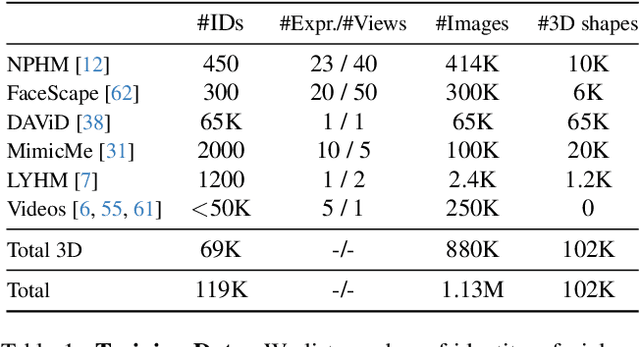

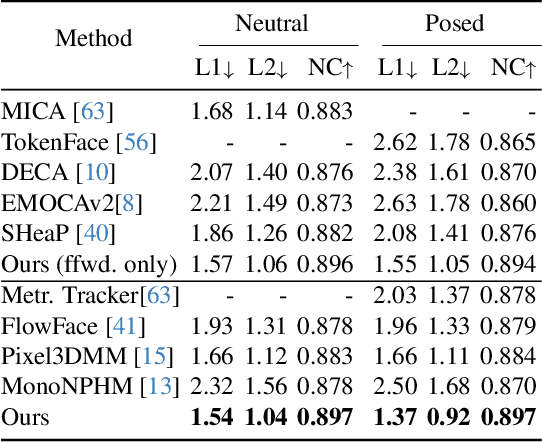
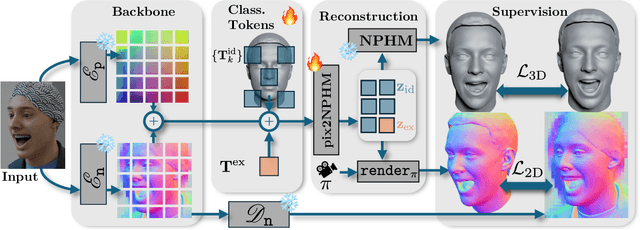
Neural Parametric Head Models (NPHMs) are a recent advancement over mesh-based 3d morphable models (3DMMs) to facilitate high-fidelity geometric detail. However, fitting NPHMs to visual inputs is notoriously challenging due to the expressive nature of their underlying latent space. To this end, we propose Pix2NPHM, a vision transformer (ViT) network that directly regresses NPHM parameters, given a single image as input. Compared to existing approaches, the neural parametric space allows our method to reconstruct more recognizable facial geometry and accurate facial expressions. For broad generalization, we exploit domain-specific ViTs as backbones, which are pretrained on geometric prediction tasks. We train Pix2NPHM on a mixture of 3D data, including a total of over 100K NPHM registrations that enable direct supervision in SDF space, and large-scale 2D video datasets, for which normal estimates serve as pseudo ground truth geometry. Pix2NPHM not only allows for 3D reconstructions at interactive frame rates, it is also possible to improve geometric fidelity by a subsequent inference-time optimization against estimated surface normals and canonical point maps. As a result, we achieve unprecedented face reconstruction quality that can run at scale on in-the-wild data.
SHeaP: Self-Supervised Head Geometry Predictor Learned via 2D Gaussians
Apr 16, 2025Accurate, real-time 3D reconstruction of human heads from monocular images and videos underlies numerous visual applications. As 3D ground truth data is hard to come by at scale, previous methods have sought to learn from abundant 2D videos in a self-supervised manner. Typically, this involves the use of differentiable mesh rendering, which is effective but faces limitations. To improve on this, we propose SHeaP (Self-supervised Head Geometry Predictor Learned via 2D Gaussians). Given a source image, we predict a 3DMM mesh and a set of Gaussians that are rigged to this mesh. We then reanimate this rigged head avatar to match a target frame, and backpropagate photometric losses to both the 3DMM and Gaussian prediction networks. We find that using Gaussians for rendering substantially improves the effectiveness of this self-supervised approach. Training solely on 2D data, our method surpasses existing self-supervised approaches in geometric evaluations on the NoW benchmark for neutral faces and a new benchmark for non-neutral expressions. Our method also produces highly expressive meshes, outperforming state-of-the-art in emotion classification.
GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion
Dec 13, 2024



We propose a novel approach for reconstructing animatable 3D Gaussian avatars from monocular videos captured by commodity devices like smartphones. Photorealistic 3D head avatar reconstruction from such recordings is challenging due to limited observations, which leaves unobserved regions under-constrained and can lead to artifacts in novel views. To address this problem, we introduce a multi-view head diffusion model, leveraging its priors to fill in missing regions and ensure view consistency in Gaussian splatting renderings. To enable precise viewpoint control, we use normal maps rendered from FLAME-based head reconstruction, which provides pixel-aligned inductive biases. We also condition the diffusion model on VAE features extracted from the input image to preserve details of facial identity and appearance. For Gaussian avatar reconstruction, we distill multi-view diffusion priors by using iteratively denoised images as pseudo-ground truths, effectively mitigating over-saturation issues. To further improve photorealism, we apply latent upsampling to refine the denoised latent before decoding it into an image. We evaluate our method on the NeRSemble dataset, showing that GAF outperforms the previous state-of-the-art methods in novel view synthesis by a 5.34\% higher SSIM score. Furthermore, we demonstrate higher-fidelity avatar reconstructions from monocular videos captured on commodity devices.
Depth-based Privileged Information for Boosting 3D Human Pose Estimation on RGB
Sep 17, 2024



Despite the recent advances in computer vision research, estimating the 3D human pose from single RGB images remains a challenging task, as multiple 3D poses can correspond to the same 2D projection on the image. In this context, depth data could help to disambiguate the 2D information by providing additional constraints about the distance between objects in the scene and the camera. Unfortunately, the acquisition of accurate depth data is limited to indoor spaces and usually is tied to specific depth technologies and devices, thus limiting generalization capabilities. In this paper, we propose a method able to leverage the benefits of depth information without compromising its broader applicability and adaptability in a predominantly RGB-camera-centric landscape. Our approach consists of a heatmap-based 3D pose estimator that, leveraging the paradigm of Privileged Information, is able to hallucinate depth information from the RGB frames given at inference time. More precisely, depth information is used exclusively during training by enforcing our RGB-based hallucination network to learn similar features to a backbone pre-trained only on depth data. This approach proves to be effective even when dealing with limited and small datasets. Experimental results reveal that the paradigm of Privileged Information significantly enhances the model's performance, enabling efficient extraction of depth information by using only RGB images.
GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians
Dec 04, 2023



We introduce GaussianAvatars, a new method to create photorealistic head avatars that are fully controllable in terms of expression, pose, and viewpoint. The core idea is a dynamic 3D representation based on 3D Gaussian splats that are rigged to a parametric morphable face model. This combination facilitates photorealistic rendering while allowing for precise animation control via the underlying parametric model, e.g., through expression transfer from a driving sequence or by manually changing the morphable model parameters. We parameterize each splat by a local coordinate frame of a triangle and optimize for explicit displacement offset to obtain a more accurate geometric representation. During avatar reconstruction, we jointly optimize for the morphable model parameters and Gaussian splat parameters in an end-to-end fashion. We demonstrate the animation capabilities of our photorealistic avatar in several challenging scenarios. For instance, we show reenactments from a driving video, where our method outperforms existing works by a significant margin.