 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePix2NPHM: Learning to Regress NPHM Reconstructions From a Single Image
Dec 19, 2025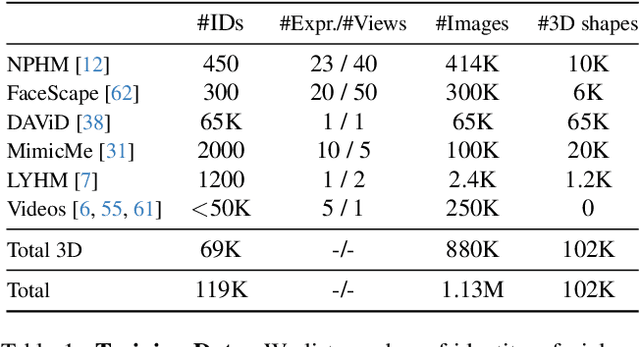

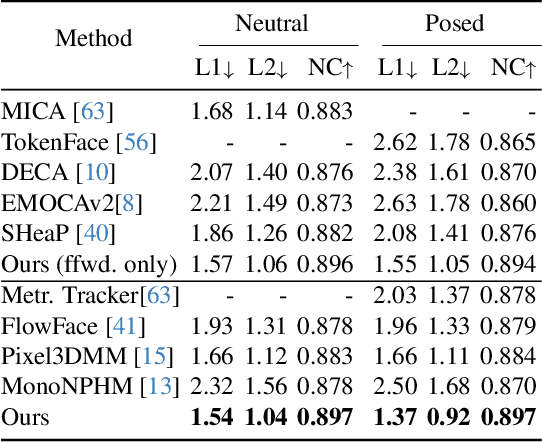
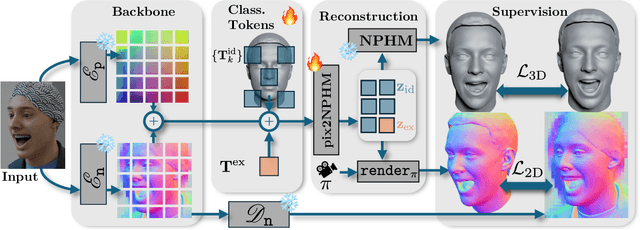
Neural Parametric Head Models (NPHMs) are a recent advancement over mesh-based 3d morphable models (3DMMs) to facilitate high-fidelity geometric detail. However, fitting NPHMs to visual inputs is notoriously challenging due to the expressive nature of their underlying latent space. To this end, we propose Pix2NPHM, a vision transformer (ViT) network that directly regresses NPHM parameters, given a single image as input. Compared to existing approaches, the neural parametric space allows our method to reconstruct more recognizable facial geometry and accurate facial expressions. For broad generalization, we exploit domain-specific ViTs as backbones, which are pretrained on geometric prediction tasks. We train Pix2NPHM on a mixture of 3D data, including a total of over 100K NPHM registrations that enable direct supervision in SDF space, and large-scale 2D video datasets, for which normal estimates serve as pseudo ground truth geometry. Pix2NPHM not only allows for 3D reconstructions at interactive frame rates, it is also possible to improve geometric fidelity by a subsequent inference-time optimization against estimated surface normals and canonical point maps. As a result, we achieve unprecedented face reconstruction quality that can run at scale on in-the-wild data.
SHeaP: Self-Supervised Head Geometry Predictor Learned via 2D Gaussians
Apr 16, 2025Accurate, real-time 3D reconstruction of human heads from monocular images and videos underlies numerous visual applications. As 3D ground truth data is hard to come by at scale, previous methods have sought to learn from abundant 2D videos in a self-supervised manner. Typically, this involves the use of differentiable mesh rendering, which is effective but faces limitations. To improve on this, we propose SHeaP (Self-supervised Head Geometry Predictor Learned via 2D Gaussians). Given a source image, we predict a 3DMM mesh and a set of Gaussians that are rigged to this mesh. We then reanimate this rigged head avatar to match a target frame, and backpropagate photometric losses to both the 3DMM and Gaussian prediction networks. We find that using Gaussians for rendering substantially improves the effectiveness of this self-supervised approach. Training solely on 2D data, our method surpasses existing self-supervised approaches in geometric evaluations on the NoW benchmark for neutral faces and a new benchmark for non-neutral expressions. Our method also produces highly expressive meshes, outperforming state-of-the-art in emotion classification.
GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion
Dec 13, 2024



We propose a novel approach for reconstructing animatable 3D Gaussian avatars from monocular videos captured by commodity devices like smartphones. Photorealistic 3D head avatar reconstruction from such recordings is challenging due to limited observations, which leaves unobserved regions under-constrained and can lead to artifacts in novel views. To address this problem, we introduce a multi-view head diffusion model, leveraging its priors to fill in missing regions and ensure view consistency in Gaussian splatting renderings. To enable precise viewpoint control, we use normal maps rendered from FLAME-based head reconstruction, which provides pixel-aligned inductive biases. We also condition the diffusion model on VAE features extracted from the input image to preserve details of facial identity and appearance. For Gaussian avatar reconstruction, we distill multi-view diffusion priors by using iteratively denoised images as pseudo-ground truths, effectively mitigating over-saturation issues. To further improve photorealism, we apply latent upsampling to refine the denoised latent before decoding it into an image. We evaluate our method on the NeRSemble dataset, showing that GAF outperforms the previous state-of-the-art methods in novel view synthesis by a 5.34\% higher SSIM score. Furthermore, we demonstrate higher-fidelity avatar reconstructions from monocular videos captured on commodity devices.
GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians
Dec 04, 2023



We introduce GaussianAvatars, a new method to create photorealistic head avatars that are fully controllable in terms of expression, pose, and viewpoint. The core idea is a dynamic 3D representation based on 3D Gaussian splats that are rigged to a parametric morphable face model. This combination facilitates photorealistic rendering while allowing for precise animation control via the underlying parametric model, e.g., through expression transfer from a driving sequence or by manually changing the morphable model parameters. We parameterize each splat by a local coordinate frame of a triangle and optimize for explicit displacement offset to obtain a more accurate geometric representation. During avatar reconstruction, we jointly optimize for the morphable model parameters and Gaussian splat parameters in an end-to-end fashion. We demonstrate the animation capabilities of our photorealistic avatar in several challenging scenarios. For instance, we show reenactments from a driving video, where our method outperforms existing works by a significant margin.
Towards a General Deep Feature Extractor for Facial Expression Recognition
Jan 19, 2022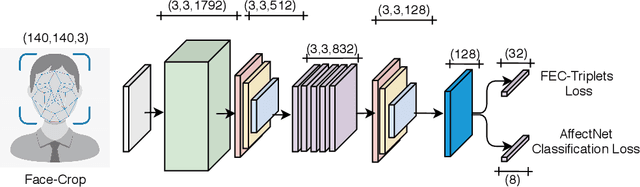



The human face conveys a significant amount of information. Through facial expressions, the face is able to communicate numerous sentiments without the need for verbalisation. Visual emotion recognition has been extensively studied. Recently several end-to-end trained deep neural networks have been proposed for this task. However, such models often lack generalisation ability across datasets. In this paper, we propose the Deep Facial Expression Vector ExtractoR (DeepFEVER), a new deep learning-based approach that learns a visual feature extractor general enough to be applied to any other facial emotion recognition task or dataset. DeepFEVER outperforms state-of-the-art results on the AffectNet and Google Facial Expression Comparison datasets. DeepFEVER's extracted features also generalise extremely well to other datasets -- even those unseen during training -- namely, the Real-World Affective Faces (RAF) dataset.
* Published in: 2021 IEEE International Conference on Image Processing (ICIP). arXiv admin note: text overlap with arXiv:2103.09154
Leveraging Recent Advances in Deep Learning for Audio-Visual Emotion Recognition
Mar 16, 2021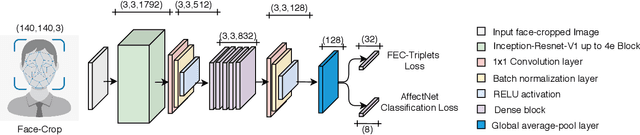
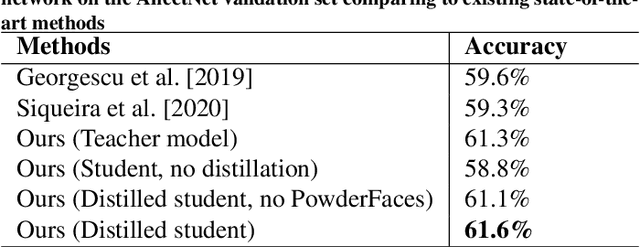
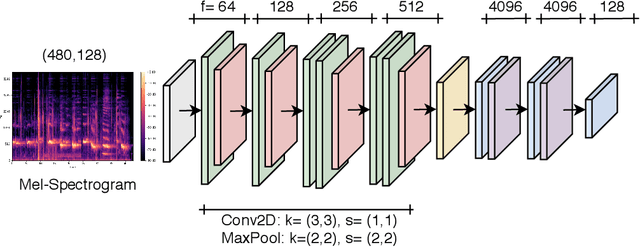
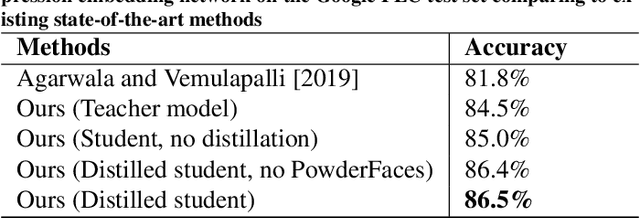
Emotional expressions are the behaviors that communicate our emotional state or attitude to others. They are expressed through verbal and non-verbal communication. Complex human behavior can be understood by studying physical features from multiple modalities; mainly facial, vocal and physical gestures. Recently, spontaneous multi-modal emotion recognition has been extensively studied for human behavior analysis. In this paper, we propose a new deep learning-based approach for audio-visual emotion recognition. Our approach leverages recent advances in deep learning like knowledge distillation and high-performing deep architectures. The deep feature representations of the audio and visual modalities are fused based on a model-level fusion strategy. A recurrent neural network is then used to capture the temporal dynamics. Our proposed approach substantially outperforms state-of-the-art approaches in predicting valence on the RECOLA dataset. Moreover, our proposed visual facial expression feature extraction network outperforms state-of-the-art results on the AffectNet and Google Facial Expression Comparison datasets.