 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark on Monocular Metric Depth Estimation in Wildlife Setting
Oct 06, 2025Camera traps are widely used for wildlife monitoring, but extracting accurate distance measurements from monocular images remains challenging due to the lack of depth information. While monocular depth estimation (MDE) methods have advanced significantly, their performance in natural wildlife environments has not been systematically evaluated. This work introduces the first benchmark for monocular metric depth estimation in wildlife monitoring conditions. We evaluate four state-of-the-art MDE methods (Depth Anything V2, ML Depth Pro, ZoeDepth, and Metric3D) alongside a geometric baseline on 93 camera trap images with ground truth distances obtained using calibrated ChARUCO patterns. Our results demonstrate that Depth Anything V2 achieves the best overall performance with a mean absolute error of 0.454m and correlation of 0.962, while methods like ZoeDepth show significant degradation in outdoor natural environments (MAE: 3.087m). We find that median-based depth extraction consistently outperforms mean-based approaches across all deep learning methods. Additionally, we analyze computational efficiency, with ZoeDepth being fastest (0.17s per image) but least accurate, while Depth Anything V2 provides an optimal balance of accuracy and speed (0.22s per image). This benchmark establishes performance baselines for wildlife applications and provides practical guidance for implementing depth estimation in conservation monitoring systems.
Depth-based Privileged Information for Boosting 3D Human Pose Estimation on RGB
Sep 17, 2024



Despite the recent advances in computer vision research, estimating the 3D human pose from single RGB images remains a challenging task, as multiple 3D poses can correspond to the same 2D projection on the image. In this context, depth data could help to disambiguate the 2D information by providing additional constraints about the distance between objects in the scene and the camera. Unfortunately, the acquisition of accurate depth data is limited to indoor spaces and usually is tied to specific depth technologies and devices, thus limiting generalization capabilities. In this paper, we propose a method able to leverage the benefits of depth information without compromising its broader applicability and adaptability in a predominantly RGB-camera-centric landscape. Our approach consists of a heatmap-based 3D pose estimator that, leveraging the paradigm of Privileged Information, is able to hallucinate depth information from the RGB frames given at inference time. More precisely, depth information is used exclusively during training by enforcing our RGB-based hallucination network to learn similar features to a backbone pre-trained only on depth data. This approach proves to be effective even when dealing with limited and small datasets. Experimental results reveal that the paradigm of Privileged Information significantly enhances the model's performance, enabling efficient extraction of depth information by using only RGB images.
Are CLIP features all you need for Universal Synthetic Image Origin Attribution?
Aug 17, 2024



The steady improvement of Diffusion Models for visual synthesis has given rise to many new and interesting use cases of synthetic images but also has raised concerns about their potential abuse, which poses significant societal threats. To address this, fake images need to be detected and attributed to their source model, and given the frequent release of new generators, realistic applications need to consider an Open-Set scenario where some models are unseen at training time. Existing forensic techniques are either limited to Closed-Set settings or to GAN-generated images, relying on fragile frequency-based "fingerprint" features. By contrast, we propose a simple yet effective framework that incorporates features from large pre-trained foundation models to perform Open-Set origin attribution of synthetic images produced by various generative models, including Diffusion Models. We show that our method leads to remarkable attribution performance, even in the low-data regime, exceeding the performance of existing methods and generalizes better on images obtained from a diverse set of architectures. We make the code publicly available at: https://github.com/ciodar/UniversalAttribution.
Addressing Limitations of State-Aware Imitation Learning for Autonomous Driving
Oct 31, 2023



Conditional Imitation learning is a common and effective approach to train autonomous driving agents. However, two issues limit the full potential of this approach: (i) the inertia problem, a special case of causal confusion where the agent mistakenly correlates low speed with no acceleration, and (ii) low correlation between offline and online performance due to the accumulation of small errors that brings the agent in a previously unseen state. Both issues are critical for state-aware models, yet informing the driving agent of its internal state as well as the state of the environment is of crucial importance. In this paper we propose a multi-task learning agent based on a multi-stage vision transformer with state token propagation. We feed the state of the vehicle along with the representation of the environment as a special token of the transformer and propagate it throughout the network. This allows us to tackle the aforementioned issues from different angles: guiding the driving policy with learned stop/go information, performing data augmentation directly on the state of the vehicle and visually explaining the model's decisions. We report a drastic decrease in inertia and a high correlation between offline and online metrics.
FLODCAST: Flow and Depth Forecasting via Multimodal Recurrent Architectures
Oct 31, 2023


Forecasting motion and spatial positions of objects is of fundamental importance, especially in safety-critical settings such as autonomous driving. In this work, we address the issue by forecasting two different modalities that carry complementary information, namely optical flow and depth. To this end we propose FLODCAST a flow and depth forecasting model that leverages a multitask recurrent architecture, trained to jointly forecast both modalities at once. We stress the importance of training using flows and depth maps together, demonstrating that both tasks improve when the model is informed of the other modality. We train the proposed model to also perform predictions for several timesteps in the future. This provides better supervision and leads to more precise predictions, retaining the capability of the model to yield outputs autoregressively for any future time horizon. We test our model on the challenging Cityscapes dataset, obtaining state of the art results for both flow and depth forecasting. Thanks to the high quality of the generated flows, we also report benefits on the downstream task of segmentation forecasting, injecting our predictions in a flow-based mask-warping framework.
Deepfake detection by exploiting surface anomalies: the SurFake approach
Oct 31, 2023



The ever-increasing use of synthetically generated content in different sectors of our everyday life, one for all media information, poses a strong need for deepfake detection tools in order to avoid the proliferation of altered messages. The process to identify manipulated content, in particular images and videos, is basically performed by looking for the presence of some inconsistencies and/or anomalies specifically due to the fake generation process. Different techniques exist in the scientific literature that exploit diverse ad-hoc features in order to highlight possible modifications. In this paper, we propose to investigate how deepfake creation can impact on the characteristics that the whole scene had at the time of the acquisition. In particular, when an image (video) is captured the overall geometry of the scene (e.g. surfaces) and the acquisition process (e.g. illumination) determine a univocal environment that is directly represented by the image pixel values; all these intrinsic relations are possibly changed by the deepfake generation process. By resorting to the analysis of the characteristics of the surfaces depicted in the image it is possible to obtain a descriptor usable to train a CNN for deepfake detection: we refer to such an approach as SurFake. Experimental results carried out on the FF++ dataset for different kinds of deepfake forgeries and diverse deep learning models confirm that such a feature can be adopted to discriminate between pristine and altered images; furthermore, experiments witness that it can also be combined with visual data to provide a certain improvement in terms of detection accuracy.
DiffDefense: Defending against Adversarial Attacks via Diffusion Models
Sep 07, 2023This paper presents a novel reconstruction method that leverages Diffusion Models to protect machine learning classifiers against adversarial attacks, all without requiring any modifications to the classifiers themselves. The susceptibility of machine learning models to minor input perturbations renders them vulnerable to adversarial attacks. While diffusion-based methods are typically disregarded for adversarial defense due to their slow reverse process, this paper demonstrates that our proposed method offers robustness against adversarial threats while preserving clean accuracy, speed, and plug-and-play compatibility. Code at: https://github.com/HondamunigePrasannaSilva/DiffDefence.
* Paper published at ICIAP23
Robot Pose Nowcasting: Forecast the Future to Improve the Present
Aug 24, 2023



In recent years, the effective and safe collaboration between humans and machines has gained significant importance, particularly in the Industry 4.0 scenario. A critical prerequisite for realizing this collaborative paradigm is precisely understanding the robot's 3D pose within its environment. Therefore, in this paper, we introduce a novel vision-based system leveraging depth data to accurately establish the 3D locations of robotic joints. Specifically, we prove the ability of the proposed system to enhance its current pose estimation accuracy by jointly learning to forecast future poses. Indeed, we introduce the concept of Pose Nowcasting, denoting the capability of a system to exploit the learned knowledge of the future to improve the estimation of the present. The experimental evaluation is conducted on two different datasets, providing state-of-the-art and real-time performance and confirming the validity of the proposed method on both the robotic and human scenarios.
Forecasting Future Instance Segmentation with Learned Optical Flow and Warping
Nov 15, 2022For an autonomous vehicle it is essential to observe the ongoing dynamics of a scene and consequently predict imminent future scenarios to ensure safety to itself and others. This can be done using different sensors and modalities. In this paper we investigate the usage of optical flow for predicting future semantic segmentations. To do so we propose a model that forecasts flow fields autoregressively. Such predictions are then used to guide the inference of a learned warping function that moves instance segmentations on to future frames. Results on the Cityscapes dataset demonstrate the effectiveness of optical-flow methods.
* Paper published as Poster at ICIAP21
Online Deep Clustering with Video Track Consistency
Jun 07, 2022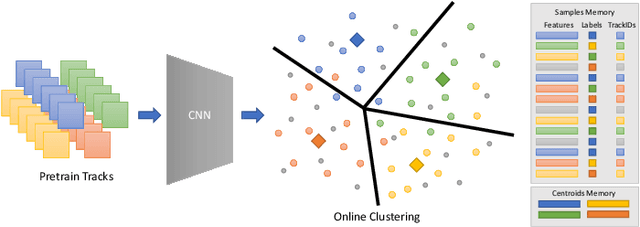



Several unsupervised and self-supervised approaches have been developed in recent years to learn visual features from large-scale unlabeled datasets. Their main drawback however is that these methods are hardly able to recognize visual features of the same object if it is simply rotated or the perspective of the camera changes. To overcome this limitation and at the same time exploit a useful source of supervision, we take into account video object tracks. Following the intuition that two patches in a track should have similar visual representations in a learned feature space, we adopt an unsupervised clustering-based approach and constrain such representations to be labeled as the same category since they likely belong to the same object or object part. Experimental results on two downstream tasks on different datasets demonstrate the effectiveness of our Online Deep Clustering with Video Track Consistency (ODCT) approach compared to prior work, which did not leverage temporal information. In addition we show that exploiting an unsupervised class-agnostic, yet noisy, track generator yields to better accuracy compared to relying on costly and precise track annotations.