 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre CLIP features all you need for Universal Synthetic Image Origin Attribution?
Aug 17, 2024



The steady improvement of Diffusion Models for visual synthesis has given rise to many new and interesting use cases of synthetic images but also has raised concerns about their potential abuse, which poses significant societal threats. To address this, fake images need to be detected and attributed to their source model, and given the frequent release of new generators, realistic applications need to consider an Open-Set scenario where some models are unseen at training time. Existing forensic techniques are either limited to Closed-Set settings or to GAN-generated images, relying on fragile frequency-based "fingerprint" features. By contrast, we propose a simple yet effective framework that incorporates features from large pre-trained foundation models to perform Open-Set origin attribution of synthetic images produced by various generative models, including Diffusion Models. We show that our method leads to remarkable attribution performance, even in the low-data regime, exceeding the performance of existing methods and generalizes better on images obtained from a diverse set of architectures. We make the code publicly available at: https://github.com/ciodar/UniversalAttribution.
Diffusion Based Augmentation for Captioning and Retrieval in Cultural Heritage
Aug 14, 2023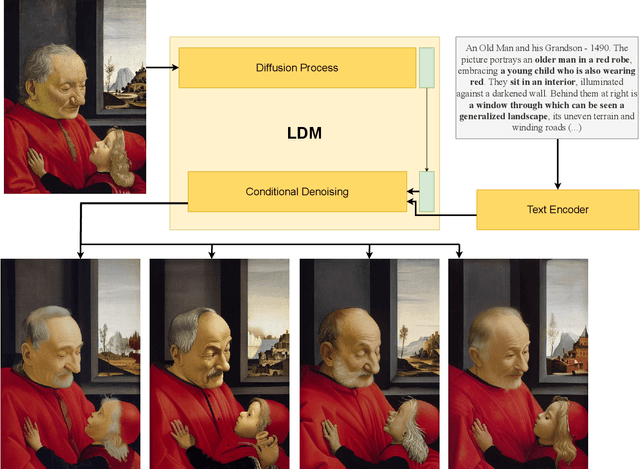
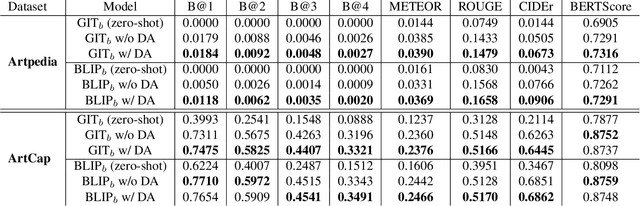
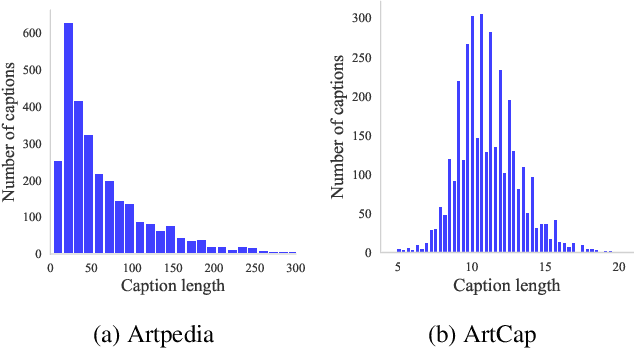

Cultural heritage applications and advanced machine learning models are creating a fruitful synergy to provide effective and accessible ways of interacting with artworks. Smart audio-guides, personalized art-related content and gamification approaches are just a few examples of how technology can be exploited to provide additional value to artists or exhibitions. Nonetheless, from a machine learning point of view, the amount of available artistic data is often not enough to train effective models. Off-the-shelf computer vision modules can still be exploited to some extent, yet a severe domain shift is present between art images and standard natural image datasets used to train such models. As a result, this can lead to degraded performance. This paper introduces a novel approach to address the challenges of limited annotated data and domain shifts in the cultural heritage domain. By leveraging generative vision-language models, we augment art datasets by generating diverse variations of artworks conditioned on their captions. This augmentation strategy enhances dataset diversity, bridging the gap between natural images and artworks, and improving the alignment of visual cues with knowledge from general-purpose datasets. The generated variations assist in training vision and language models with a deeper understanding of artistic characteristics and that are able to generate better captions with appropriate jargon.