 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposed Image Retrieval using Contrastive Learning and Task-oriented CLIP-based Features
Aug 22, 2023Given a query composed of a reference image and a relative caption, the Composed Image Retrieval goal is to retrieve images visually similar to the reference one that integrates the modifications expressed by the caption. Given that recent research has demonstrated the efficacy of large-scale vision and language pre-trained (VLP) models in various tasks, we rely on features from the OpenAI CLIP model to tackle the considered task. We initially perform a task-oriented fine-tuning of both CLIP encoders using the element-wise sum of visual and textual features. Then, in the second stage, we train a Combiner network that learns to combine the image-text features integrating the bimodal information and providing combined features used to perform the retrieval. We use contrastive learning in both stages of training. Starting from the bare CLIP features as a baseline, experimental results show that the task-oriented fine-tuning and the carefully crafted Combiner network are highly effective and outperform more complex state-of-the-art approaches on FashionIQ and CIRR, two popular and challenging datasets for composed image retrieval. Code and pre-trained models are available at https://github.com/ABaldrati/CLIP4Cir
Diffusion Based Augmentation for Captioning and Retrieval in Cultural Heritage
Aug 14, 2023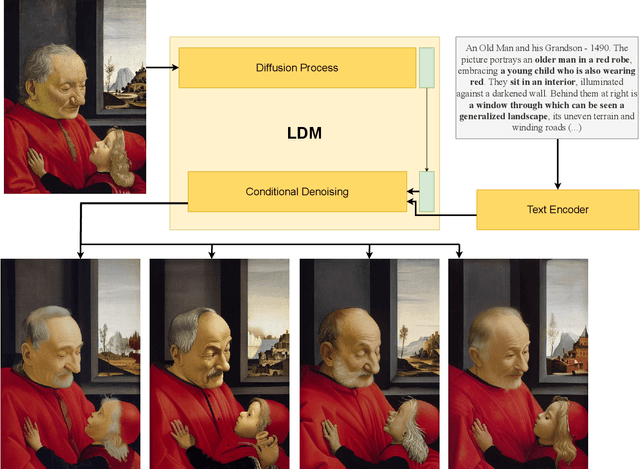
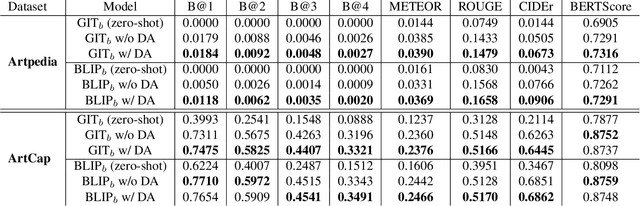
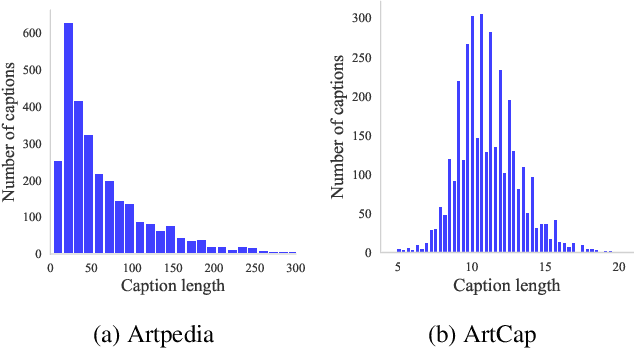

Cultural heritage applications and advanced machine learning models are creating a fruitful synergy to provide effective and accessible ways of interacting with artworks. Smart audio-guides, personalized art-related content and gamification approaches are just a few examples of how technology can be exploited to provide additional value to artists or exhibitions. Nonetheless, from a machine learning point of view, the amount of available artistic data is often not enough to train effective models. Off-the-shelf computer vision modules can still be exploited to some extent, yet a severe domain shift is present between art images and standard natural image datasets used to train such models. As a result, this can lead to degraded performance. This paper introduces a novel approach to address the challenges of limited annotated data and domain shifts in the cultural heritage domain. By leveraging generative vision-language models, we augment art datasets by generating diverse variations of artworks conditioned on their captions. This augmentation strategy enhances dataset diversity, bridging the gap between natural images and artworks, and improving the alignment of visual cues with knowledge from general-purpose datasets. The generated variations assist in training vision and language models with a deeper understanding of artistic characteristics and that are able to generate better captions with appropriate jargon.